.png)
Ensino de conceitos específicos de modelos de difusão




1. Introdução
1.1 Motivação
Você já se viu vasculhando incansavelmente a internet em busca daquela imagem que transmite perfeitamente sua visão criativa, apenas para ficar aquém? Talvez você seja um criador de conteúdo em busca de recursos visuais que se alinhem perfeitamente às suas ideias. Mas horas de navegação na web geram pouco mais do que frustração. Imagine um cenário em que a imagem que você imagina não existe ou criá-la do zero parece uma tarefa muito demorada. Insira os modelos de difusão e suas diversas variações como seus aliados criativos. Esses modelos permitem que você crie composições impressionantes que podem capturar a essência de sua visão. A melhor parte? Conseguir isso não exige a navegação em processos complexos. Com apenas algumas instruções de texto simples e uma interface intuitiva e fácil de usar, você pode dar vida à sua imagem ideal. Como exemplo, veja a imagem a seguir:

Uma foto de uma pessoa vasculhando imagens da internet, criada usando
1.2 Introdução à difusão estável
A difusão estável (SD) foi treinada em LAÇÃO-5B. O LAION é um conjunto de dados de 5,85 bilhões de pares de imagem e texto filtrados por CLIP de uma ampla variedade de fenômenos visuais. Destes, 2,3 bilhões são escritos em inglês, 2,2 bilhões de amostras são escritas em uma ampla variedade de mais de 100 outros idiomas. Há também 1B de amostras com textos que não permitem uma determinada atribuição de idioma (por exemplo, nomes de pessoas famosas). Isso permite que o modelo compreenda diversos conceitos visuais usando vários idiomas e se lembre de pontos turísticos e pessoas. Os modelos de difusão se destacam na geração de imagens para diversos fins. Daí a importância de entender alternativas, como o ajuste fino, para melhorar o desempenho em conceitos específicos. Em nosso blog anterior [2], exploramos os fundamentos dos modelos de difusão, seu funcionamento interno e as incríveis possibilidades que eles oferecem. Também introduzimos a difusão estável, conhecida por seus recursos de orientação sem classificadores. Mas o mais importante é que a eficiência aprimorada, o treinamento acelerado e a aceleração da inferência graças à sua abordagem de espaço latente. Agora, é hora de mergulhar mais fundo no reino dos modelos de difusão. Nosso objetivo é descobrir como podemos aproveitar esses modelos notáveis para ensinar-lhes conceitos específicos por meio de ajustes finos, mantendo o controle sobre a saída gerada para se alinhar perfeitamente à nossa visão exclusiva.
2. Métodos
Quando se trata de ensinar modelos de difusão para compreender um conceito específico, como um objeto ou um estilo específico, existem quatro métodos principais à nossa disposição:
- Dream Booth
- Inversão textual
- Adaptação de baixa classificação (LoRa)
- Hiperredes
Existem mais algumas alternativas, como Aesthetic Embeddings. No entanto, neste artigo, vamos nos concentrar nessas quatro, pois outras técnicas ainda precisam de algumas melhorias para fornecer imagens com qualidade comparável às outras alternativas. Ao longo de nossa visão geral sobre esses métodos, discutiremos seu funcionamento interno, pontos fortes e possíveis compensações. Por uma questão de simplicidade, vamos considerar um caso de uso em que nosso objetivo é gerar novas imagens de um conceito específico puramente por meio de solicitação, sem depender de fontes de entrada adicionais, embora essas entradas adicionais sejam discutidas posteriormente na seção de Rede de controle [3].
2.1 DreamBooth
2.1.1 Como isso funciona?
DreamBooth, conforme proposto em “DreamBooth: ajuste fino de modelos de difusão de texto em imagem para geração orientada por assunto” [4], Ruiz et. al (2023), trabalha alterando os parâmetros do próprio modelo de difusão (via ajuste fino) até entender o novo conceito. Para ensinar aos modelos de difusão um novo conceito, como gerar imagens de seu próprio gato, reúna imagens de referência para esse conceito e solicite o uso de um identificador exclusivo, invisível durante o treinamento, conhecido como token SKS. O token SKS ajuda o modelo a associar esse novo token ao conceito visual sempre que ele aparece no prompt. Com relação à incorporação de texto no modelo SD, o DreamBooth não altera a codificação do novo token, mas associa essa incorporação ao novo conceito nas imagens.
2.1.2 Interação dos componentes principais
Por uma questão de simplicidade, vamos considerar um ajuste fino que consiste em apenas uma imagem, embora os autores se refiram ao uso de 3 a 5 imagens em alguns lotes.

Diagrama representando o processo de treinamento com o DreamBooth para uma única imagem.
Tiramos uma imagem que contém o novo conceito (x0) e, em seguida, aplique t etapas de ruído para criar uma imagem de entrada ruidosa para o modelo (xt) e passe essa imagem ruidosa pelo modelo de difusão para prever o ruído presente na imagem. A comparação entre a previsão de ruído e o ruído real adicionado à imagem original é usada para calcular a função de perda, calcular gradientes e, em seguida, atualizar os parâmetros do modelo de difusão. A entrada para o modelo de difusão consiste na imagem ruidosa, no intervalo de tempo amostrado t e o prompt que representa o novo conceito, como: “Uma foto de um gato SKS”. A incorporação textual SKS pode não se referir a um conceito já conhecido. Portanto, o modelo de difusão provavelmente faria um trabalho muito ruim ao eliminar o ruído da imagem nas primeiras vezes. No entanto, isso acabará por levar a um modelo que compreenda o conceito que estamos tentando ensinar usando imagens do conceito e o token SKS no prompt de texto. Nota: uma diferença importante entre o ajuste fino de um U-Net a partir de um modelo de difusão estável é que o processo de ruído e eliminação de ruído em SD está sendo mantido no espaço latente, portanto, a imagem não está corrompida, conforme mostrado no diagrama anterior. Se você quiser ler mais sobre essa abordagem de espaço latente, dê uma olhada em nosso blog anterior [2].

Um exemplo das imagens de entrada e inferências de um conceito ensinado (um Corgi específico) em diversos contextos, conforme apresentado em Página oficial do DreamBooth [5].
2.1.3 Principais conclusões
Essa é provavelmente a maneira mais eficaz de ensinar um novo conceito, adaptando toda a rede ao seu caso de uso específico. No entanto, isso tem um custo: a rede pode se tornar menos proficiente na geração geral de imagens. Além disso, pode não ser adequado para ensinar vários conceitos simultaneamente, pois geralmente resulta em resultados insatisfatórios. O ajuste fino de diferentes modelos de difusão para cada conceito é uma opção. No entanto, ele requer mais memória de disco e recursos computacionais, incluindo GPU e RAM.
