.png)
Conceptos específicos de los modelos de difusión de la enseñanza




1. Introducción
1.1 Motivación
¿Alguna vez te has encontrado buscando incansablemente en Internet esa imagen que transmita perfectamente tu visión creativa, solo para quedarte corta? Quizás eres un creador de contenido que busca imágenes que se adapten perfectamente a tus ideas. Pero pasar horas navegando por la web no produce más que frustración. Imagina un escenario en el que la imagen que imaginas no existe o crearla desde cero parece una tarea que requiere mucho tiempo. Introduzca los modelos de difusión y su diversa gama de variaciones como sus aliados creativos. Estos modelos te permiten crear composiciones asombrosas que pueden capturar la esencia de tu visión. ¿La mejor parte? Lograr esto no requiere navegar por procesos complejos. Con solo unas simples instrucciones de texto y una interfaz intuitiva y fácil de usar, puede hacer que su imagen ideal cobre vida. Como ejemplo, observe la siguiente imagen:

Una imagen de una persona buscando imágenes de Internet, creada usando
1.2 Introducción a la difusión estable
Stable Diffusion (SD) se capacitó en ALIÓN-5B. LAION es un conjunto de datos de 5.850 millones de pares de imágenes y texto filtrados por Clip de una amplia variedad de fenómenos visuales. De estos, 2,3 millones están escritos en inglés y 2,2 millones de ejemplos están escritos en una amplia gama de más de 100 idiomas. También hay mil millones de ejemplos que contienen textos que no permiten asignar un idioma determinado (por ejemplo, nombres de personajes famosos). Esto permite al modelo captar diversos conceptos visuales utilizando varios idiomas y recordar lugares emblemáticos y personas. Los modelos de difusión se destacan en la generación de imágenes para diversos fines. De ahí la importancia de comprender alternativas como el ajuste para mejorar el rendimiento en conceptos específicos. En nuestro blog anterior [2], exploramos los fundamentos de los modelos de difusión, su funcionamiento interno y las increíbles posibilidades que ofrecen. También presentamos Stable Diffusion, conocida por sus capacidades de orientación sin clasificadores. Pero lo que es más importante, la mejora de la eficiencia, el entrenamiento acelerado y la aceleración de la inferencia gracias a su enfoque de espacio latente. Ahora es el momento de profundizar en el ámbito de los modelos de difusión. Nuestro objetivo es descubrir cómo podemos aprovechar estos extraordinarios modelos para enseñarles conceptos específicos mediante ajustes precisos y, al mismo tiempo, mantener el control sobre los resultados generados para alinearlos perfectamente con nuestra visión única.
2. Métodos
Cuando se trata de enseñar a los modelos de difusión a comprender un concepto específico, como un objeto o un estilo en particular, hay cuatro métodos principales a nuestra disposición:
- Cabina de ensueño
- Inversión textual
- Adaptación de rango bajo (LoRa)
- Hiperredes
Hay algunas alternativas más, como las incrustaciones estéticas. Sin embargo, en este artículo nos centraremos en estas cuatro, ya que otras técnicas aún necesitan algunas mejoras para proporcionar imágenes con una calidad comparable a la de las otras alternativas. A lo largo de nuestra descripción general de estos métodos, analizaremos su funcionamiento interno, sus puntos fuertes y sus posibles ventajas y desventajas. En aras de la simplicidad, consideremos un caso práctico en el que nuestro objetivo es generar nuevas imágenes de un concepto específico únicamente a través de indicaciones, sin depender de fuentes de entrada adicionales, aunque estas entradas adicionales se analizarán más adelante en la sección de ControlNet [3].
2.1 DreamBooth
2.1.1 ¿Cómo funciona?
DreamBooth, tal como se propone en «DreamBooth: ajuste fino de los modelos de difusión de texto a imagen para una generación basada en el sujeto» [4], Ruiz et. al (2023), trabaja alterando los parámetros del propio modelo de difusión (mediante un ajuste fino) hasta que comprenda el nuevo concepto. Para enseñar a los modelos de difusión un nuevo concepto, como generar imágenes de tu propio gato, reúne imágenes de referencia para este concepto y utiliza un identificador único, que no se ve durante el entrenamiento, conocido como el token SKS. El token SKS ayuda al modelo a asociar este nuevo token con el concepto visual cada vez que aparece en el mensaje. En cuanto a la incrustación de texto en el modelo SD, DreamBooth no altera la codificación del nuevo token, sino que asocia esta incrustación con el nuevo concepto de las imágenes.
2.1.2 Interacción de los componentes principales
En aras de la simplicidad, consideremos un ajuste fino que consiste en una sola imagen, aunque los autores se refieren al uso de 3 a 5 imágenes en unos pocos lotes.

Diagrama que representa el proceso de entrenamiento con DreamBooth para una sola imagen.
Tomamos una imagen que contiene el nuevo concepto (x0) y, a continuación, aplicar t pasos de ruido para crear una imagen de entrada ruidosa para el modelo (xt) y pasa esta imagen ruidosa a través del modelo de difusión para predecir el ruido presente en la imagen. La comparación entre la predicción del ruido y el ruido real agregado a la imagen original se usa para calcular la función de pérdida, calcular los gradientes y, a continuación, actualizar los parámetros del modelo de difusión. La entrada al modelo de difusión consiste en la imagen ruidosa, el intervalo temporal muestreado t y el mensaje que representa el nuevo concepto, como: «Una imagen de un gato SKS». Es posible que la incrustación textual SKS no se refiera a un concepto ya conocido. Por lo tanto, el modelo de difusión probablemente haría un trabajo bastante malo a la hora de eliminar el ruido de la imagen las primeras veces. Sin embargo, esto acabará desembocando en un modelo que comprenda el concepto que estamos intentando enseñar, utilizando tanto imágenes del concepto como el símbolo SKS dentro de la línea de texto. Nota: una diferencia importante entre ajustar una U-Net a partir de un modelo de difusión estable es que el proceso de generación de ruido y eliminación de ruido en SD se mantiene en el espacio latente, por lo que la imagen no está dañada como se muestra en el diagrama anterior. Si quieres leer más sobre este enfoque del espacio latente, puedes echar un vistazo a nuestra blog anterior [2].

Un ejemplo de las imágenes de entrada y las inferencias de un concepto enseñado (un Corgi específico) en diversos contextos, tal como se presenta en Página web oficial de DreamBooth [5].
2.1.3 Conclusiones principales
Esta es probablemente la forma más eficaz de enseñar un nuevo concepto, adaptando toda la red a su caso de uso específico. Sin embargo, tiene un coste: es posible que la red pierda eficacia a la hora de generar imágenes en general. Además, es posible que no sea adecuado para enseñar varios conceptos simultáneamente, ya que a menudo produce resultados insatisfactorios. Ajustar los diferentes modelos de difusión para cada concepto es una opción. Sin embargo, requiere más memoria de disco y recursos computacionales, incluidas GPU y RAM.
