.png)
Implementación de Llama2 con el servidor de inferencia Triton de NVIDIA




Introducción
Servidor de inferencia NVIDIA Triton es un software de servidor de inferencias de código abierto que permite la estandarización de la implementación de modelos de manera rápida y escalable, tanto en la CPU como en la GPU. Proporciona a los desarrolladores la libertad de elegir el marco adecuado para sus proyectos sin afectar a la implementación en producción. También ayuda a los desarrolladores a realizar inferencias de alto rendimiento en dispositivos en la nube, locales y periféricos. En este tutorial, nos centraremos en empaquetar e implementar de manera eficiente Modelos de lenguaje extensos (LLM), como Llama2 🦙, que utilizan NVIDIA Triton Inference Server 🧜 ♂️, lo que los hace listos para la producción en poco tiempo.
Despliegue de Llama2 usando Hugging Face
Para implementar un modelo Hugging Face, por ejemplo, Llama2, en NVIDIA Triton, hay dos enfoques posibles:
- Uso del backend Python de Triton
- Uso de los modelos Ensemble de Triton
Backend de Python
Para utilizar el backend de Python de Triton, el primer paso es definir el modelo mediante la clase TritonPythonModel con las siguientes funciones:
inicializar ()- Esta función se ejecuta cuando Triton carga el modelo. Por lo general, se usa para cargar cualquier modelo o dato necesario. El uso de esta función es opcional.ejecutar ()- Esta función se ejecuta en cada solicitud. Por lo general, contiene la lógica de canalización completa.
Este es un ejemplo completo de la implementación del modelo Llama2 en el ecosistema Triton: import app import os import json import triton_python_backend_utils como pb_utils import numpy as np import torch from transformers import pipeline, AutoTokenizer, AutomodelForCausalLM, TextiTeratorStreamer import huggingface_hub from threading import Thread huggingface_hub.login (ken= "») ## Agregue su clase de credenciales de HF TritonPythonModel: def initialize (self, args): self.tokenizer = autotokenizer.from_pretrained («meta-llama/llama-2-13b-chat-hf») self.model = automodelForCausalLm.from_ <s>pretrained («meta-llama/llama-2-13B-chat-HF», load_in_8bit= True, torch_dtype=torch.float16, device_map=' auto ') self.model.resize_token_embeddings (len (self.tokenizer)) def get_prompt (self, message: str, chat_history: list [tuple [str, str]], system_prompt: str) -> str: texts = [f' <s>[INST] < <SYS>>\n{system_prompt}\n< >\n\n'] # La primera entrada del usuario no está _eliminada</SYS> do_strip = False para user_input, response in chat_history: user_input = user_input.strip () si do_strip sino user_input do_strip = True texts.append () f' {user_input} [/INST] {response.strip (</s>)} [ INST] ') message = message.strip () si do_strip else message texts.append (f' {message} [/INST]') devuelve «.join (texts) def execute (self, requests): responses = [] para solicitud en solicitudes: # Decodifica el tensor de bytes en entradas de texto = pb_utils.get_input_tensor_by_name (request, «prompt») inputs = inputs.as_numpy () # Llama a la canalización de modelos DEFAULT_SYSTEM_PROMPT = «" "Eres un útil asistente de IA. Mantén respuestas cortas de no más de 2 oraciones. "» prompts = [self.get_prompt (i [0] .decode (), [], DEFAULT_SYSTEM_PROMPT) para i en las entradas] self.tokenizer.pad_token = «[PAD]» self.tokenizer.padding_side = «left» inputs = self.tokenizer (prompts, return_tensors_side = «left» inputs = self.tokenizer (prompts, return_tensors_side) ='pt', padding=true) .to ('cuda') output_sequences = self.model.generate (**inputs, do_sample=true, max_length=3584, temperature=0.01, top_p=1, top_k=20, repetition_penalty=1.1) output = self.tokenizer.batch_decode (output_sequences, skip_specialty=1.1) output = self.tokenizer.batch_decode (output_sequences, skip_specialty=1.1) _tokens=true) # Codifica el texto en un tensor de bytes para devolver la inferencia_ response = pb_utils.inferenceResponse (output_tensors= [PB_utils.Tensor («generated_text», np.array ([[o.encode () for o in output]]),) responses.append (inference_response) return answers def finalize (self, args): self.generator = None El segundo paso consiste en crear una configuración archivo para el modelo. El propósito de este archivo es que Triton comprenda cómo procesar el modelo. Por lo general, incluye especificaciones para las entradas y salidas de los modelos, el entorno de ejecución y los recursos de hardware necesarios. A continuación se muestra el archivo de configuración de nuestro ejemplo de Llama2: name: «llamav2" backend: «python» input [{name: «prompt» data_type: TYPE_STRING dims: [1]}] output [{name: «generated_text» data_type: TYPE_STRING dims: [1]}] instance_group [{kind: KIND_GPU}] Finalmente, los archivos deben seguir la siguiente estructura: model_repository/ |-- 1 | |-- model.py |-- config.pbtxt
Modelos de conjunto
Un modelo de conjunto representa una canalización de uno o más modelos de aprendizaje automático cuyas entradas y salidas están interconectadas. Este concepto también se puede aplicar a la lógica de preprocesamiento y posprocesamiento, tratándolos como bloques/modelos independientes que luego se ensamblan en Triton. Este enfoque requiere convertir primero el modelo en una representación serializada, como OnNx, antes de implementarlo en el servidor Triton. Una vez convertido, hay dos maneras de implementar el modelo en el servidor Triton:
- Tokenizador del lado del cliente: Solo el modelo se implementa en el servidor Triton, mientras que la tokenización se gestiona completamente en el lado del cliente.