2.2 Inversão textual
2.2.1 Como isso funciona?
A inversão textual é uma técnica proposta em “Uma imagem vale uma palavra: personalizando a geração de texto para imagem usando a inversão textual” [6] de Gal et. al (2022). A configuração do Textual Inversion é basicamente idêntica à do DreamBooth, mas com alguns ajustes. Em vez de atualizar os gradientes do modelo como penalidade quando há uma previsão incorreta do ruído adicionado à imagem de entrada, ele atualiza o vetor de incorporação do SKS. Enquanto isso, o modelo de difusão permanece congelado e inalterado. O objetivo por trás disso é criar a incorporação correta para o token SKS que identifique os fenômenos visuais (conceito) que estamos tentando ensinar ao modelo, em vez de atualizar o modelo em si para gerar imagens de um determinado conceito com uma incorporação fixa de um token que não tem nenhum significado.
2.2.2 Interação dos componentes principais
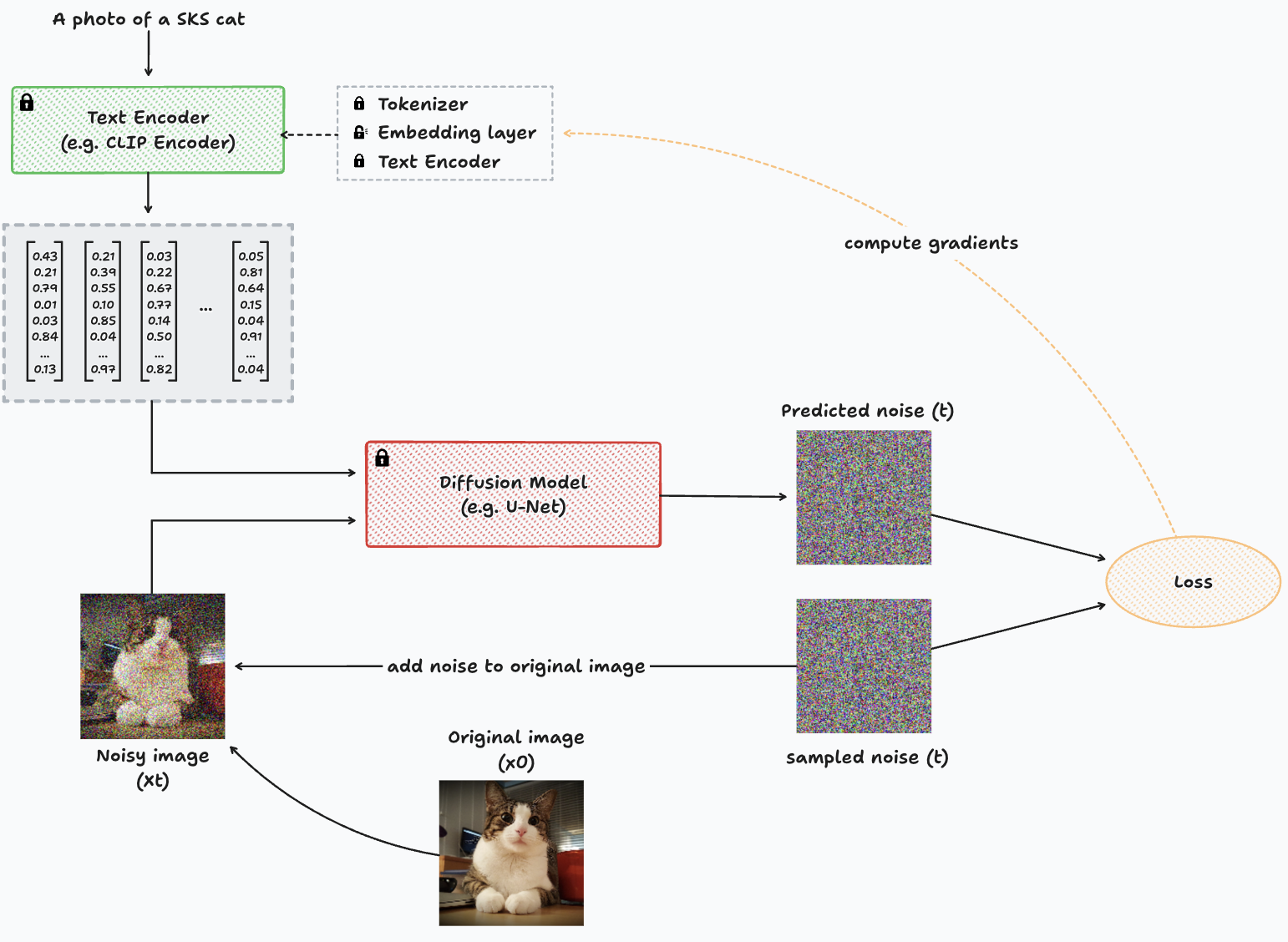
Diagrama representando o processo de treinamento com inversão textual para uma única imagem.
Neste diagrama, observamos essencialmente a mesma estrutura do DreamBooth. No entanto, uma distinção fundamental está no fato de que o modelo de difusão está congelado (não treinável, indicado pelo ícone de cadeado) e o cálculo dos gradientes é direcionado para o codificador de texto. O codificador de texto representado no diagrama é uma representação simplificada do processo subjacente. A codificação de texto envolve dois componentes principais: o tokenizador e o próprio codificador de texto. O tokenizador serve como um dicionário responsável por mapear cada token conhecido em um identificador numérico. Esse mapeamento é crucial, pois os modelos de aprendizado profundo aprendem exclusivamente com representações numéricas de dados.
2.2.3 O codificador de texto
O primeiro converte cada identificador de palavra fornecido pelo tokenizador em uma incorporação que representa vagamente cada palavra em um determinado espaço de menor dimensão. Enquanto o último pega esse conjunto de incorporações vagas geradas pela camada de incorporação e as passa por um codificador de texto transformador. Sendo a saída final, uma representação vetorial de todo o prompt de texto fornecido como entrada.

Diagrama representando os componentes do codificador de texto no treinamento de inversão textual para uma única imagem.