2.2 Inversión textual
2.2.1 ¿Cómo funciona?
La inversión textual es una técnica propuesta en «Una imagen vale más que una palabra: personalización de la generación de texto a imagen mediante la inversión textual» [6] de Gal y otros (2022). La configuración de Textual Inversion es básicamente idéntica a la de DreamBooth, pero con algunos ajustes. En lugar de actualizar los gradientes del modelo como penalización cuando hay una predicción incorrecta del ruido añadido a la imagen de entrada, actualiza el vector de incrustación SKS. Mientras tanto, el modelo de difusión permanece congelado y sin cambios. El propósito de esto es crear la incrustación adecuada para el token SKS que logre identificar los fenómenos visuales (concepto) que estamos intentando enseñar al modelo, en lugar de actualizar el modelo en sí mismo para generar imágenes de un concepto determinado con una incrustación fija de un token que no tiene ningún significado.
2.2.2 Interacción de los componentes principales
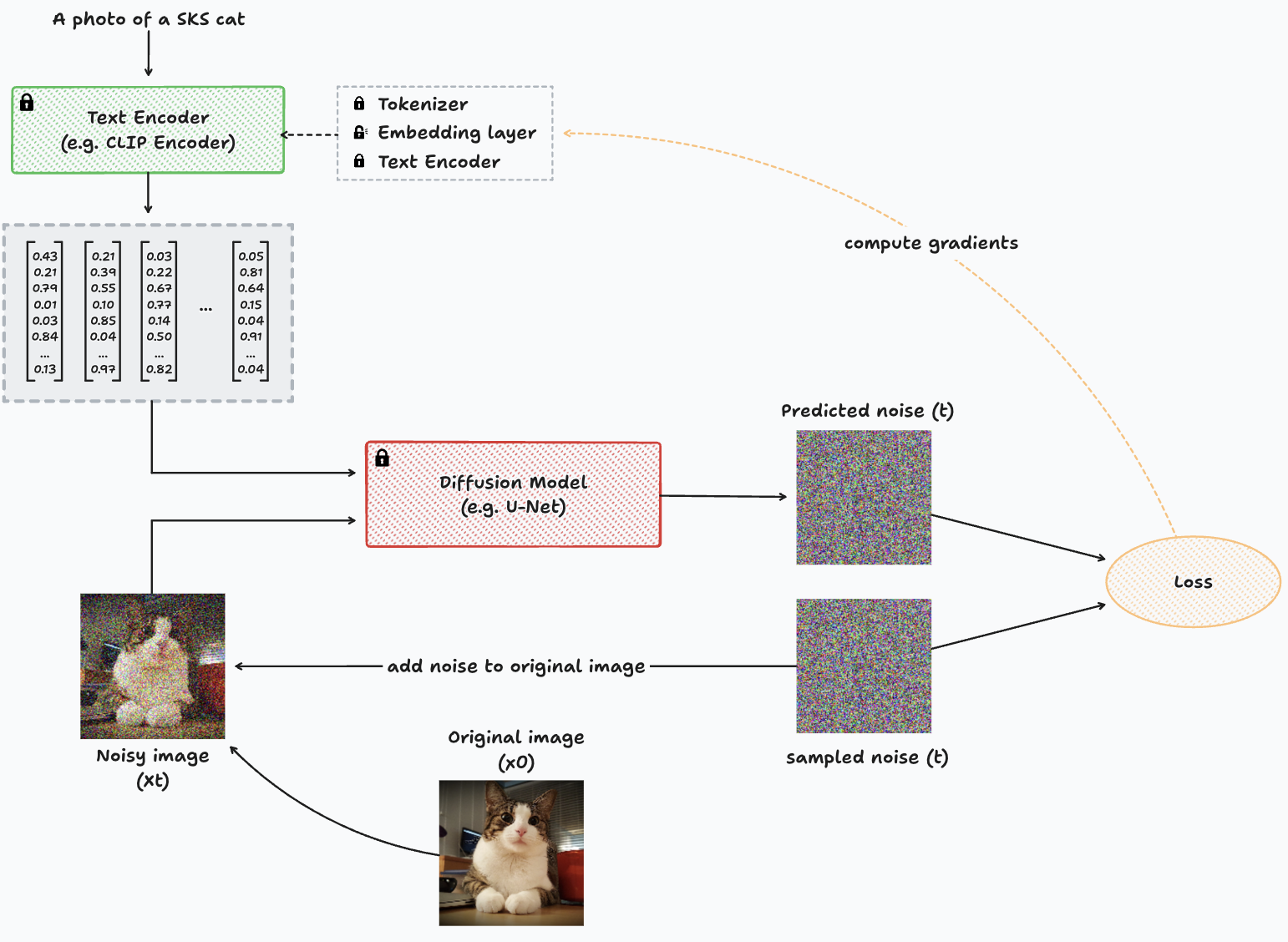
Diagrama que representa el proceso de entrenamiento con inversión textual para una sola imagen.
En este diagrama, observamos esencialmente la misma estructura que en DreamBooth. Sin embargo, una diferencia clave radica en el hecho de que el modelo de difusión está congelado (no se puede entrenar, como indica el icono del candado) y el cálculo de los gradientes se dirige hacia el codificador de texto. El codificador de texto que se muestra en el diagrama es una representación simplificada del proceso subyacente. La codificación de texto incluye dos componentes principales: el tokenizador y el propio codificador de texto. El tokenizador funciona como un diccionario responsable de asignar cada token conocido a un identificador numérico. Este mapeo es crucial, ya que los modelos de aprendizaje profundo aprenden exclusivamente de las representaciones numéricas de los datos.
2.2.3 El codificador de texto
El primero convierte cada identificador de palabras dado por el tokenizador en una incrustación que representa vagamente cada palabra en un determinado espacio dimensional inferior. Mientras que el segundo toma este conjunto de incrustaciones vagas generadas por la capa de incrustación y las pasa a través de un codificador de texto transformador. La salida final es una representación vectorial de todo el mensaje de texto dado como entrada.

Diagrama que representa los componentes del codificador de texto dentro del entrenamiento de la inversión textual para una sola imagen.
