.png)
Diferencia entre Gemma y Gemini




Introducción
Google, en particular su equipo DeepMind, ha lanzado un conjunto de modelos ligeros, llamados Gemma, los mismos que participaron en la creación de Gemini. Está disponible en dos tamaños, 2B y 7B. Viene con un excelente kit de herramientas de IA generativa responsable, un SFT para varios marcos y bibliotecas y colaboraciones listas para usar. Los modelos previamente entrenados o los personalizados pueden ejecutarse localmente (sí, localmente) o a través de una GPU, donde el equipo de Google ha mejorado el rendimiento de NVIDIA y Google Cloud TPU. Además, sus condiciones de uso permiten el uso comercial. Así que, si te estabas preguntando por su comodidad o por el encaje entre tu caso de uso y el de Gemma -en cualquiera de sus sabores-, ¡la respuesta es sí! Sigue leyendo para saber qué hay debajo del capó.
Desarrolle estrategias y restricciones
Gemma se creó siguiendo el kit de herramientas de IA generativa responsable, que añade una capa de seguridad con respecto al comportamiento de las aplicaciones de LLM. Para ello, no solo se eliminó la información personal, sino también la información confidencial de las series de entrenamiento, y se utilizó tanto el aprendizaje por refuerzo como el aprendizaje por refuerzo a partir de la retroalimentación humana (RLHF) para obtener modelos adaptados a las instrucciones que respondieran de manera responsable. Para la evaluación, se implementaron varios enfoques. Desde la creación manual de equipos en red hasta las pruebas contradictorias automatizadas y las evaluaciones de las capacidades de los modelos para actividades peligrosas.
Gemma y Géminis
¿Cuál es la diferencia entre Gemma y Gemini? ¿En qué se centra cada uno de ellos? Principalmente en su público objetivo, propósito y tamaño. Si bien Gemma es de código abierto y liviano, Gemini es propietario y pesado. Además, Gemma está pensada para que la utilicen desarrolladores e investigadores, pero Gemini para la investigación avanzada de la IA y para aplicaciones a gran escala. La siguiente tabla muestra una comparativa más detallada: Gema Gemini Compatibilidad exclusiva con JAX, PyTorch y TF de código abierto -sobre keras 3.0- restringida al ecosistema de Google
Aplicaciones y arquitecturas
Tanto Gemma como Gemini se pueden utilizar para:
- Generación de texto: responder preguntas, generar texto o resumirlo
- Procesamiento de imágenes: tarea de subtitulado de imágenes, tareas visuales de preguntas y respuestas
Ambas pueden ser una entidad en su solución, incluso si está creando con una arquitectura de microservicios o monolítica. Las principales diferencias se basan en sus responsabilidades y en su capacidad de personalización. Supongamos que trabajas en base a microservicios, en los que cada uno de ellos tiene un objetivo específico que cumplir.
Caso de uso de Gemma
Una arquitectura típica con Gemma requiere al menos un microservicio dedicado a alojar el modelo para interactuar con las solicitudes entrantes. Además, si pretendes mejorar tus respuestas basándote en conocimientos específicos (enfoque RAG), también necesitarás una base de datos vectorial. Por un lado, esto tiene la ventaja de ofrecer un nivel de personalización prácticamente infinito, desde mejorar el propio modelo con datos específicos hasta mejorar su rendimiento en lugar de añadir contexto al mensaje (incluidos los documentos referidos). Por otro lado, siempre hay una trampa, o al menos algo a tener en cuenta, y aquí no hay ninguna excepción. En este caso, no solo estás a cargo del desarrollo de la solución, sino también de la infraestructura necesaria para ejecutarla, donde probablemente se requieran recursos con GPU, lo que también repercute en la facturación.