Para isso, adicionamos o novo token ao vocabulário do tokenizador e inicializamos sua incorporação na camada de incorporação. Essa inicialização pode ser aleatória. Embora uma abordagem mais inteligente envolva inicializar o novo conceito com uma palavra representando algo semelhante, embora não idêntico. Pense nisso como tentar entender a aparência de um Corgi, partindo do conceito de aparência de um cachorro. Pode parecer contra-intuitivo que possamos ensinar um conceito ao modelo encontrando a incorporação textual correta, sem nenhum ajuste fino do modelo em si. No entanto, na prática, funciona bem. Os modelos SD possuem uma compreensão diferenciada dos fenômenos visuais. Isso permite que o uso da incorporação perfeita permita criar fenômenos visuais arbitrários que ainda fazem sentido para os humanos. Os autores afirmam que “o espaço de incorporação é expressivo o suficiente para capturar a semântica básica da imagem”. Outra forma de interpretar isso é que poderíamos representar qualquer conceito apenas digitando o prompt correto. Embora existam alguns conceitos que são extremamente difíceis de colocar em palavras, daí a necessidade de uma forma automatizada de aprender essa representação incorporada.
2.2.4 Principais conclusões
Um dos maiores benefícios da inversão textual é que o artefato que salvamos é menor do que o do DreamBooth. Com o DreamBooth, precisamos salvar todo o novo modelo ajustado. Por outro lado, com a inversão textual, podemos simplesmente salvar a incorporação do token SKS. Isso também pode se transformar em vários conceitos novos, pois devem ser incorporações de texto diferentes que estão sendo usadas exatamente pelo mesmo modelo.
2.3 Adaptação de baixa classificação (LoRa)
2.3.1 Como isso funciona?
A abordagem de adaptação de baixa classificação (LoRa) surgiu inicialmente para modelos de linguagem grande (LLMs) no artigo “LoRa: adaptação de baixo nível de grandes modelos linguísticos” [7], Hu et. al (2021). Esta proposta visa enfrentar desafios semelhantes aos enfrentados pelo DreamBooth, onde instruir o modelo em vários conceitos específicos exigiu inúmeras réplicas do modelo, demonstrando ineficiência e impraticabilidade. Para o modelo de difusão, geralmente usamos um modelo que insere e emite imagens do mesmo tamanho. Essa é uma das razões da popularidade da U-Net para esses modelos. A ideia por trás do LoRa é inserir novas camadas minúsculas treináveis, chamadas Camadas LoRa, no modelo de forma que eles não afetem em nada os parâmetros do modelo, mantendo o modelo original congelado. Inicialmente, essas camadas LoRa gerarão uma saída idêntica à sua entrada, replicando o mesmo comportamento do modelo de difusão congelado. No entanto, o cálculo dos gradientes acabará por modificá-los, ajustando seus parâmetros. Esse processo altera a entrada para camadas intermediárias dentro do modelo de difusão congelado, guiando a geração em direção ao novo conceito desejado.
2.3.2 Interação dos componentes principais

Diagrama representando o processo de treinamento com LoRa para uma única imagem.
Como pode ser visto no diagrama anterior, o modelo de difusão está congelado, permanecendo não treinável durante todo o processo. Os pesos LoRa são aqueles sujeitos a atualizações por meio do cálculo de gradiente. Mas como as camadas LoRa funcionam? Normalmente incorporamos essas camadas nos blocos de atenção da U-Net. Essas camadas recebem a mesma entrada, realizam uma multiplicação de matrizes adicional e adicionam o resultado à saída de atenção treinada anteriormente.

Um diagrama ilustrando a disposição das camadas de LoRa dentro dos blocos de atenção da U-Net.
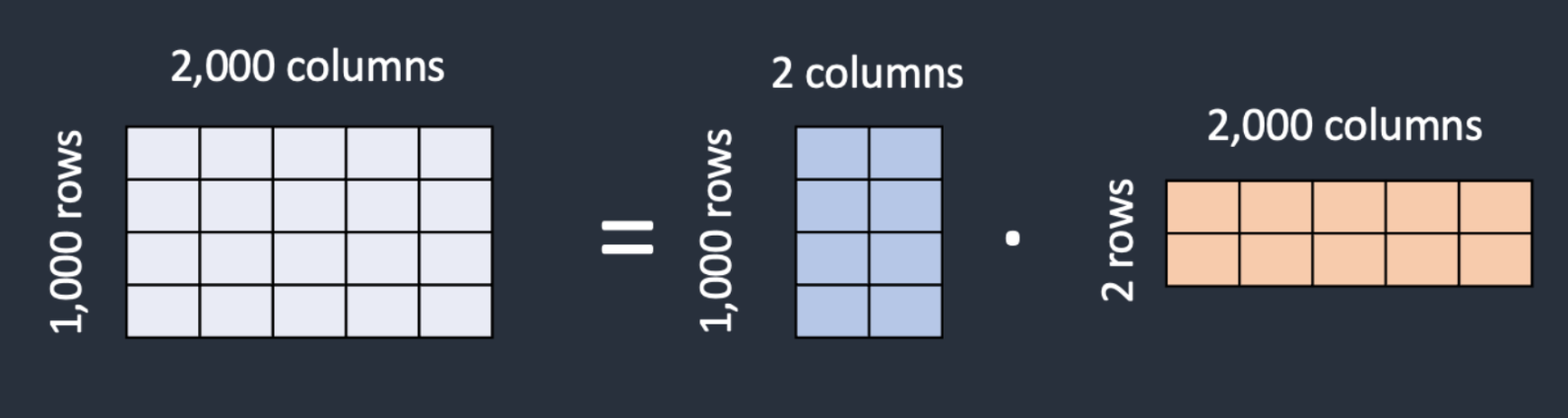
Outra pergunta é: por que precisamos dessas novas camadas e não apenas de atualizar os pesos de atenção congelados? Um dos principais benefícios das camadas LoRa é a quantidade reduzida de parâmetros que elas usam. O”Classificação baixa“termo se refere a isso. Em vez de ter uma matriz de dimensão m x n, definimos uma multiplicação de duas matrizes UMA GUERRA e WEB de dimensões m x k e k x n respectivamente. Se contarmos o número de parâmetros necessários com cada abordagem, com a primeira abordagem armazenamos 2 milhões de valores, enquanto a segunda (LoRa) armazenamos 6000 valores (UMA GUERRA armazena 2000 valores e WEB armazena 4000 valores).
Representação matricial da decomposição matricial com adaptação de baixa classificação (LoRa).
2.3.3 Principais conclusões
O treinamento LoRa é muito mais rápido e consome menos memória do que o ajuste fino de todo o modelo de difusão estável com o DreamBooth. Além disso, as camadas LoRa são consideravelmente menores do que o próprio modelo SD, tornando-as muito mais fáceis de armazenar e compartilhar em comparação com o modelo completo.