Para lograrlo, agregamos el nuevo token al vocabulario del tokenizador e inicializamos su incrustación en la capa de incrustación. Esta inicialización puede ser aleatoria. Sin embargo, un enfoque más inteligente implica inicializar el nuevo concepto con una palabra que represente algo similar, aunque no idéntico. Piense en ello como tratar de entender cómo se ve un Corgi, partiendo del concepto de cómo se ve un perro. Puede parecer contradictorio que podamos enseñarle un concepto al modelo encontrando la incrustación textual correcta, sin necesidad de ajustar el modelo en sí. Sin embargo, en la práctica, funciona bien. Los modelos SD poseen una comprensión matizada de los fenómenos visuales. Esto permite que el uso de la incrustación perfecta permita crear fenómenos visuales arbitrarios que aún tengan sentido para los humanos. Los autores afirman que «el espacio de incrustación es lo suficientemente expresivo como para capturar la semántica básica de la imagen». Otra forma de interpretar esto es que podríamos representar cualquier concepto simplemente escribiendo el mensaje correcto. Aunque hay algunos conceptos que son extremadamente difíciles de expresar con palabras, de ahí la necesidad de una forma automatizada de aprender esta representación incrustada.
2.2.4 Conclusiones principales
Una de las mayores ventajas de la inversión textual es que el artefacto que guardamos es más pequeño que el de DreamBooth. Con DreamBooth necesitamos guardar todo el nuevo y perfeccionado modelo. Por otro lado, con la inversión textual podemos simplemente guardar la incrustación del token SKS. Esto también puede derivar en varios conceptos nuevos, ya que deberían ser diferentes incrustaciones de texto que estén siendo utilizadas exactamente por el mismo modelo.
2.3 Adaptación de rango bajo (LoRa)
2.3.1 ¿Cómo funciona?
El enfoque de adaptación de bajo rango (LoRa) surgió inicialmente para los modelos de lenguaje grande (LLM) en el documento «LoRa: adaptación de bajo rango de modelos lingüísticos de gran tamaño» [7], Hu y otros (2021). Esta propuesta tiene como objetivo abordar desafíos similares a los de DreamBooth, donde para instruir al modelo sobre múltiples conceptos específicos se requerían numerosas réplicas del modelo, lo que demuestra su ineficacia e impracticabilidad. Para el modelo Diffusion, solemos utilizar un modelo que introduce y emite imágenes del mismo tamaño. Esta es una de las razones de la popularidad de la U-Net para estos modelos. La idea detrás de LoRa es insertar nuevas capas diminutas que se puedan entrenar, llamadas Capas LoRa, en el modelo de tal manera que no afecten en absoluto a los parámetros del modelo y, al mismo tiempo, mantengan congelado el modelo original. Al principio, estas capas de LoRa generarán una salida idéntica a la de entrada, replicando el mismo comportamiento del modelo Diffusion congelado. Sin embargo, el cálculo de los gradientes acabará modificándolos, ajustando sus parámetros. Este proceso altera la entrada a las capas intermedias dentro del modelo Diffusion congelado, guiando a la generación hacia el nuevo concepto deseado.
2.3.2 Interacción de los componentes principales

Diagrama que representa el proceso de entrenamiento con LoRa para una sola imagen.
Como se puede ver en el diagrama anterior, el modelo de difusión está congelado y no se puede entrenar durante todo el proceso. Los pesos de LoRa son los que están sujetos a actualizaciones mediante el cálculo de gradientes. Pero, ¿cómo funcionan las capas de LoRa? Normalmente incorporamos estas capas en los bloques de atención de la U-Net. Estas capas toman la misma entrada, realizan una multiplicación de matrices adicional y suman el resultado a la salida de atención previamente entrenada.

Un diagrama que ilustra la disposición de las capas de LoRa dentro de los bloques de atención de la U-Net.
Otra pregunta es, ¿por qué necesitamos estas nuevas capas y no solo actualizar los pesos de atención congelados? Una de las principales ventajas de las capas LoRa es la cantidad reducida de parámetros que utilizan. El»Rango bajo«término se refiere a esto. En lugar de tener una matriz de dimensiones m x n, establecemos una multiplicación de dos matrices ERA y WB de dimensiones m x k y k x n respectivamente. Si contamos la cantidad de parámetros necesarios para cada enfoque, con el primer enfoque almacenamos 2 millones de valores, mientras que con el segundo (LoRa) almacenamos 6000 valores (ERA almacena 2000 valores y WB almacena 4000 valores).
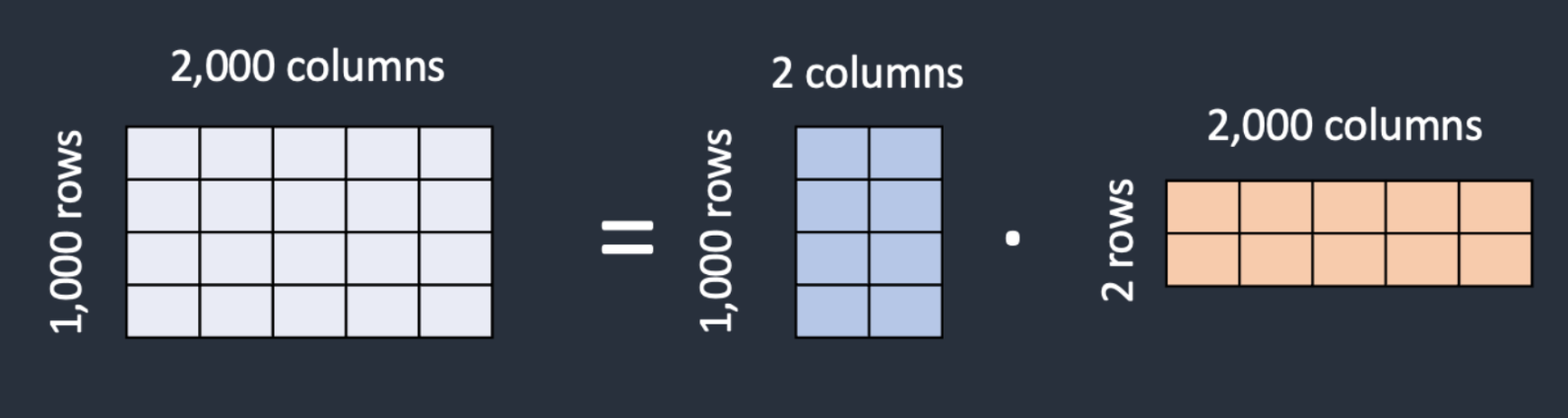
Representación matricial de la descomposición matricial con adaptación de rango bajo (LoRa).
2.3.3 Conclusiones principales
El entrenamiento con LoRa es mucho más rápido y requiere menos memoria que ajustar todo el modelo Stable Diffusion con DreamBooth. Además, las capas de LoRa son considerablemente más pequeñas que las del propio modelo SD, lo que las hace mucho más fáciles de almacenar y compartir en comparación con el modelo completo.
