Modelos de difusión para la generación de vídeo




Introducción
Los modelos de difusión se han ganado un lugar especial en el panorama de la generación de contenido visual con IA, destronando a las GAN y posicionándose como el enfoque de referencia a la hora de crear contenido realista. Como tecnologías como LoRas y Modelos de consistencia latente Cuando llegaron, estos modelos empezaron a ser menos restrictivos en términos de tiempo y recursos informáticos, y empezaron a surgir nuevas posibilidades y aplicaciones. Este es el caso de los modelos de generación de vídeo, un área que ha tenido un crecimiento exponencial en los últimos años. Cientos de artículos publicados en 2023 mostraron que el hito de producir vídeos de alta calidad de forma fiable está a la vuelta de la esquina. En este blog haremos un resumen técnico del uso de modelos de difusión para generar vídeos, no solo profundizando en un artículo en particular, sino profundizando en las decisiones arquitectónicas que toman los diferentes autores, generalizando y categorizando sus enfoques, pretendiendo que, después de esto, el lector pueda tener una idea general que le permita comprender soluciones específicas con mayor facilidad.
Solicitudes
Las aplicaciones del modelo de difusión de vídeo se pueden clasificar según sus modalidades de entrada, como texto, imágenes, audio o incluso otros vídeos. Algunos modelos también pueden usar una combinación de diferentes modalidades, como texto e imágenes. La generación de vídeo a vídeo también se puede dividir en finalización de vídeo, cuando la idea es añadir más fotogramas al vídeo existente, y edición de vídeo, cuando la tarea consiste en modificar los fotogramas existentes para añadir un estilo, color o cambiar un elemento.

Diferentes tipos de acondicionamiento [1]
Por lo general, los autores utilizan diferentes tipos de información simultáneamente, lo que permite un mayor control sobre la generación. Por ejemplo, artículos como Pose de ensueño [2], Anima a cualquiera [3] y Sigue tu postura [4] usa estimaciones de pose sobre un vídeo existente para condicionar la generación. De manera análoga, Generación 1 [5] y Crea tu vídeo [6] utilice estimaciones de profundidad en lugar de un vídeo original. McDiff [7] adopta un enfoque original, animando imágenes utilizando información de movimiento representada como trazos sobre la imagen. Por último, Control de vídeo [8] tiene la capacidad de usar diferentes tipos de controles como pose, profundidad, filtros astutos y más.
Arquitectura: a partir de imágenes
Empezaremos con algunos conocimientos comunes sobre los modelos de difusión aplicados a las imágenes. Este tema se abordó en nuestro blog anterior»Introducción a los modelos de difusión y la difusión estable», pero es importante refrescar algunos conceptos antes de profundizar en los modelos de vídeo. El proceso de generación de una imagen con un modelo de difusión implica una serie de pasos para eliminar el ruido a partir de una entrada ruidosa, condicionada a alguna otra fuente de información, como un mensaje de texto. El modelo más utilizado para este proceso de eliminación de ruido es una UNet. Esta red está entrenada para predecir la cantidad de ruido en la entrada, que se resta parcialmente en cada paso.
Arquitectura del modelo de difusión basada en la U-Net [9]
A continuación, se modifica la arquitectura de UNet y se agregan bloques VisionTransformer después de cada bloque de UNet. Esto tiene dos propósitos: en primer lugar, incorpora la autoatención espacial y comparte la información de toda la imagen. En segundo lugar, incorpora la atención cruzada, lo que condiciona el proceso de eliminación de ruido a la información orientativa, como las indicaciones de texto. El costo computacional de estos modelos es sustancial, por lo que para generar imágenes de alta resolución, los autores suelen aplicar técnicas como los modelos de difusión en cascada o los modelos de difusión latente, que describiremos a continuación.
Modelos de difusión en cascada
Los modelos de difusión en cascada constan de varios modelos de UNet que funcionan a resoluciones cada vez mayores. El resultado de una UNet de baja resolución se sobremuestrea y se envía como entrada a otra, lo que genera un resultado de mayor resolución. Este enfoque es el que adoptan los modelos que funcionan a nivel de píxeles, como Imagen [10], Imagen y vídeo [11], VDM [12] y Crea un vídeo [13]. El uso de los CDM ha desaparecido en gran medida tras la adaptación de los modelos de difusión latente que permiten la generación nativa de imágenes de alta fidelidad con recursos limitados.

Modelos en cascada de ImagenVideo [11]
Modelos de difusión latente
Los modelos de difusión latente aportan mejoras significativas a la arquitectura de UNet y se convirtieron en una de las principales soluciones a la hora de abordar los problemas de generación de imágenes y vídeos. La idea subyacente es convertir las entradas de un espacio RGB de alta resolución en una representación latente con una dimensionalidad espacial más baja y más canales de funciones.