2.4 Hiperredes
2.4.1 Como isso funciona?
As HyperNetworks funcionam de forma bastante semelhante ao LoRa, mas em vez de adicionar essas camadas intermediárias aos modelos SD, temos um modelo separado - chamada de HyperNetwork - que é treinado para criar algumas matrizes que ajustam levemente os valores dos mapas de recursos dentro do modelo de difusão, para que ele aprenda a gerar o conceito desejado. Não há nenhum documento oficial para esse tipo de rede, no entanto, existem vários artigos que apresentam essa forma de ajustar um modelo SD, onde provavelmente um dos mais populares é o ControlNet, conforme proposto em “Adicionando controle condicional aos modelos de difusão de texto para imagem” [3], de Zhang e Agrawala (2023). Apesar de apresentar outros recursos inovadores, que serão discutidos em breve, o ControlNet ainda é classificado como uma HyperNetwork.
2.4.2 Interação dos componentes principais
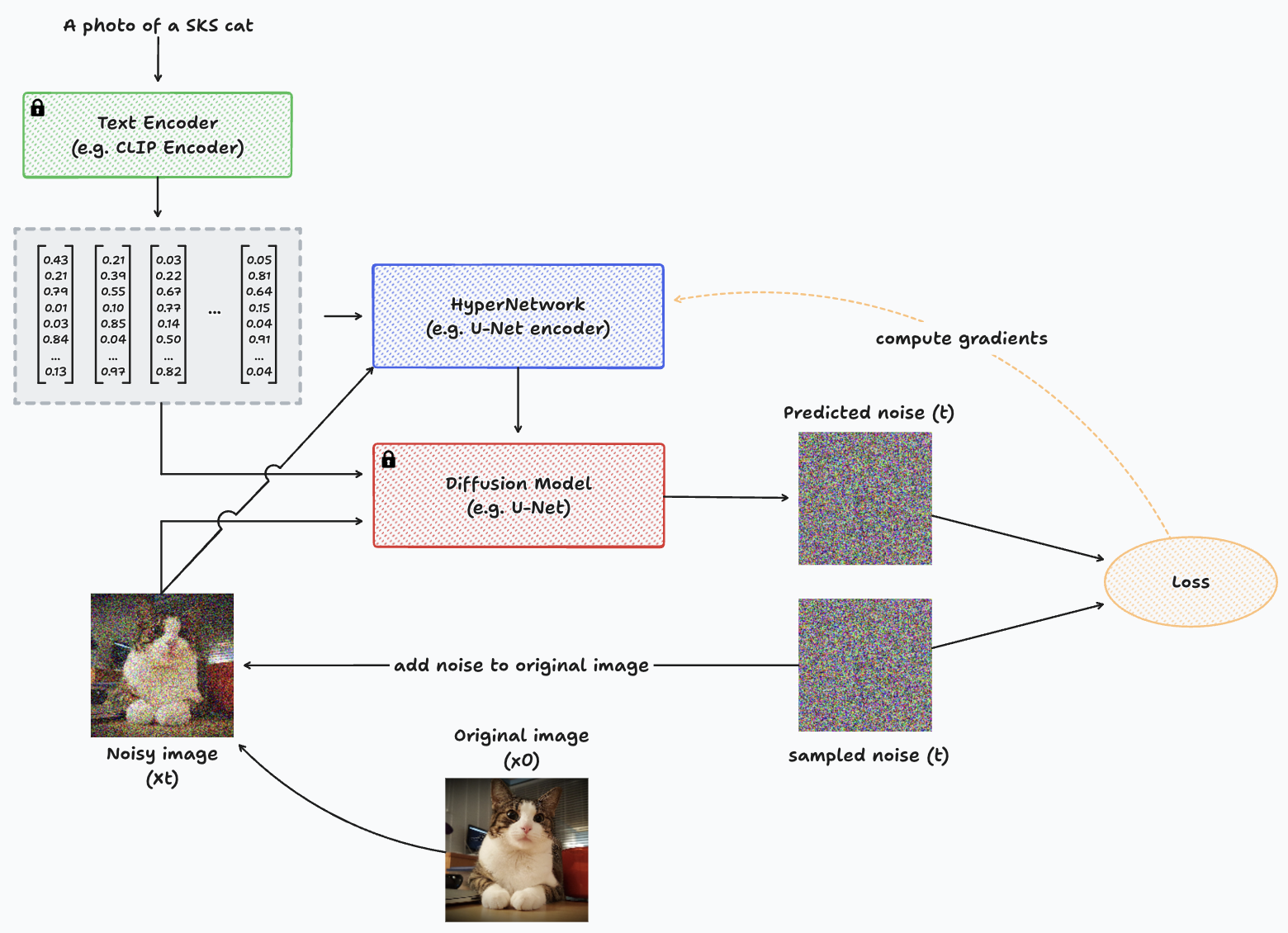
Diagrama representando o processo de treinamento com HyperNetworks para uma única imagem.
Para projetar a arquitetura HyperNetwork de forma simples, podemos simplesmente replicar os blocos codificadores da U-Net, junto com seu gargalo. Em seguida, conecte esses blocos aos blocos decodificadores do modelo de difusão. Em essência, é como ter dois codificadores U-Net distintos e um único decodificador. Um codificador e o decodificador têm parâmetros congelados (do modelo de difusão pré-treinado), enquanto o novo codificador ajusta levemente a entrada e a adiciona às camadas do decodificador para guiar a geração em direção ao novo conceito.