2.4 Hiperredes
2.4.1 ¿Cómo funciona?
Las hiperredes funcionan de manera bastante similar a LoRa, pero en lugar de agregar estas capas intermedias a los modelos SD, tenemos un modelo separado: denominada HyperNetwork - que está entrenado para crear algunas matrices que modifican ligeramente los valores de los mapas de características dentro del modelo Diffusion, de modo que aprenda a generar el concepto deseado. No hay ningún documento oficial sobre este tipo de redes; sin embargo, hay varios artículos que presentan esta forma de ajustar un modelo SD, y probablemente uno de los más populares sea ControlNet, tal y como se propone en «Agregar control condicional a los modelos de difusión de texto a imagen» [3], de Zhang y Agrawala (2023). A pesar de presentar otras características innovadoras, que se analizarán en breve, ControlNet todavía se clasifica como una hiperred.
2.4.2 Interacción de los componentes principales
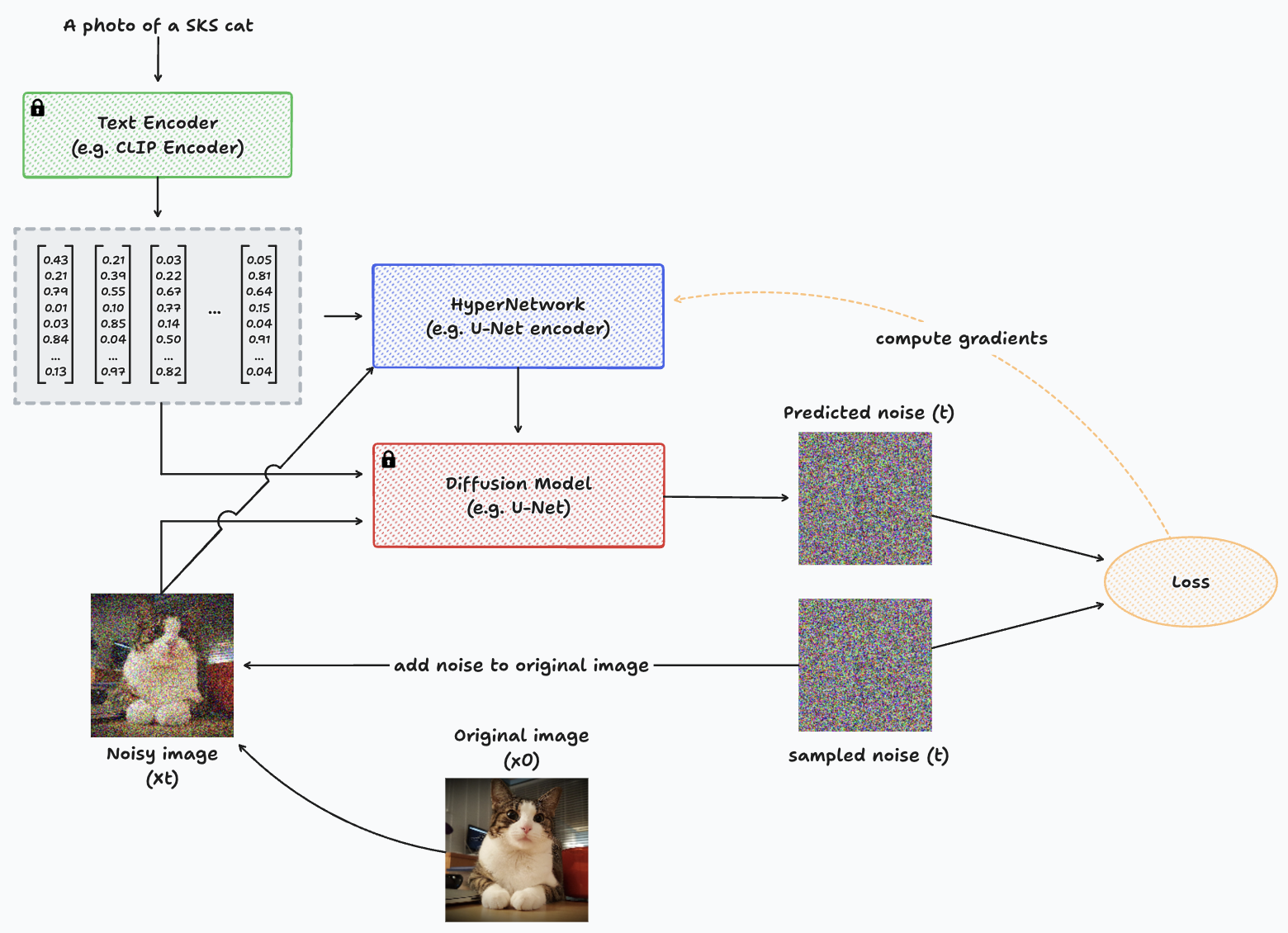
Diagrama que representa el proceso de entrenamiento con HyperNetworks para una sola imagen.
Para diseñar la arquitectura de HyperNetwork de forma sencilla, podemos simplemente replicar los bloques de codificación de la U-Net, junto con su cuello de botella. Luego, conecta estos bloques a los bloques descodificadores del modelo Diffusion. En esencia, se parece a tener dos codificadores U-Net distintos y un solo decodificador. Un codificador y el decodificador tienen parámetros inactivos (del modelo Diffusion previamente entrenado), mientras que el nuevo codificador ajusta ligeramente la entrada y la añade a las capas del decodificador para guiar la generación hacia el nuevo concepto.
