Modelos de difusão para geração de vídeo




Introdução
Os modelos de difusão conquistaram um lugar especial no cenário de geração de conteúdo visual de IA, destronando GANs e se posicionando como a abordagem preferida ao criar conteúdo realista. Como tecnologias como LoRAs e Modelos de consistência latente Quando chegaram, esses modelos começaram a ser menos restritivos em termos de tempo e recursos computacionais, e novas possibilidades e aplicações começaram a surgir. Foi o caso dos modelos de geração de vídeo, uma área que teve um crescimento exponencial nos últimos anos, com centenas de artigos em 2023 mostrando que o marco de produzir vídeos de alta qualidade de forma confiável está ao virar da esquina. Neste blog, faremos um resumo técnico do uso de modelos de difusão para gerar vídeos, não apenas mergulhando em um artigo específico, mas investigando as decisões arquitetônicas tomadas por diferentes autores, generalizando e categorizando suas abordagens, fingindo que, depois disso, o leitor poderá ter uma ideia geral que lhe permitirá entender soluções específicas com mais facilidade.
Aplicações
Os aplicativos de modelos de difusão de vídeo podem ser categorizados por suas modalidades de entrada, como texto, imagens, áudio ou até mesmo outros vídeos. Alguns modelos também podem usar uma combinação de diferentes modalidades, como texto e imagens. A geração de vídeo para vídeo também pode ser separada em conclusão de vídeo, quando a ideia é adicionar mais quadros ao vídeo existente, e edição de vídeo, quando a tarefa é modificar os quadros existentes para adicionar um estilo, cor ou alterar um elemento.

Diferentes tipos de condicionamento [1]
Normalmente, os autores usam diferentes tipos de informação simultaneamente, permitindo maior controle sobre a geração. Por exemplo, artigos como Pose dos sonhos [2], Anime qualquer pessoa [3] e Siga sua pose [4] use estimativas de pose em um vídeo existente para condicionar a geração. Analogamente, Geração 1 [5] e Faça seu vídeo [6] use estimativas de profundidade em um vídeo original. McDiff [7] adota uma abordagem original, animando imagens usando informações de movimento representadas como traços sobre a imagem. Por fim, Vídeo de controle [8] tem a capacidade de usar diferentes tipos de controles, como pose, profundidade, filtros inteligentes e muito mais.
Arquitetura: partindo de imagens
Começaremos com alguns conhecimentos comuns sobre modelos de difusão aplicados a imagens. Este tópico foi abordado em nosso blog anterior”Uma introdução aos modelos de difusão e difusão estável”, mas é importante atualizar alguns conceitos antes de se aprofundar nos modelos de vídeo. O processo de geração de uma imagem com um modelo de difusão envolve uma série de etapas de eliminação de ruído a partir de uma entrada ruidosa, condicionada a alguma outra fonte de informação, como um prompt de texto. O modelo mais usado para esse processo de eliminação de ruído é o UNet. Essa rede é treinada para prever a quantidade de ruído na entrada, que é subtraída parcialmente em cada etapa.
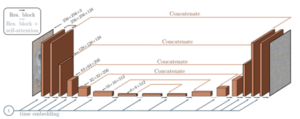
Arquitetura do modelo de difusão baseada na U-Net [9]
A arquitetura UNet é então modificada e os blocos VisionTransformer são adicionados após cada bloco UNet. Isso serve a dois propósitos: primeiro, incorpora a autoatenção espacial, compartilhando informações de toda a imagem. Em segundo lugar, ele incorpora atenção cruzada, condicionando o processo de eliminação de ruído à orientação de informações, como instruções de texto. O custo computacional desses modelos é substancial, portanto, para gerar imagens de alta resolução, os autores geralmente aplicam técnicas como modelos de difusão em cascata ou modelos de difusão latente, que descreveremos a seguir.
Modelos de difusão em cascata
Os modelos de difusão em cascata consistem em vários modelos UNet que operam em resoluções crescentes. O resultado de uma UNet de baixa resolução é ampliado e alimentado como entrada para outra, o que gera um resultado de maior resolução. Essa abordagem é a adotada por modelos que operam em nível de pixel, como Imagem [10], Imagem e vídeo [11], VDM [12] e Faça um vídeo [13]. O uso de CDMs praticamente desapareceu após a adaptação dos modelos de difusão latente que permitem a geração nativa de imagens de alta fidelidade com recursos limitados.

Modelos em cascata ImagenVideo [11]
Modelos de difusão latente
Os modelos de difusão latente trazem melhorias significativas à arquitetura da UNet e se tornaram uma das principais soluções ao lidar com problemas de geração de imagens e vídeos. A ideia por trás disso é converter as entradas de um espaço RGB de alta resolução em uma representação latente com menor dimensionalidade espacial e mais canais de recursos.