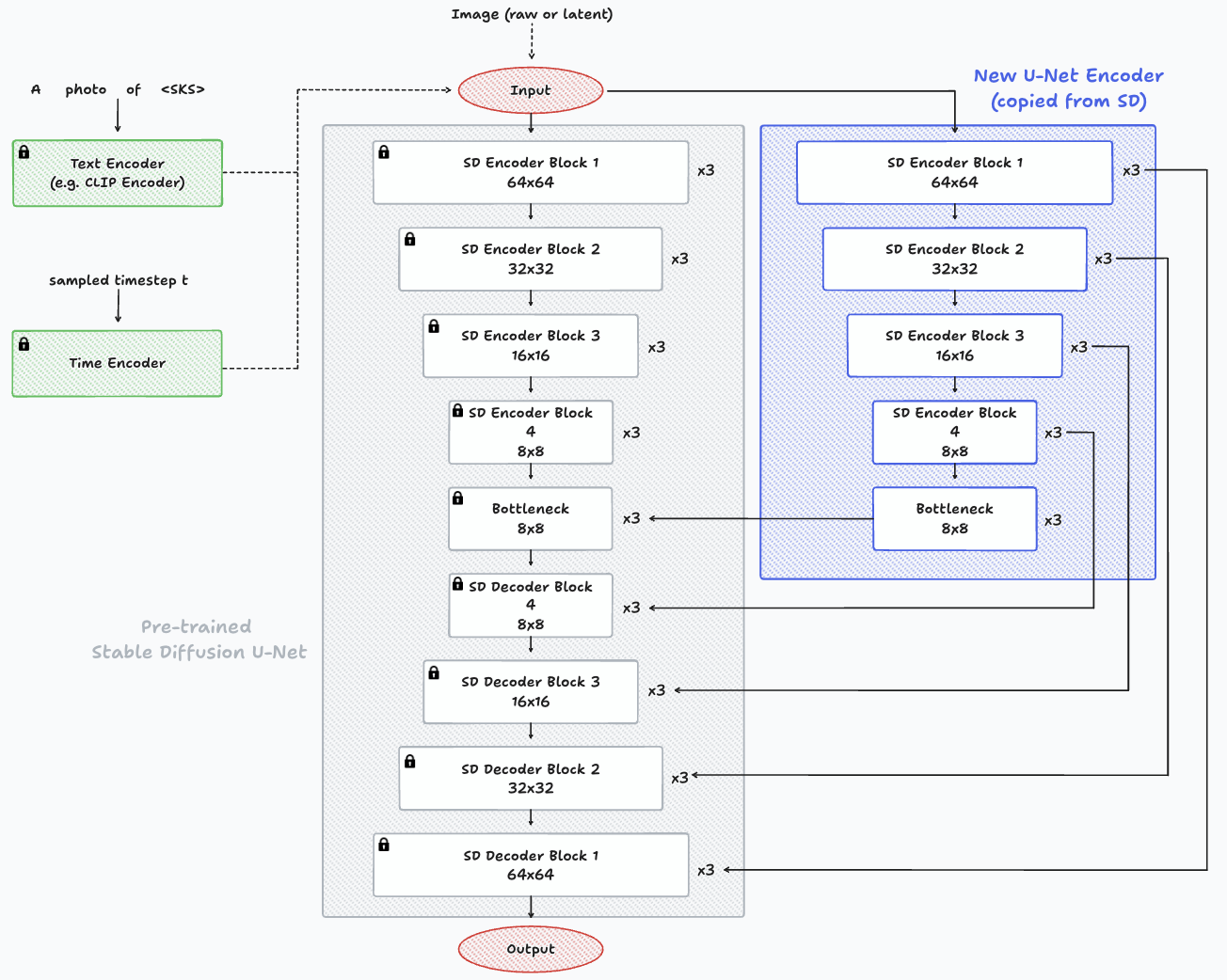
Exemplo de arquitetura de uma hiperrede e sua conexão com o modelo de difusão. No centro, em cinza, podemos ver o codificador, o gargalo e o decodificador do modelo pré-treinado de difusão estável com parâmetros congelados. À direita, destacado em azul, o novo codificador (HyperNetwork) é visível, apresentando camadas copiadas idênticas que se conectam às camadas do decodificador do modelo de difusão pré-treinado.
2.4.3 Principais conclusões
Essa abordagem ainda não produziu resultados empíricos comparáveis às técnicas mencionadas anteriormente. No entanto, a HyperNetworks ganhou muita atenção com o lançamento do ControlNet, uma arquitetura sobre a qual falaremos a seguir. Essas redes têm parâmetros mais treináveis em comparação com a inversão textual e o LoRa. Teoricamente, isso poderia significar que eles poderiam aprender padrões mais complexos, mas menos do que ajustar todo o modelo de difusão estável, como acontece com o DreamBooth.
2.5 ControlNet
2.5.1 Como isso funciona?
Embora tenhamos apresentado Rede de controle [3] como um caso particular de HyperNetworks, é de nosso interesse apresentar os principais avanços que ela acarreta, pois foi proposta como uma arquitetura de rede neural de ponta a ponta capaz de controlar grandes modelos de difusão de imagens (como a difusão estável) para aprender as condições de entrada específicas da tarefa.
2.5.2 Interação dos componentes principais
O ControlNet clona os pesos de um grande modelo de difusão em um cópia treinável e um cópia bloqueada. A cópia bloqueada mantém a capacidade de rede adquirida de bilhões de imagens durante o pré-treinamento. Simultaneamente, a cópia treinável passa por treinamento em conjuntos de dados específicos de tarefas para adquirir controle condicional, estabelecendo um link direto com a arquitetura apresentada nas HyperNetworks, mas com alguns ajustes.
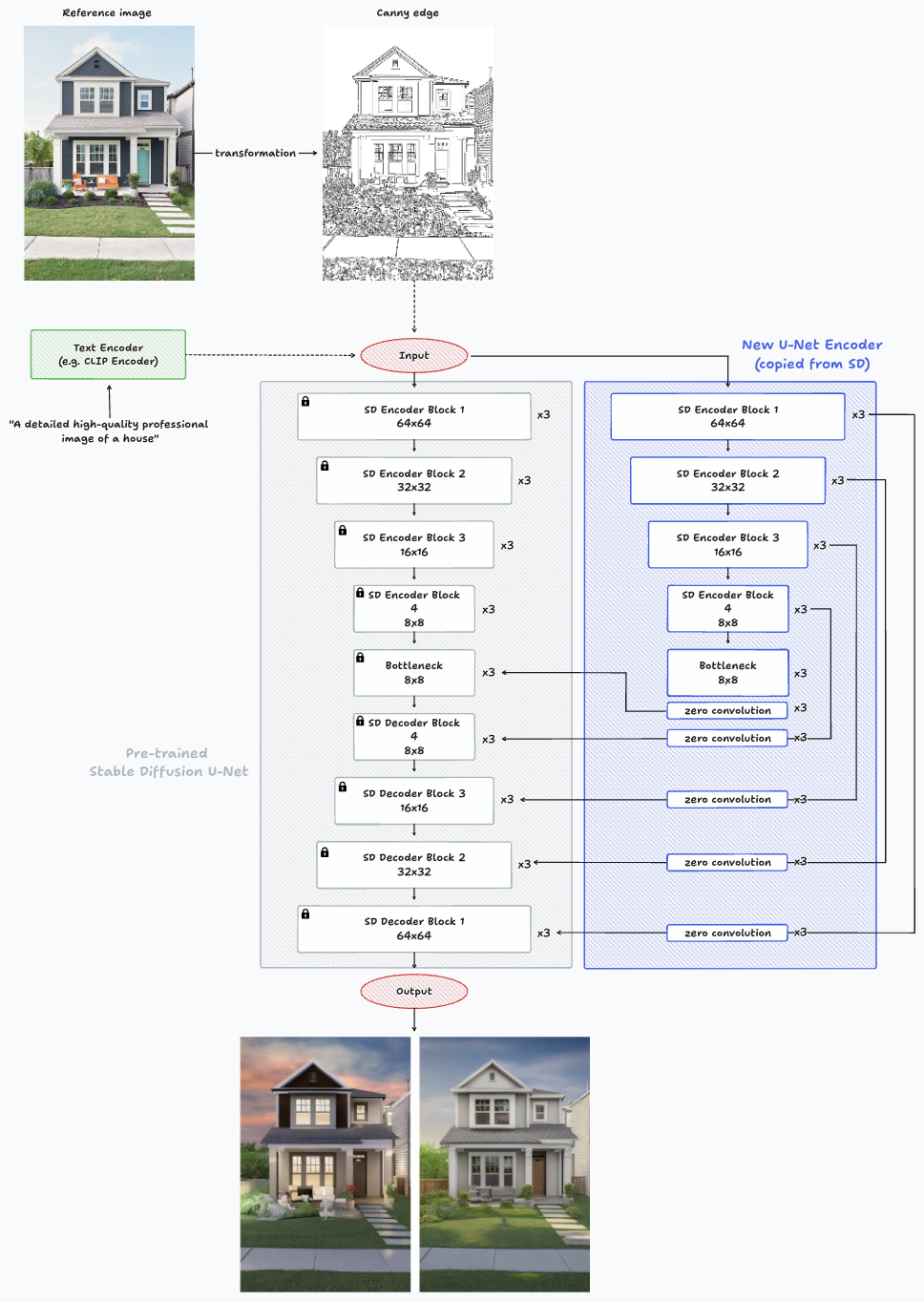
Arquitetura do ControlNet ao fazer uma inferência em uma única imagem com o Canny Edge.