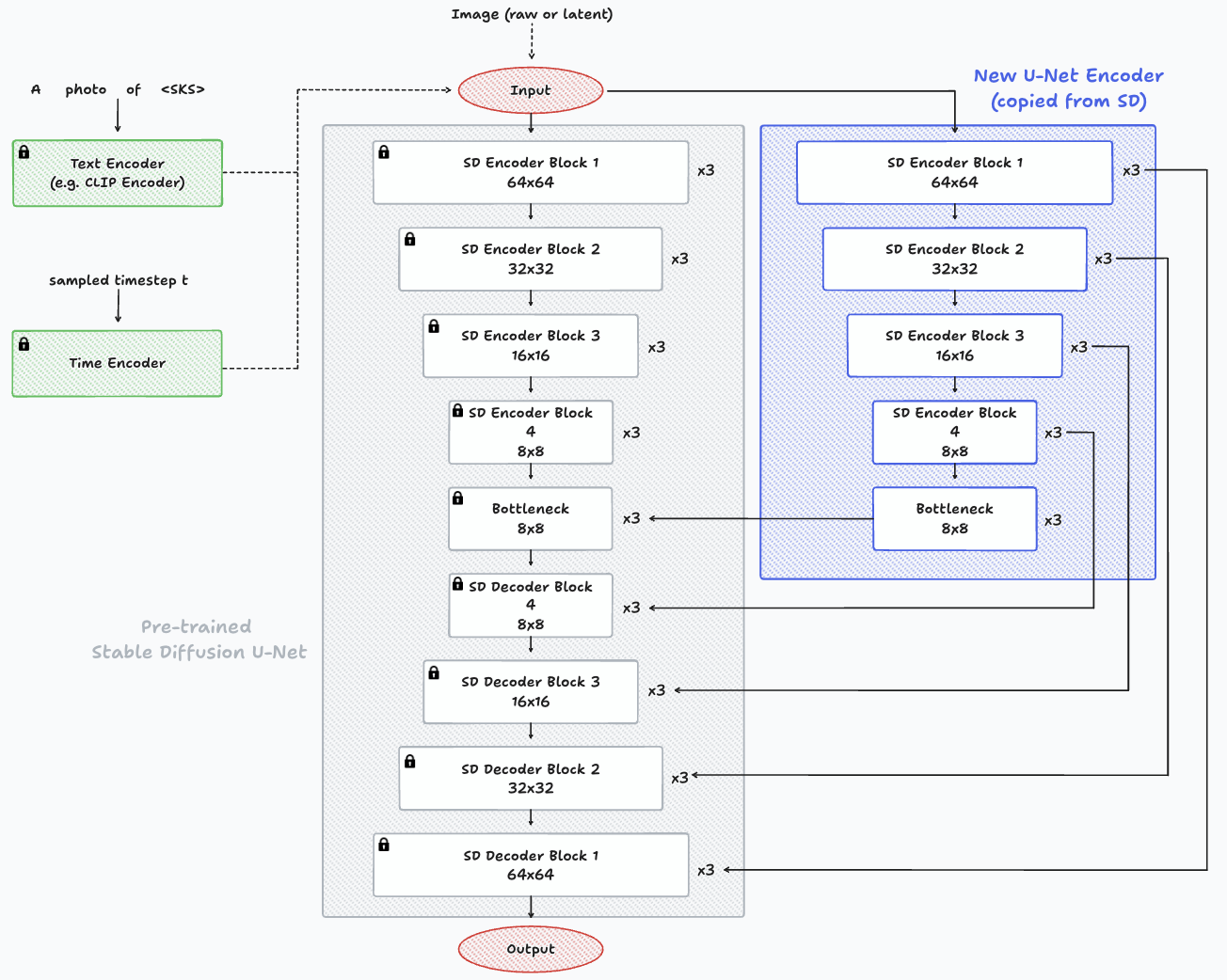
Ejemplo de arquitectura de una hiperred y su conexión con el modelo Diffusion. En el centro, en gris, podemos ver el codificador, el cuello de botella y el decodificador del modelo Stable Diffusion, previamente entrenado, con los parámetros inmovilizados. A la derecha, resaltado en azul, se ve el nuevo codificador (HyperNetwork), con capas copiadas idénticas que se conectan con las capas del decodificador del modelo Diffusion preentrenado.
2.4.3 Conclusiones principales
Este enfoque aún no ha arrojado resultados empíricos comparables a las técnicas mencionadas anteriormente. Sin embargo, HyperNetworks ganó mucha atención con el lanzamiento de ControlNet, una arquitectura de la que hablaremos más adelante. Estas redes tienen más parámetros que se pueden entrenar en comparación con la inversión textual y LoRa. Teóricamente, esto podría significar que podrían aprender patrones más complejos, pero no tener que ajustar todo el modelo de difusión estable como ocurre con DreamBooth.
2.5 ControlNet
2.5.1 ¿Cómo funciona?
A pesar de que presentamos ControlNet [3] como caso particular de HyperNetworks, nos interesa presentar los principales avances que implica, ya que se propuso como una arquitectura de red neuronal de extremo a extremo capaz de controlar modelos de difusión de imágenes grandes (como Stable Diffusion) para aprender las condiciones de entrada específicas de las tareas.
2.5.2 Interacción de los componentes principales
ControlNet clona los pesos de un modelo de difusión grande en un copia entrenable y un copia bloqueada. La copia bloqueada mantiene la capacidad de red adquirida a partir de miles de millones de imágenes durante el entrenamiento previo. Al mismo tiempo, la copia que se puede entrenar se entrena con conjuntos de datos específicos de cada tarea para adquirir el control condicional, lo que permite establecer un vínculo directo con la arquitectura presentada en las HyperNetworks, pero con algunos ajustes.
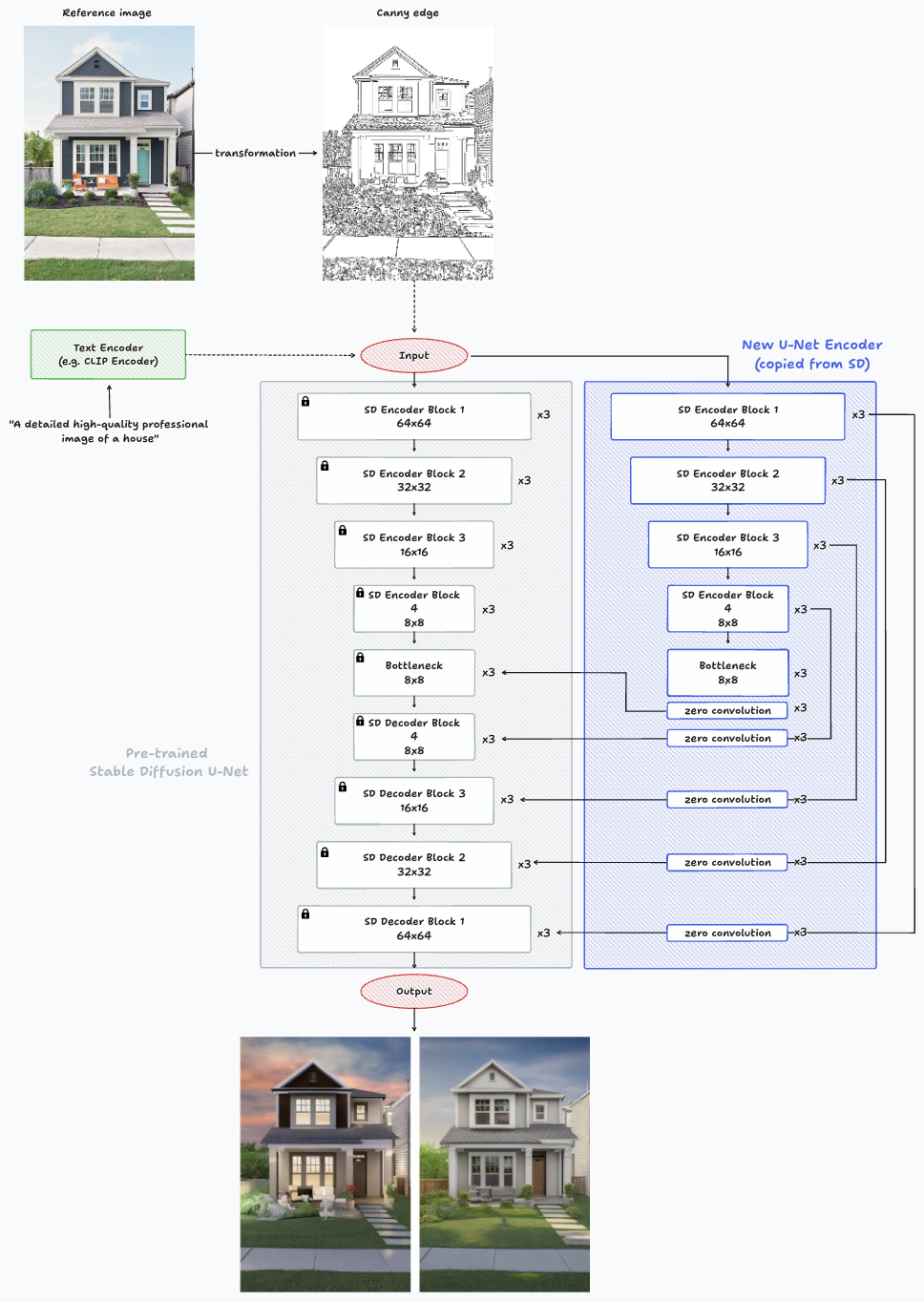
Arquitectura de ControlNet mientras se hace una inferencia en una sola imagen con Canny Edge.