Ilustración de un codificador automático propuesto por el artículo Stable Diffusion [14]
La estrategia clave es utilizar un codificador automático variacional (VAE) para la codificación de entrada inicial antes de la integración con la UNet. A continuación, el proceso de eliminación de ruido se ejecuta en ese espacio latente y, finalmente, el contenido latente eliminado se devuelve al espacio de píxeles con el decodificador VAE. Esto permite ahorrar una importante potencia computacional, lo que permite la generación de imágenes de mayor resolución en comparación con los modelos anteriores. Algunos ejemplos de este enfoque son Vídeo LDM [15], Generación 1 [5] y Segunda generación [16], SVD [17] y Anima a cualquiera [3]. Hasta ahora hemos explicado la arquitectura común de los modelos de difusión. En la siguiente sección profundizaremos en las modificaciones que permiten generar vídeos en lugar de imágenes.
Dar vida a las imágenes: añadir la dimensión temporal
Para extender la funcionalidad de los modelos de difusión de imágenes al vídeo es necesario disponer de un método para compartir información entre los distintos fotogramas del vídeo generado, o lo que es lo mismo, añadir una dimensión temporal a la información espacial hasta ahora incluida en el modelo de imagen. La entrada del modelo pasa entonces de una sola imagen de ruido a una para cada fotograma de la salida deseada, y los bloques ViT de la UNet se amplían con capas de atención temporal. Estas capas tienen la función de hacer que los parches de un fotograma se adapten a otros fotogramas y son responsables de la consistencia temporal de los vídeos generados.
Comparación de los mecanismos de atención
Hay diferentes formas de atender la consulta entre los fotogramas de estas capas, lo que da como resultado múltiples enfoques:
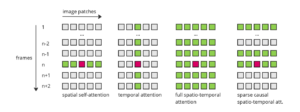
Ejemplos de diferentes enfoques de atención espacial y temporal [18]
Atención espacial: Como referencia, en este tipo de atención, la consulta de un parche específico atiende a todos los demás parches de la imagen. Atención temporal: En este caso, la consulta atiende a los parches que se encuentran en la misma ubicación en todos los demás marcos. Modelos como Vídeo LDM [15], Nuwa-XL [19] y Imagen y vídeo [11] (en su modelo de baja resolución) utilizan este tipo de capas. Atención espacio-temporal completa: Esta es la forma de atención más cara, ya que cada parche atiende a todos los demás parches en todos los demás marcos. Ofrece excelentes resultados, pero el coste computacional dificulta su aplicación en vídeos largos. Ejemplos de esto se encuentran en VDM [12] y Crea un vídeo [13]. Atención causal: Este enfoque es una optimización del anterior, intentando economizar recursos. Al igual que en la vida real, cada marco del presente puede utilizar información del pasado, pero no del futuro. De este modo, cada parche incluirá todos los parches de ese marco y todos los anteriores. Vídeo mágico [20] y Crea tu vídeo [6] adopte este enfoque. Escasa atención causal: Yendo más adelante, la escasa atención causal limita la cantidad de fotogramas anteriores que se tienen en cuenta. Por lo general, cada parche solo se ocupa de los demás parches de su marco, el inmediatamente anterior y el primer fotograma, lo que ahorra aún más recursos. Sintonizar un vídeo [21] y Renderizar un vídeo [22] utilice este método.
Lograr vídeos más largos
Incluso con los métodos de atención más baratos, la cantidad de fotogramas que puede generar un modelo es limitada. El hardware actual solo es capaz de generar unos segundos de vídeo en un solo lote. Los investigadores han estudiado varias formas de superar esta limitación y han surgido dos técnicas principales: el muestreo ascendente jerárquico y la extensión autorregresiva. La idea que subyace al muestreo jerárquico consiste en generar primero fotogramas espaciados y, a continuación, completar los huecos entre ellos generando más fotogramas, mediante una interpolación entre los fotogramas existentes o realizando pasadas adicionales del modelo de difusión. Algunos ejemplos de modelos que utilizan esta técnica son Crea un vídeo [13], Imagen y vídeo [11] y Nuwa-XL [19].