As mudanças mais notáveis da arquitetura mostrada no HyperNetworks são a adição de camadas de convolução zero após os blocos do novo codificador e antes de entrar no decodificador de difusão estável, e a capacidade de guiar a geração da imagem com uma nova entrada, como a mostrada no Canny Edge. A rede neural treinável se conecta à rede neural bloqueada por meio de uma camada de convolução distinta conhecida como “convolução zero”. Essa camada ajusta gradualmente seus pesos de convolução, progredindo de zeros para parâmetros otimizados de forma aprendida. A preservação de pesos prontos para produção aumenta a robustez do treinamento em conjuntos de dados de diferentes escalas.
2.5.3 Mecanismos de condicionamento
Alguns dos condicionamentos mais comuns usados no ControlNet são, mas não se limitam a:
- Canny Edge: detecção de bordas suavizando a imagem com filtros gaussianos, depois removendo o ruído usando um kernel gaussiano discreto e identificando as áreas na imagem com os gradientes de intensidade mais fortes.
- Mapa de profundidade: refere-se a uma imagem ou canal que contém informações relacionadas à distância das superfícies dos objetos presentes em uma cena a partir de um determinado ponto de vista.
- CABEÇA: tenta resolver as limitações do detector de borda Canny por meio de uma rede neural profunda de ponta a ponta.
- Mapeamento normal: é uma técnica de mapeamento de textura usada para simular a iluminação de solavancos e amassados, aprimorando a aparência e os detalhes de um modelo de baixo polígono ao gerar um mapa normal a partir de um modelo de polígono alto ou mapa de altura.
- Detecção de segmento de linha: é semelhante ao canny edge, mas para detectar linhas em vez de segmentos.
- Rabiscos: usado para controlar a geração com rabiscos ou esboços.

Exemplos de possíveis entradas adicionadas para orientar a geração de imagens com o ControlNet.
2.5.4 Principais conclusões
Os autores do artigo da ControlNet treinaram várias ControlNets com diversos conjuntos de dados, incluindo as condições mencionadas e outras, como estimativa de pose. Eles experimentaram pequenos conjuntos de dados (menos de 50 mil ou até 1 mil amostras) e grandes conjuntos de dados (milhões de amostras). Os resultados indicam que, para tarefas como profundidade de imagem, treinar ControlNets em um computador pessoal (Nvidia RTX 3090TI) pode alcançar resultados competitivos em comparação com modelos comerciais treinados em extensos clusters de computação com terabytes de memória de GPU e milhares de horas de GPU.
3. Casos de uso reais de modelos de difusão
3.1 Experiência virtual
O Virtual Try-On permite que os usuários visualizem e experimentem digitalmente como roupas, acessórios ou itens parecem e se encaixam em tempo real. Ele fornece uma maneira interativa de explorar estilos e tomar decisões de compra informadas sem provadores físicos.

Exemplo de teste virtual de roupas em um modelo
3.2 Criação de anúncios
A criação de anúncios envolve a criação de conteúdo persuasivo e visualmente atraente. Isso geralmente ocorre usando uma combinação de texto, imagens e elementos multimídia. O objetivo é comunicar com eficácia a mensagem, os produtos ou os serviços de uma marca a um público-alvo. Os modelos de difusão podem ajudar a acelerar esse processo, usando menos recursos e menos tempo, auxiliando as equipes de marketing e design.

Exemplo de anúncios criados usando modelos de difusão como imagem base com algumas edições posteriores
3.3 Design de produtos e roupas
O processo de design de produtos e roupas envolve a conceituação de ideias inovadoras e funcionais para sua estética e utilidade. Aplicar o pensamento criativo para criar itens exclusivos e práticos, desde dispositivos tecnológicos até coleções de roupas. Os designers consideram cores, formas, materiais e integração perfeita de componentes para criações visualmente atraentes e funcionais que ressoam com os usuários.