Los cambios más notables con respecto a la arquitectura que se muestra en HyperNetworks son la adición de capas de convolución cero después de los bloques del nuevo codificador y antes de entrar en el decodificador Stable Diffusion, y la capacidad de guiar la generación de imágenes con una nueva entrada como la que se muestra en Canny Edge. La red neuronal entrenable se conecta a la red neuronal bloqueada a través de una capa de convolución distintiva conocida como «convolución cero». Esta capa ajusta gradualmente sus pesos de convolución, pasando de los ceros a los parámetros optimizados de una manera aprendida. La conservación de los pesos listos para la producción mejora la solidez del entrenamiento en conjuntos de datos de diferentes escalas.
2.5.3 Mecanismos de acondicionamiento
Algunos de los acondicionamientos más comunes que se utilizan en ControlNet son, entre otros:
- Arista astuta: detección de bordes suavizando la imagen con filtros gaussianos, eliminando el ruido con un núcleo gaussiano discreto e identificando las áreas de la imagen con los gradientes de intensidad más fuertes.
- Mapa de profundidad: se refiere a una imagen o canal que contiene información relacionada con la distancia de las superficies de los objetos presentes en una escena desde un punto de vista determinado.
- CABEZA: intenta abordar las limitaciones del detector de bordes Canny a través de una red neuronal profunda de extremo a extremo.
- Mapeo normal: es una técnica de mapeo de texturas que se utiliza para simular la iluminación de protuberancias y abolladuras, mejorando la apariencia y los detalles de un modelo de polígonos bajos al generar un mapa normal a partir de un modelo de polígonos altos o un mapa de altura.
- Detección de segmentos de línea: es similar a Canny Edge pero para detectar líneas en lugar de segmentos.
- Garabatos: se utiliza para controlar la generación con garabatos o bocetos.

Ejemplos de posibles entradas agregadas para guiar la generación de imágenes con ControlNet.
2.5.4 Conclusiones principales
Los autores del artículo de ControlNet entrenaron varias ControlNet con diversos conjuntos de datos, incluidas las condiciones mencionadas y otras, como la estimación de poses. Experimentaron con conjuntos de datos pequeños (menos de 50 000 o incluso 1000 muestras) y conjuntos de datos grandes (millones de muestras). Los resultados indican que, para tareas como la medición de la profundidad de imagen, el entrenamiento de ControlNets en un ordenador personal (Nvidia RTX 3090TI) puede lograr resultados competitivos en comparación con los modelos comerciales que utilizan clústeres de computación extensos con terabytes de memoria de GPU y miles de horas de GPU.
3. Casos de uso de modelos de difusión en el mundo real
3.1 Prueba virtual
La prueba virtual permite a los usuarios visualizar digitalmente y experimentar el aspecto y el ajuste de la ropa, los accesorios o los artículos en tiempo real. Proporciona una forma interactiva de explorar estilos y tomar decisiones de compra informadas sin necesidad de usar probadores físicos.

Ejemplo de prueba virtual de ropa a una modelo
3.2 Creación de anuncios
La creación de anuncios implica la elaboración de contenido persuasivo y visualmente atractivo. Esto ocurre a menudo con una combinación de texto, imágenes y elementos multimedia. El objetivo es comunicar eficazmente el mensaje, los productos o los servicios de una marca a un público objetivo. Los modelos de difusión pueden ayudar a acelerar este proceso, utilizando menos recursos y menos tiempo, ayudando a los equipos de marketing y diseño.

Ejemplo de anuncios creados utilizando modelos de difusión como imagen base con alguna edición posterior
3.3 Diseño de productos y ropa
El proceso de diseño de productos y prendas implica la conceptualización de ideas innovadoras y funcionales por su estética y utilidad. Aplicar el pensamiento creativo para crear artículos únicos y prácticos, que van desde dispositivos tecnológicos hasta colecciones de ropa. Los diseñadores tienen en cuenta el color, las formas, los materiales y la perfecta integración de los componentes para crear creaciones funcionales y visualmente atractivas que atraigan a los usuarios.