Ilustração de um autoencoder, conforme proposto pelo artigo Stable Diffusion [14]
Usar um codificador automático variacional (VAE) para codificação de entrada inicial antes da integração com a UNet é a estratégia principal. Em seguida, o processo de eliminação de ruído é executado nesse espaço latente e a latente eliminada é finalmente levada de volta ao espaço de pixels com o decodificador VAE. Isso permite economizar energia computacional significativa, possibilitando a geração de imagens de maior resolução em comparação com os modelos anteriores. Exemplos dessa abordagem são Vídeo LDM [15], Geração 1 [5] e Geração 2 [16], SVD [17] e Anime qualquer pessoa [3]. Até agora, explicamos a arquitetura comum dos modelos de difusão. Na próxima seção, mergulharemos nas modificações que possibilitam gerar vídeos em vez de imagens.
Dando vida às imagens: adicionando a dimensão temporal
Para estender a funcionalidade dos modelos de difusão de imagem ao vídeo, é necessário ter um método para compartilhar informações entre os diferentes quadros do vídeo gerado ou, o que é o mesmo, adicionar uma dimensão temporal às informações espaciais até agora incluídas no modelo de imagem. A entrada do modelo então passa de uma única imagem de ruído para uma para cada quadro na saída desejada, e os blocos ViT da UNet são estendidos com camadas de atenção temporal. Essas camadas têm a função de fazer com que os trechos de um quadro atendam a outros quadros e são responsáveis pela consistência temporal dos vídeos gerados.
Comparando mecanismos de atenção
Há diferentes maneiras de a consulta ocorrer entre os quadros nessas camadas, resultando em várias abordagens:
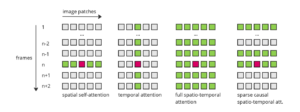
Exemplos de diferentes abordagens de atenção espacial e temporal [18]
Atenção espacial: Como referência, nesse tipo de atenção, a consulta em um patch específico atende a todos os outros patches na imagem. Atenção temporal: nesse caso, a consulta atende aos patches que estão no mesmo local em todos os outros quadros. Modelos como Vídeo LDM [15], Nuwa-XL [19] e Imagem e vídeo [11] (em seu modelo de baixa resolução) use esse tipo de camada. Atenção espaço-temporal total: Essa é a forma de atenção mais econômica, pois cada patch atende a todos os outros patches em todos os outros quadros. Ele tem ótimos resultados, mas o custo computacional dificulta sua aplicação em vídeos longos. Exemplos disso estão em VDM [12] e Faça um vídeo [13]. Atenção causal: Essa abordagem é uma otimização da anterior, tentando economizar recursos. Assim como na vida real, cada quadro atual pode usar informações do passado, mas não do futuro. Dessa forma, cada patch atenderá a cada patch desse quadro e a todos os anteriores. Vídeo mágico [20] e Faça seu vídeo [6] adote essa abordagem. Atenção causal esparsa: Indo mais adiante, a atenção causal esparsa limita a quantidade de quadros anteriores levados em consideração. Normalmente, cada patch atende somente aos outros patches em seu quadro, o imediatamente anterior e o primeiro quadro, economizando ainda mais recursos. Sintonize um vídeo [21] e Renderizar um vídeo [22] use esse método.
Obtendo vídeos mais longos
Mesmo com o método de atenção mais barato, o número de quadros que um modelo pode gerar é limitado. O hardware atual só é capaz de gerar alguns segundos de vídeo em um único lote. Os pesquisadores estudaram várias maneiras de superar essa limitação e surgiram duas técnicas principais: aumento da amostragem hierárquica e extensão autorregressiva. A ideia por trás da ampliação hierárquica é primeiro gerar quadros espaçados e, em seguida, preencher as lacunas entre eles, gerando mais, usando uma interpolação entre os quadros existentes ou fazendo passagens adicionais do modelo de difusão. Exemplos de modelos que usam essa técnica são Faça um vídeo [13], Imagem e vídeo [11] e Nuwa-XL [19].