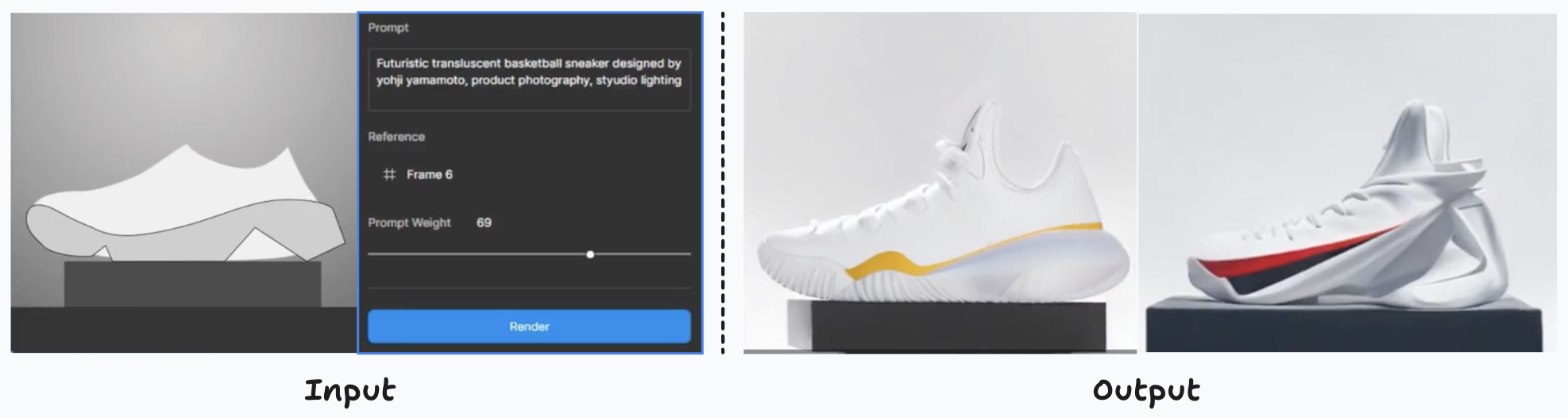
Criação de variantes de produto com base em um esboço do produto e modificadas usando o aviso “Tênis de basquete translúcido futurista projetado por yohji yamamoto, fotografia do produto, luz de estúdio”
3.4 Aprimoramentos de cenas de filmes
O aprimoramento de cenas de filmes envolve refinar vários aspectos das sequências cinematográficas. Isso inclui melhorar os efeitos visuais, otimizar os elementos de áudio e elevar a experiência geral do público. Esses aprimoramentos também podem levar à economia de custo e tempo durante a edição de pós-produção. Essa abordagem eficiente permite que os cineastas aloquem recursos com mais eficiência e, ao mesmo tempo, forneçam um produto final sofisticado e cativante.

A imagem da direita é um quadro do mesmo vídeo da imagem da esquerda, mas modificada usando o prompt “Faça com que pareça mais cinematográfico”

A imagem da direita é um quadro do mesmo vídeo da imagem da esquerda, mas modificada usando a pintura embutida para remover o poste de luz colorido presente na imagem à esquerda
4. Exemplo real do uso de modelos de difusão
Um exemplo real de ajuste fino de modelos de difusão para ensinar conceitos específicos é a geração de imagens contendo lesões cutâneas. A aplicação de modelos e técnicas de aprendizado profundo às imagens médicas geralmente encontra um desafio comum: a escassez de dados bem rotulados e de boa qualidade. Os fenômenos de escassez de dados e desequilíbrio de classes são bastante comuns quando se trabalha com esses tipos de dados. Para resolver esses problemas, uma abordagem eficaz é por meio do aumento de dados. Usando poucas imagens reais, digamos entre 5 e 20 imagens do Conjunto de dados HAM 1000, podemos criar imagens geradas de alta qualidade de uma determinada lesão cutânea. Essas imagens podem ajudar a melhorar o desempenho dos modelos de classificação, detecção e segmentação, entre outros, por meio do aumento de dados.
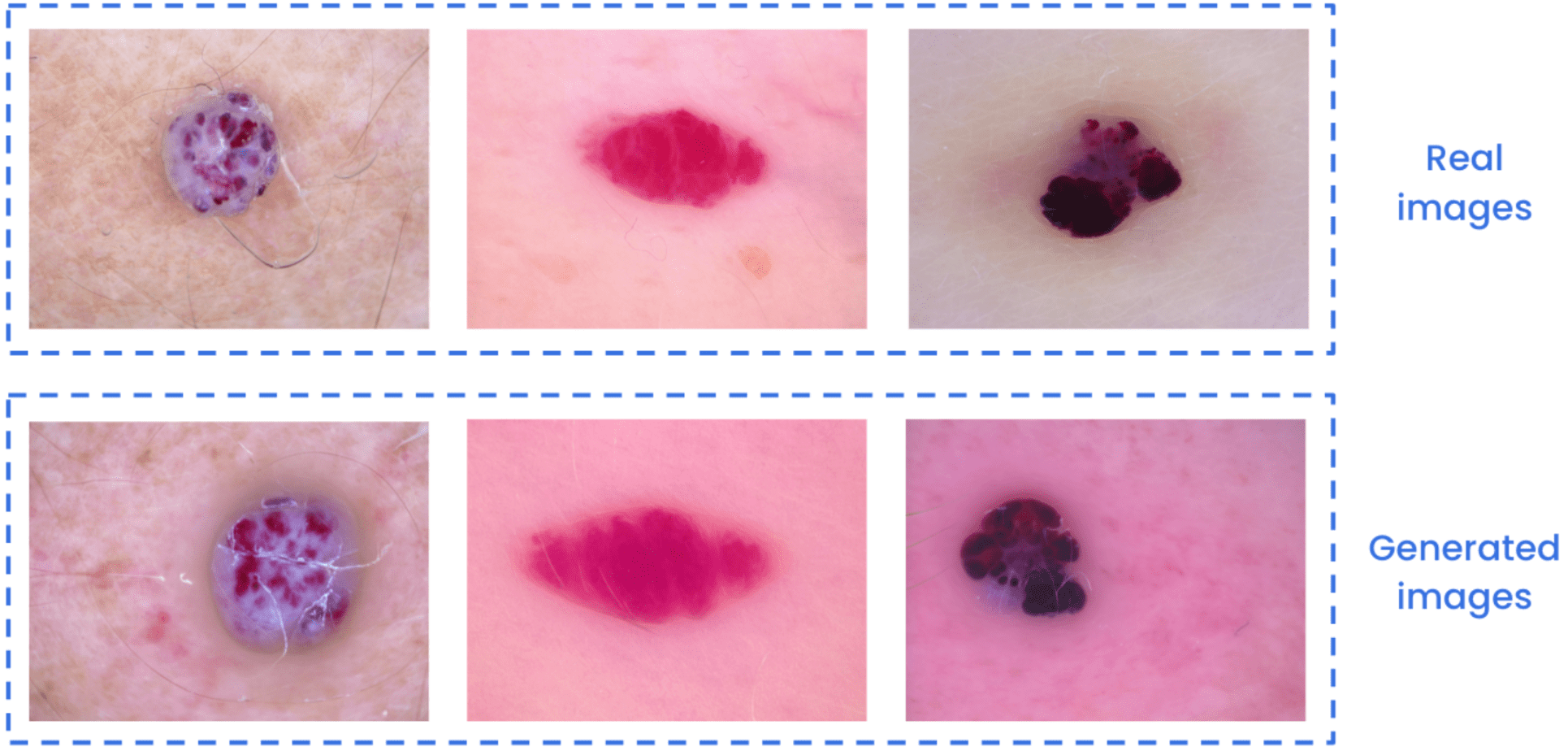
Comparação entre imagens reais e geradas de lesões vasculares da pele.