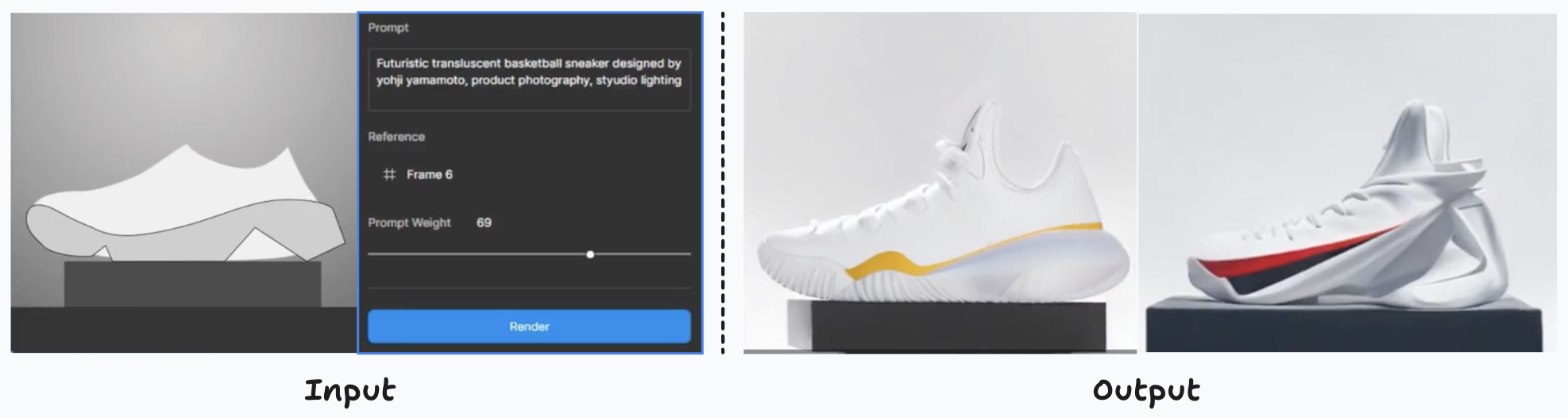
Creación de variantes de producto basadas en un boceto del producto y modificadas con el lema «Zapatilla de baloncesto futurista translúcida diseñada por yohji Yamamoto, fotografía de producto, luz de estudio»
3.4 Mejoras en las escenas de películas
Mejorar las escenas cinematográficas implica refinar varios aspectos de las secuencias cinematográficas. Esto incluye mejorar los efectos visuales, optimizar los elementos de audio y, en general, mejorar la experiencia del público. Estas mejoras también pueden suponer un ahorro de tiempo y costes durante la edición de posproducción. Este enfoque eficiente permite a los cineastas asignar los recursos de manera más eficaz y, al mismo tiempo, ofrecer un producto final refinado y cautivador.

La imagen de la derecha es un fotograma del mismo vídeo de la imagen de la izquierda, pero modificado con el mensaje «Haz que parezca más cinematográfico»

La imagen de la derecha es un fotograma del mismo vídeo de la imagen de la izquierda, pero modificado mediante el uso de pintura para eliminar la luz coloreada presente en la imagen de la izquierda
4. Ejemplo real del uso de modelos de difusión
Un ejemplo real de cómo ajustar los modelos de difusión para enseñarles conceptos específicos es la generación de imágenes que contienen lesiones cutáneas. La aplicación de modelos y técnicas de aprendizaje profundo a las imágenes médicas a menudo se enfrenta a un desafío común: la escasez de datos de buena calidad y bien etiquetados. Los fenómenos de escasez de datos y desequilibrio de clases son bastante comunes cuando se trabaja con este tipo de datos. Para abordar estos problemas, un enfoque eficaz es mediante el aumento de datos. Utilizando pocas imágenes reales, digamos entre 5 y 20 imágenes del Conjunto de datos HAM 1000, podemos crear imágenes generadas de alta calidad de una lesión cutánea determinada. Estas imágenes pueden ayudar a mejorar el rendimiento de los modelos de clasificación, detección y segmentación, entre otros, mediante el aumento de datos.
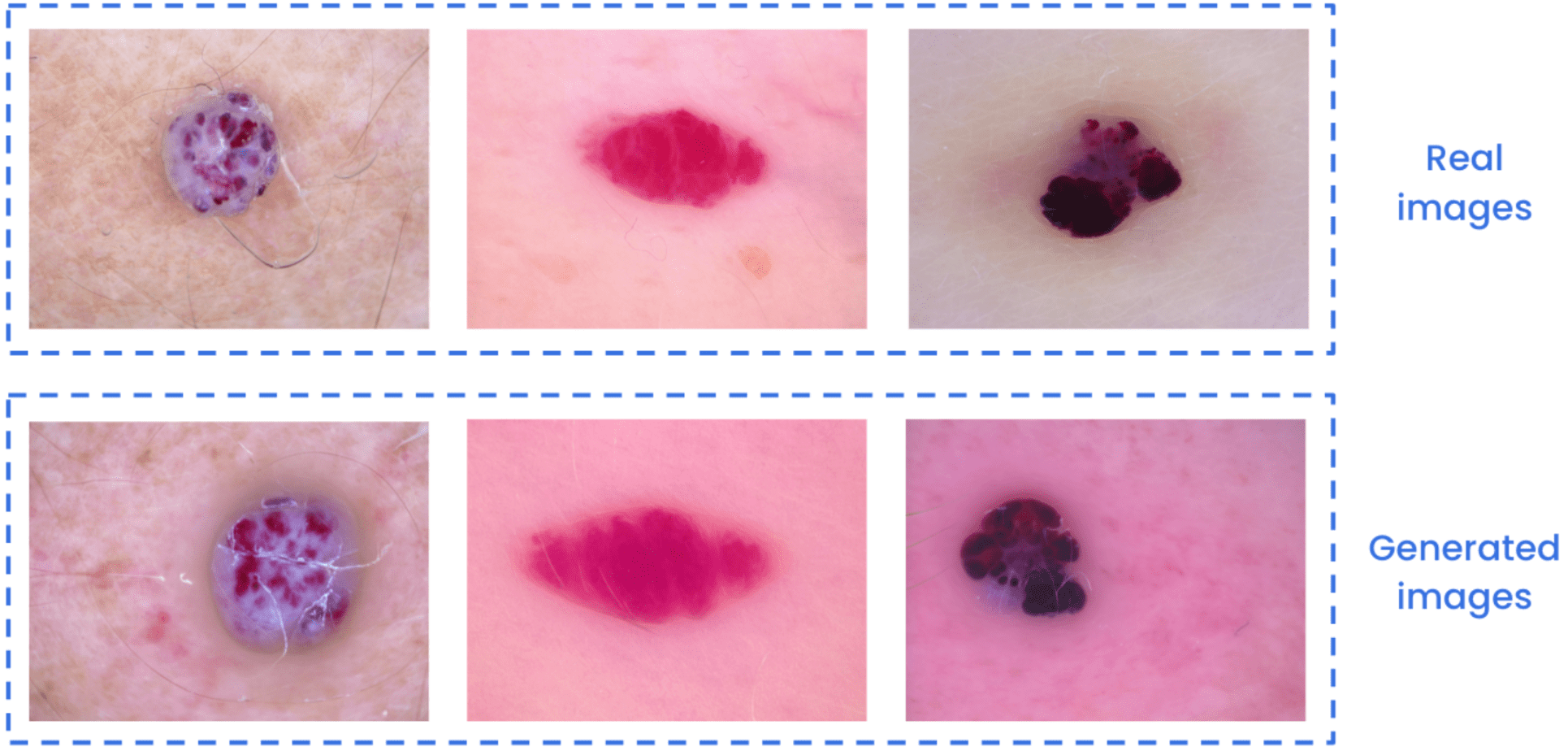
Comparación entre imágenes reales y generadas de lesiones cutáneas vasculares.