Aumento da resolução hierárquica NUWA-XL ilustrado [19]
Por outro lado, a extensão autorregressiva envolve a utilização dos últimos quadros de um vídeo gerado para influenciar a geração de quadros subsequentes. Do ponto de vista técnico, essa abordagem permite a possibilidade de uma extensão infinita de um vídeo. No entanto, em termos práticos, os resultados geralmente apresentam maior repetição e declínio na qualidade à medida que a extensão aumenta. Essa técnica é aplicada em modelos como VDM [12], LVDM [23] e Vídeo LDM [15].
Arquiteturas inovadoras
Existem outros autores que apresentaram ideias inovadoras que não se encaixam totalmente em nenhuma das categorias anteriores. Por exemplo Iluminação [24] propôs mudanças na arquitetura UNet, com seu Space-Time UNet. A ideia por trás disso é adicionar reduções e ampliações temporais, junto com as espaciais comuns que caracterizam uma UNet. Ao fazer isso, eles são capazes de compactar as informações espacial e temporalmente, alcançando, por um lado, uma redução nos custos computacionais e, por outro lado, uma melhoria na consistência temporal dos resultados.
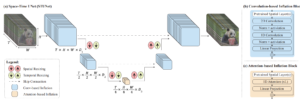
Lumiere Espaço-Tempo UNet [24]
Desafios a serem enfrentados
O ano passado veio com uma quantidade impressionante de desenvolvimentos na área de geração de vídeo com IA, mas ainda há um longo caminho a percorrer. Nesta última seção, resumiremos as principais dificuldades no treinamento de modelos de difusão de vídeo, que, esperançosamente, serão o foco de novos avanços este ano. A mais óbvia é a limitação de recursos de hardware. Por exemplo, até mesmo as maiores GPUs atuais suportam apenas alguns segundos de vídeo. Além disso, o treinamento de difusão é complexo e exige muitos dados e centenas de horas de GPU. Isso torna a iteração sobre um modelo extremamente desafiadora. A falta de dados de treinamento rotulados também é um problema significativo. Embora existam muitos conjuntos de dados de imagens rotulados com milhões de pontos de dados, os conjuntos de dados de vídeo geralmente são muito menores. Uma solução intermediária adotada por muitos autores é treinar primeiro com dados de imagens rotuladas e depois treinar com vídeos não rotulados de maneira não supervisionada, mas dessa forma pode ser difícil capturar detalhes mais precisos do vídeo, como movimentos específicos do objeto. Em relação à geração de vídeos longos, ainda não foi alcançada uma forma confiável de modelar dependências temporais longas. Técnicas de aumento de amostragem autorregressiva e hierárquica tentam ajudar nisso, mas podem levar a artefatos e sofrer degradação da qualidade ao longo do tempo. Isso pode ser melhorado do lado da arquitetura. Com mais poder de processamento no futuro, a adoção de atenção espaço-temporal 3D completa para vídeos mais longos pode ser capaz de capturar essas interações complexas. O ritmo em que os desenvolvimentos são feitos está apenas aumentando, com mais e mais autores dando passos significativos. O caminho para a geração de vídeos longos de alta qualidade é difícil, mas é apenas uma questão de tempo até chegarmos lá. Estamos muito animados para ver qual será o próximo grande salto.
Referências
- Uma pesquisa sobre modelos de difusão de vídeo, Xing et al. (2023)
- DreamPose: síntese de imagem para vídeo de moda via difusão estável, Karras et al. (2023)
- Animate Anyone: síntese consistente e controlável de imagem em vídeo para animação de personagens, Hu et al. (2023)
- Siga sua pose: geração de texto para vídeo guiada por pose usando vídeos sem pose, Ma et al. (2024)
- Síntese de vídeo guiada por estrutura e conteúdo com modelos de difusão, Esser et al. (2023)
- Faça seu vídeo: geração de vídeo personalizada usando orientação textual e estrutural, Xing et al. (2023)
- Modelo de difusão condicionado por movimento para síntese de vídeo controlável, Chen et al. (2023)
- ControlVideo: Geração controlável de texto para vídeo sem treinamento, Zhang et al. (2023)
- Um guia detalhado para eliminar o ruído de modelos probabilísticos de difusão — da teoria à implementação, Singh (2023)
- Modelos fotorrealistas de difusão de texto para imagem com profundo entendimento da linguagem, Saharia et al. (2022)
- Imagen Video: Geração de vídeo de alta definição com modelos de difusão, Ho et al. (2022)
- Modelos de difusão de vídeo, Ho et al. (2022)
- Faça um vídeo: geração de texto para vídeo sem dados de texto e vídeo, Singer et al. (2022)
- Difusão estável claramente explicada!, Steins (2023)
- Alinhe suas latentes: síntese de vídeo de alta resolução com modelos de difusão latente, Blattmann et al. (2023)
- Gen-2: o próximo passo para a IA generativa, Pista de decolagem (2023)
- Difusão de vídeo estável: escalando modelos de difusão de vídeo latente para grandes conjuntos de dados, Blattmann et al. (2023)
- Modelos de difusão de vídeo - uma pesquisa (2023)
- NUWA-XL: Difusão sobre difusão para geração de vídeo extremamente longa, Yin et al. (2023)
- MagicVideo: Geração eficiente de vídeo com modelos de difusão latente, Zhou et al. (2022)
- Tune-A-Video: ajuste único de modelos de difusão de imagem para geração de texto para vídeo, Wu et al. (2023)
- Renderize um vídeo: tradução de vídeo para vídeo guiada por texto Zero-Shot, Yang et al. (2023)
- Modelos de difusão de vídeo latente para geração de vídeo longo de alta fidelidade, He et al. (2023)
- Lumiere: um modelo de difusão espaço-temporal para geração de vídeo, Ber-Tal et al. (2024)



.png)