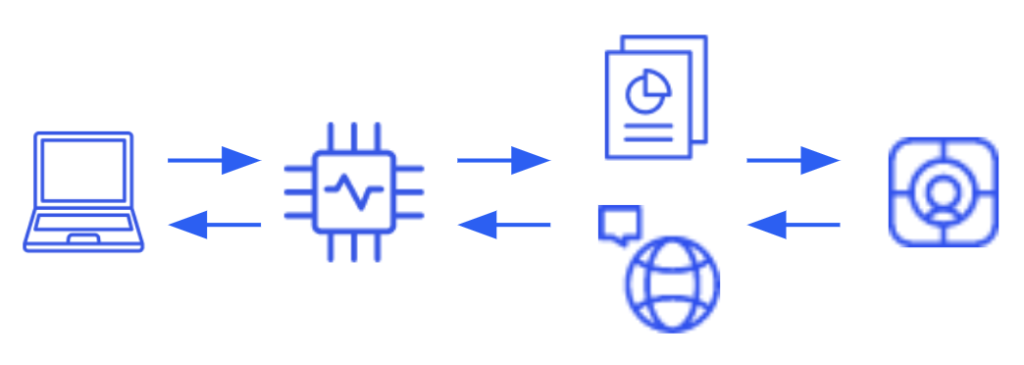
Caso de uso de Gemini
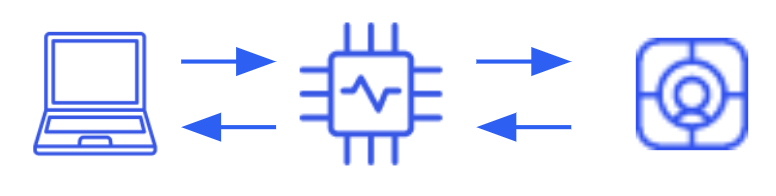
Una arquitectura típica con Gemini no es tan exigente como la anterior en cuanto a la infraestructura y los roles requeridos, ya que se podía acceder al modelo como un servicio externo -SaaS-. Bastará con centralizar la integración en un servicio o módulo. Esto tiene la ventaja de reducir las tareas en cuanto a la cantidad de horas de trabajo, la configuración de la infraestructura y el control de acceso, lo que resulta beneficioso si es crucial disponer de un tiempo de comercialización rápido, basta con acceder a Gemini con las credenciales adecuadas. Sin embargo, estás renunciando a tu capacidad de personalización. Aunque es capaz de adaptarse a las instrucciones, al final se trata de un texto limitado, por lo que trabajar con RAG para añadir documentos de dominios específicos al modelo o adaptarlo a sus necesidades no es una alternativa disponible.
Conjuntos de modelos Gemma
Gemma
Gemma es una maestría en derecho, con excelentes resultados en las tareas de generación de texto, que incluyen la respuesta a preguntas, el resumen y el razonamiento.
Pali Gemma
PaliGemma es un modelo ligero de lenguaje de visión abierto (VLM), por lo que toma imágenes y texto como entradas y puede responder preguntas sobre imágenes con detalle y contexto. Por lo tanto, el modelo es capaz de realizar análisis de imágenes, subtitular imágenes y vídeos cortos, detectar objetos y leer el texto incrustado en las imágenes. Hay dos versiones de PaliGemma, una de uso general -PaliGemma- y otra orientada a la investigación -PaliGemma-FT-. La primera es una excelente opción como punto de partida para adaptar modelos con precisión a una variedad de tareas; la segunda ya está adaptada a conjuntos de datos de investigación específicos. Algunas de las características de PaliGemma incluyen la comprensión multimodal, que permite comprender simultáneamente imágenes y textos, y la posibilidad de perfeccionar una amplia gama de tareas relacionadas con el lenguaje visual.
Código Gemma
CodeGemma es una colección de modelos que pueden realizar una variedad de tareas de codificación, como completar código intermedio, generar código, comprender el lenguaje natural, razonar matemáticamente y seguir instrucciones. En este caso, hay 3 configuraciones disponibles. Una variante preentrenada de 7B que se especializa en completar y generar código a partir de prefijos o sufijos de código, luego una versión de 7B ajustada a las instrucciones para chatear con el lenguaje natural al código y seguir las instrucciones y, por último, una variante preentrenada de 2B que proporciona una finalización de código más rápida. Entre las ventajas de CodeGemma se encuentran capacidades como la finalización y generación de código al dominar varios idiomas; la pila incluye Python, JS, Kava, Kotlin, C++, C#, Rust y Go, entre otras.
Gemma recurrente
RecurrentGemma es un modelo abierto basado en Griffin, ya que Gemma simple es ideal para las tareas de generación de texto, incluidas las respuestas a preguntas, el resumen y el razonamiento, pero con algunos beneficios adicionales, en particular, un menor uso de memoria, un mayor rendimiento y un mayor rendimiento.