Comparación entre imágenes reales y generadas de lesiones cutáneas de melanoma.
Para evaluar el potencial de las imágenes generadas, se abordó el problema de clasificación de este conjunto de datos con y sin aumento de datos. Estas imágenes no reales se generaron a partir del ajuste fino de un modelo de difusión estable. Para simplificar, esta evaluación se centró en cinco de las siete lesiones cutáneas diferentes del conjunto de datos. En este caso concreto, un modelo de clasificación de EfficientNet-B0 mostró una mejora del 79,9% al 88,7% en la métrica de precisión equilibrada y del 79,9% al 88,4% en la métrica de recuperación equilibrada. Lograr esta mejora implicó combinar imágenes generadas y reales, en lugar de depender únicamente de las imágenes del conjunto de datos. Todos los cálculos tuvieron en cuenta el desequilibrio de clases y la filtración de datos y emplearon métricas estándar específicas para este conjunto de datos. Si bien los resultados pueden variar según el caso de uso y el esfuerzo invertido en el ajuste del modelo de difusión. Este ejemplo ofrece solo una idea de las posibilidades de los modelos de difusión.
5. Conclusiones clave
Hay varias formas de mejorar los resultados de los modelos de difusión previamente entrenados, como Stable Diffusion, mediante el ajuste fino. Sin embargo, no se ha encontrado ningún enfoque mejor que los demás en diversos casos de uso.
5.1 Pautas generales
Algunas de las preguntas que debemos hacernos antes de probar una implementación de estas técnicas son:
- ¿Cuántos conceptos, objetos o estilos diferentes queremos que genere el modelo?
Si hay muchos, quizás DreamBooth no sea la opción ideal.
- ¿Qué tan difícil creemos que es nuestro concepto? ¿Son realmente importantes los detalles?
Si queremos que un modelo aprenda un estilo de manera amplia, tal vez un modelo de inversión textual podría ser suficiente. Sin embargo, si queremos replicar un objeto determinado de la forma más idéntica posible o patrones que no son comunes en los conjuntos de datos de imágenes, como las afecciones médicas, podríamos terminar necesitando entrenar un modelo LoRa o incluso DreamBooth. Recuerda que las inversiones textuales buscan «el mensaje perfecto» donde los fenómenos visuales ya deben conocerse en el entrenamiento previo a Stable Diffusion. De hecho, DreamBooth puede insertar nuevos conceptos nunca antes vistos en SD antes del entrenamiento.
- ¿Hay algún requisito de disco, RAM, velocidad o GPU?
Estas son las principales carencias de DreamBooth. Si necesitamos ajustar diferentes modelos SD con DreamBooth para que destaquen en diferentes conceptos, es posible que necesitemos más infraestructura en la nube para mantenerlos por completo.
- ¿Necesitamos que la salida siga un patrón específico? Digamos, ¿una persona con una postura determinada, un objeto con ciertos bordes o en una ubicación determinada de una imagen?
En estos casos, la alternativa lógica sería probar alguna variación de ControlNets. Sin embargo, otras alternativas de imagen a imagen podrían funcionar bien.
Si bien sirven como pautas generales, es esencial reconocer que cada caso de uso tiene sus características únicas. El diseño de experimentos requiere una consideración cuidadosa de estas peculiaridades para determinar qué arquitectura podría producir resultados óptimos.
5.2 Principales herramientas a tener en cuenta
Vale la pena mencionar que hay dos herramientas principales que debemos tener en cuenta al trabajar con modelos de difusión, que pueden facilitar mucho nuestro trabajo.
- El webi de difusión estable [8] proporciona una interfaz de navegador basada en Gradio para una difusión estable, lo que permite una fácil instalación, ajuste e inferencia sobre modelos de difusión. Este repositorio proporciona una gran cantidad de características y parámetros que podemos modificar para observar diferentes resultados. También proporcionan optimizaciones de modelos y trucos para ejecutar estos modelos en hardware restrictivo.
- El difusores [9] La biblioteca, creada por Hugging Face, es la biblioteca de referencia para modelos de difusión preentrenados de última generación. Esto incluye modelos para generar imágenes, audio e incluso estructuras tridimensionales de moléculas. Esta biblioteca proporciona una caja de herramientas modular que admite tanto soluciones de inferencia sencillas como el entrenamiento de sus propios modelos de difusión.
En general, la biblioteca de difusores proporciona varias abstracciones para manejar el código repetitivo. Esto generalmente está vinculado a la definición de los componentes de estos modelos de difusión, así como a las diferentes funcionalidades. Aunque hay algunos ejemplos de scripts sobre cómo entrenar las capas de LoRa, la inversión textual, entre otros, el ciclo de entrenamiento generalmente se escribe para cada caso de uso. Por otro lado, la interfaz web de difusión estable puede gestionar todo esto por nosotros, aunque se parece más a una caja negra. La principal desventaja radica en la facilidad de implementación frente a la transparencia de los componentes de la arquitectura. Además, debemos tener en cuenta nuestras necesidades a la hora de definir las interacciones de esos componentes.
5.3 Comentarios finales
En resumen, los modelos de difusión y la difusión estable en particular han mostrado resultados increíbles para una gran cantidad de aplicaciones diferentes. Para usar estos modelos en la producción, generalmente necesitaríamos hacer un esfuerzo adicional en el rendimiento para lograr los resultados deseados. En este artículo, exploramos diferentes enfoques avanzados para lograr estos mejores resultados, al tiempo que mencionamos las ventajas y desventajas de cada uno de ellos. ¿Está interesado en saber cómo los modelos de difusión pueden generar vídeos consistentes en lugar de imágenes? Echa un vistazo a nuestro blog sobre Modelos de difusión para la generación de vídeo [10].
6. Referencias
- Demostración estable de Diffusion XL Turbo
- Introducción a los modelos de difusión y la difusión estable
- Papel ControlNet
- Papel DreamBooth
- Página web oficial de DreamBooth
- Papel de inversión textual
- Papel LoRa
- Interfaz de usuario web estable de Diffusion
- Biblioteca de difusores
- Modelos de difusión para la generación de vídeo
- Ajuste fino de LLM con eficiencia de parámetros con adaptación de rango bajo
- LoRa contra DreamBooth contra inversión textual contra HyperNetworks
- ¿Qué son los modelos LoRa?
- Cómo ajustar Stable Diffusion usando LoRa



.png)