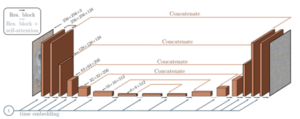
Ilustración del muestreo jerárquico de NUWA-XL [19]
Por otro lado, la extensión autorregresiva implica utilizar los últimos fotogramas de un vídeo generado para influir en la generación de fotogramas posteriores. Desde un punto de vista técnico, este enfoque permite la posibilidad de una extensión infinita de un vídeo. Sin embargo, en términos prácticos, los resultados suelen experimentar una mayor repetición y una disminución de la calidad a medida que se alarga la extensión. Esta técnica se aplica en modelos como VDM [12], LVDM [23] y Vídeo LDM [15].
Arquitecturas novedosas
Hay otros autores que llegaron con ideas novedosas que no encajan totalmente en ninguna de las categorías anteriores. Por ejemplo Luminaria [24] propuso cambios en la arquitectura de la UNet, con su Space-Time UNet. La idea subyacente es añadir submuestreos y submuestreos temporales, junto con los parámetros espaciales comunes que caracterizan a una UNet. De este modo, pueden comprimir la información tanto espacial como temporalmente, logrando, por un lado, una reducción de los costos computacionales y, por otro lado, una mejora en la consistencia temporal de los resultados.
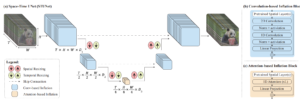
Lumiere Space-Time UNet [24]
Desafíos que abordar
El año pasado se produjo una impresionante cantidad de avances en el área de la generación de vídeo con IA, pero aún queda un largo camino por recorrer. En esta última sección resumiremos las principales dificultades a la hora de entrenar modelos de difusión de vídeo, que esperamos sean el centro de los nuevos avances de este año. La más obvia es la limitación de recursos de hardware. Por ejemplo, incluso las GPU más grandes de la actualidad solo pueden gestionar unos segundos de vídeo. Además, el entrenamiento de difusión es complejo y requiere una gran cantidad de datos y cientos de horas de GPU. Esto hace que la iteración sobre un modelo sea extremadamente difícil. La falta de datos de entrenamiento etiquetados también es un problema importante. Aunque hay muchos conjuntos de datos de imágenes etiquetadas con millones de puntos de datos, los conjuntos de datos de vídeo suelen ser mucho más pequeños. Una solución intermedia que han adoptado muchos autores consiste en entrenar primero con datos de imágenes etiquetadas y, después, con vídeos sin etiquetar sin supervisión, pero de esa forma puede resultar difícil capturar detalles más precisos del vídeo, como el movimiento específico de un objeto. En lo que respecta a la generación prolongada de vídeos, aún no se ha conseguido una forma fiable de modelar dependencias temporales prolongadas. Las técnicas autorregresivas y jerárquicas de sobremuestreo intentan ayudar en este sentido, pero pueden provocar artefactos y reducir la calidad con el tiempo. Esto puede mejorarse desde el punto de vista de la arquitectura. Con una mayor capacidad de procesamiento en el futuro, la adopción de una atención espacio-temporal completa en 3D para vídeos más largos podría capturar esas interacciones complejas. El ritmo al que se llevan a cabo los desarrollos no hace más que aumentar, y cada vez son más los autores que toman medidas importantes. El camino hacia la generación de vídeos largos y de alta calidad es difícil, pero solo es cuestión de tiempo que lo consigamos. Estamos muy entusiasmados por ver cuál será el próximo gran salto.
Referencias
- Una encuesta sobre los modelos de difusión de vídeo, Xing y otros (2023)
- DreamPose: síntesis de imagen a vídeo de moda a través de una difusión estable, Karras y otros (2023)
- Animate Anyone: síntesis uniforme y controlable de imagen a vídeo para la animación de personajes, Hu y otros (2023)
- Sigue tu postura: generación de texto a video guiada por poses usando videos sin poses, Ma y otros (2024)
- Síntesis de vídeo guiada por estructura y contenido con modelos de difusión, Esser y otros (2023)
- Crea tu vídeo: generación de vídeo personalizada mediante orientación textual y estructural, Xing y otros (2023)
- Modelo de difusión condicionado por movimiento para síntesis de vídeo controlable, Chen y otros (2023)
- ControlVideo: generación de texto a vídeo controlable y sin formación, Zhang y otros (2023)
- Una guía detallada para eliminar el ruido de los modelos probabilísticos de difusión: de la teoría a la implementación, Singh (2023)
- Modelos fotorrealistas de difusión de texto a imagen con un profundo conocimiento del lenguaje, Saharia y otros (2022)
- Imagen Video: Generación de vídeo de alta definición con modelos de difusión, Ho y otros (2022)
- Modelos de difusión de vídeo, Ho y otros (2022)
- Crear un vídeo: generación de texto a vídeo sin datos de texto y vídeo, Singer y otros (2022)
- ¡La difusión estable se explica claramente!, Steins (2023)
- Alinee sus latentes: síntesis de vídeo de alta resolución con modelos de difusión latente, Blattmann y otros (2023)
- Gen-2: el siguiente paso adelante para la IA generativa, Pasarela (2023)
- Difusión de vídeo estable: escalado de modelos de difusión de vídeo latentes a grandes conjuntos de datos, Blattmann y otros (2023)
- Modelos de difusión de vídeo: una encuesta (2023)
- NUWA-XL: Difusión en lugar de difusión para una generación de vídeo extremadamente larga, Yin y otros (2023)
- MagicVideo: generación eficiente de vídeo con modelos de difusión latente, Zhou y otros (2022)
- Tune-A-Video: ajuste en una sola toma de los modelos de difusión de imágenes para la generación de texto a video, Wu y otros (2023)
- Volver a renderizar un vídeo: traducción de vídeo a vídeo guiada por texto sin necesidad de hacer nada, Yang y otros (2023)
- Modelos de difusión de vídeo latente para la generación de vídeo largo de alta fidelidad, He y otros (2023)
- Lumiere: un modelo de difusión espacio-temporal para la generación de vídeo, Ber-Tal y otros (2024)



.png)