Comparação entre imagens reais e geradas de lesões cutâneas de melanoma.
Para avaliar o potencial das imagens geradas, o problema de classificação desse conjunto de dados foi resolvido com e sem aumento de dados. Essas imagens não reais foram geradas a partir do ajuste fino de um modelo de difusão estável. Esta avaliação se concentrou em cinco das sete lesões cutâneas diferentes no conjunto de dados para simplificar. Nesse caso específico, um modelo de classificação EfficientNet-B0 mostrou uma melhora de 79,9% para 88,7% na métrica de precisão balanceada e de 79,9% para 88,4% na métrica de recall balanceado. Alcançar essa melhoria envolveu combinar imagens geradas e reais, em vez de depender apenas das imagens do conjunto de dados. Todos os cálculos consideraram o desequilíbrio de classes, o vazamento de dados e empregaram métricas padrão específicas para esse conjunto de dados. Embora os resultados possam variar dependendo do caso de uso e do esforço investido no ajuste fino do modelo de difusão. Este exemplo fornece apenas um vislumbre das possibilidades dos modelos de difusão.
5. Principais conclusões
Existem várias maneiras de melhorar os resultados de modelos de difusão pré-treinados, como a difusão estável, por meio de ajuste fino. No entanto, nenhuma abordagem foi considerada melhor do que as outras em diversos casos de uso.
5.1 Diretrizes gerais
Algumas das perguntas que devemos nos perguntar antes de experimentar uma implementação dessas técnicas são:
- Quantos conceitos, objetos ou estilos diferentes queremos que o modelo gere?
Se houver muitos, talvez o DreamBooth não seja a opção ideal.
- Acreditamos que nosso conceito é difícil? Os detalhes são realmente importantes?
Se quisermos que um modelo aprenda amplamente um estilo, talvez um modelo de inversão textual seja suficiente. No entanto, se quisermos replicar um determinado objeto da forma mais idêntica possível ou padrões que não são comuns em conjuntos de dados de imagens, como condições médicas, podemos acabar precisando treinar um modelo LoRa ou mesmo o DreamBooth. Lembre-se de que as inversões textuais procuram “o prompt perfeito” onde o fenômeno visual já deve ser conhecido no pré-treinamento de difusão estável. O DreamBooth pode, na verdade, inserir novos conceitos nunca vistos no pré-treinamento de SD.
- Há algum requisito de disco, RAM, velocidade ou GPU?
Essas são as principais deficiências do DreamBooth. Se precisarmos ter diferentes modelos de SD ajustados com o DreamBooth para nos destacarmos em conceitos diferentes, talvez precisemos de mais infraestrutura em nuvem para mantê-los totalmente integrados.
- Precisamos que a saída siga um padrão específico? Digamos, uma pessoa com uma certa pose, um objeto com certas bordas ou em um determinado local de uma imagem?
Nesses casos, a alternativa lógica seria tentar alguma variação do ControlNets. Embora outras alternativas de imagem para imagem possam funcionar bem.
Embora elas sirvam como diretrizes gerais, é essencial reconhecer que cada caso de uso tem suas características exclusivas. Projetar experimentos requer uma análise cuidadosa dessas peculiaridades para determinar qual arquitetura poderia produzir resultados ideais.
5.2 Principais ferramentas a serem consideradas
Vale ressaltar que há duas ferramentas principais que precisamos conhecer ao trabalhar com modelos de difusão, o que pode facilitar muito nosso trabalho.
- O webui de difusão estável [8] fornece uma interface de navegador baseada em Gradio para difusão estável, permitindo fácil instalação, ajuste fino e inferência sobre modelos de difusão. Esse repositório fornece muitos recursos e parâmetros que podemos modificar para observar resultados diferentes. Eles também fornecem otimizações de modelos e truques para executar esses modelos em hardware restritivo.
- O difusores [9] A biblioteca, criada pela Hugging Face, é a biblioteca ideal para modelos de difusão pré-treinados de última geração. Isso inclui modelos para gerar imagens, áudio e até estruturas 3D de moléculas. Essa biblioteca fornece uma caixa de ferramentas modular que oferece suporte a soluções simples de inferência e ao treinamento de seus próprios modelos de difusão.
Geralmente, a biblioteca de difusores fornece várias abstrações para lidar com o clichê do código. Isso geralmente está ligado à definição dos componentes desses modelos de difusão, bem como às diferentes funcionalidades. Embora existam alguns exemplos de scripts sobre como treinar camadas LoRa, inversão textual, entre outros, o ciclo de treinamento geralmente seria escrito para cada caso de uso. Por outro lado, o webui de difusão estável pode lidar com tudo isso para nós, sendo mais parecido com uma caixa preta. A principal compensação está entre a facilidade de implementação e a transparência dos componentes na arquitetura. Além disso, devemos levar em conta nossas necessidades em termos de definição das interações desses componentes.
5.3 Comentários finais
Resumindo, embora os modelos de difusão e a difusão estável, em particular, tenham mostrado resultados incríveis para uma infinidade de aplicações diferentes. Para usar esses modelos na produção, geralmente precisaríamos ir mais longe no desempenho para alcançar os resultados desejados. Neste artigo, exploramos diferentes abordagens de última geração para alcançar esses resultados aprimorados, ao mesmo tempo em que mencionamos os prós e os contras de cada uma delas. Interessado em saber como os modelos de difusão podem gerar vídeos consistentes em vez de imagens? Confira nosso blog em Modelos de difusão para geração de vídeo [10].
6. Referências
- Demonstração do Stable Diffusion XL Turbo
- Uma introdução aos modelos de difusão e difusão estável
- Papel ControlNet
- papel DreamBooth
- Página oficial do DreamBooth
- Papel de inversão textual
- papel LoRa
- Interface de usuário web de difusão estável
- Biblioteca de difusores
- Modelos de difusão para geração de vídeo
- Ajuste fino de LLM com eficiência de parâmetros com adaptação de baixa classificação
- LoRa x DreamBooth x inversão textual x HyperNetworks
- O que são modelos LoRa
- Como ajustar a difusão estável usando LoRa



.png)