Especificaciones y descripción general del arco
Gemma despegó del programa Gemini, que incluye el código, los datos, la arquitectura, el ajuste de las instrucciones, el aprendizaje por refuerzo a partir de la retroalimentación humana y las evaluaciones. Hay algunos aspectos que vale la pena mencionar, como: se utiliza la atención con múltiples consultas en lugar de la atención original con varios cabezales, la incrustación de RoPE en cada capa, la activación de GeGlu en lugar de ReLU y la ubicación del normalizador: normaliza la entrada y la salida de cada subcapa del transformador mediante RMSNorm.
Comparativo
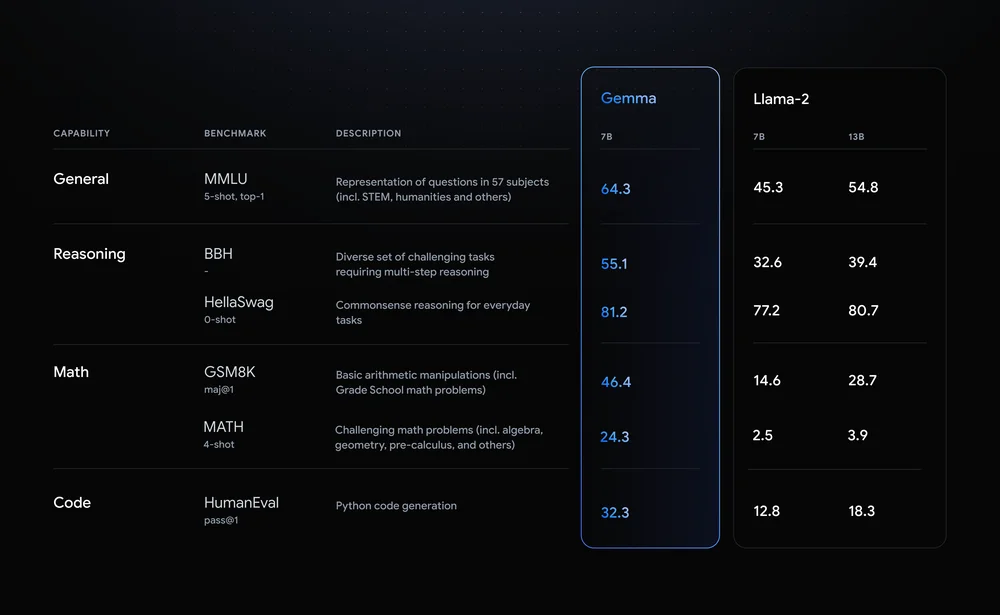
Hasta ahora, todo bien. Pero si en tus proyectos, iniciativas o lo que sea en lo que estés trabajando ya estás utilizando otros modelos de código abierto como Llama, quizás te preguntes por qué hacer el esfuerzo de dar un giro. Esta es la razón: Google comparó a Gemma 7B con el Llama 2 7B de Meta en varios campos, como el razonamiento, las matemáticas y la generación de código. Eche un vistazo a la siguiente tabla, en la que Gemma superó a Llama-2 en todos los aspectos.
Integración y adopción
Como ya se ha mencionado, la integración entre los modelos de Gemma y los principales marcos está lista para usarse, desde la exploración ingenua a través de Kaggle hasta las implementaciones de producción total. Sin embargo, eso no es todo, puedes combinar Gemma con HuggingFace para realizar tareas de ajuste e inferencia a través de sus Transformers, con NVIDIA para afinar también, con LangChain para crear aplicaciones con LLM -respaldado por Gemma-, con MongoDB para construir un sistema RAG y otros.
Conclusión
Hay una nueva familia de modelos disponible y deberías echarle un vistazo, ¡y probablemente empezar a usarla para añadir valor a tu idea/negocio o investigación! Este conjunto es de código abierto, cuenta con una comunidad estupenda y dinámica y permite ahorrar tanto recursos como sea posible, por lo que el despegue parece prometedor. De todos modos, la hoja de ruta siempre debe tenerse en cuenta para no fallar. Aquí es donde entran en escena las herramientas para las aproximaciones iniciales, también conocidas como los cuadernos disponibles, ¡son un buen entorno abierto para interactuar con Gemma!



.png)