- Tokenizador del lado del servidor: Tanto el tokenizador como el modelo se implementan en el servidor.
[caption id="attachment_2797" align="aligncenter» width="600"]

Tokenizador del lado del cliente frente al del servidor [/caption] El repositorio del modelo debe contener tres carpetas diferentes con la siguiente estructura: model_repository/ |-- ensemble_model | |-- 1 |-- config.pbtxt |-- model | |-- 1 | |-- llamav2.onnx | |-- config.pbtxt |-- tokenizer |-- 1 | |-- config.json | |-- config.json | |-- model.py | | |-- special_tokens_map.json | | |-- tokenizer.json | |-- config.pbtxt Repasemos el contenido y el propósito de cada una de estas carpetas:
- modelo_conjunto: Esta carpeta debe contener una subcarpeta llamada
1(que indica la versión del modelo), junto con unconfig.pbtxtarchivo. El archivo describe la lógica de cómo se pasa una solicitud de inferencia a través de los diferentes elementos de la canalización del conjunto (en este caso, el tokenizador y el modelo). name: «ensemble_model» max_batch_size: 0 platform: «ensemble» input [{name: «prompt» data_type: TYPE_STRING dims: [-1]}] output [{name: «output_0" data_type: TYPE_STRING dims: [-1]}] output [{name: «output_0" data_type: TYPE_STRING dims: [-1]}] output [{name: «output_0" data_type: TYPE_STRING dims: [-1]}] output [{name: «output_0" data_type: TYPE_STRING _FP32 dims: [-1, 2]}] ensemble_scheduling {step [{model_name: «tokenizer» model_version: -1 input_map {key: «prompt» value: «prompt»} output_map [{key: «input_ids» value: «input_ids»}, {key: «attention_mask» value:» attention_mask»}]}, {model_name: «model» model_version: -1 input_map [{key: «input_ids» value: «input_ids»}, {key: «attention_mask» value: «attention_mask»}] output_map {key: «output_0" value: «output_0"}}]}
- modelo: Esta carpeta también debe contener una subcarpeta denominada
1que contiene la representación serializada del modelo, y elconfig.pbtxtarchivo que contiene los detalles de configuración del modelo. name: «model» platform: «onnxruntime_onnx» backend: «onnxruntime» default_model_filename: «llamav2.onnx» max_batch_size: 0 input [{name: «input_ids» data_type: TYPE_INT64 dims: [-1, -1]}, {name: «attention_mask» data_type: TYPE_INT64 dims: [-1, -1]}] output [{name: «output_0" data_type: TYPE_FP32 dims: [-1, 2]}] instance_group [{count: 1 tipo: KIND_GPU}]
- tokenizador: Esta carpeta contiene una subcarpeta llamada
1que contiene el*.jsony*.txtarchivos generados por HuggingFace y unmodel.pyque contiene la lógica para invocar la tokenización del texto. import os escribiendo import Dict, List import numpy as np import triton_python_backend_utils como pb_utils de transformers import AutoTokenizer, PretrainedTokenizer, TensorType class TritonPythonModel: tokenizer: pretrainedTokenizer def initialize (self, args: Dict [str, str]) -> Ninguno: «"» Inicializa el proceso de tokenización:param args: arguments from Triton config file «"» # más variables en https://github.com/triton-inference-server/python_backend/blob/main/src/python.cc path: str = os.path. join (args ["model_repository"], args ["model_version"]) self.tokenizer = autotokenizer.from_pretrained (path) def execute (self, requests) -> «List [List [pb_utils.Tensor]]»: «"» Analiza y tokeniza cada solicitud:param requests: 1 o más solicitudes recibidas por el servidor Triton. :return: text as input tensors «"» responses = [] # para bucle para solicitudes por lotes (deshabilitado en nuestro caso) para solicitudes en solicitudes: # datos binarios devueltos a la cadena query = [t.decode («UTF-8") para t en pb_utils.get_input_tensor_by_name (request, «TEXT») .as_numpy () .tolist ()] tokens: Dict [str, np.ndarray] = self.tokenizer (text=query, return_tensors=TensorType.numpy) # tensorrt usa int32 como tipo de entrada, ort usa tokens int64 = {k: v.astype (np.int64) para k, v in tokens.items ()} # comunica los resultados de la tokenización a las salidas del servidor Triton = list () para innombre_de_entrada en self.tokenizer.model_input_names: tensor_input = pb_utils.Tensor (input_name, tokens [input_name]) outputs.append (tensor_input) inference_response = pb_utils.inferenceResponse (output_tensors=outputs) responses.append (inference_response) devuelve respuestas También debe incluir lasconfig.pbtxtespecificar los detalles de configuración de los tokenizadores. name: «tokenizer» max_batch_size: 0 backend: «python» input [{name: «prompt» data_type: TYPE_STRING dims: [-1]}] output [{name: «input_ids» data_type: TYPE_INT64 dims: [-1, -1]}, {name: «attention_mask» data_type: TYPE_INT64 dims: [-1, -1]}, {name: «attention_mask» data_type: TYPE_INT64 dims: [-1, -1]}, {name: «attention_mask» data_type: TYPE_INT64 dims: [-1, -1]} _INT64 dims: [-1, -1]}] instance_group [{count: 1 tipo: KIND_GPU}]
Ejecución de inferencias
Una vez desplegado el modelo, podemos proceder a configurar Triton Server. Esto se puede lograr con bastante facilidad utilizando la imagen de Docker prediseñada disponible en NVIDIA GPU Cloud (NGC).
Configuración del servidor
A continuación se detallan los pasos para poner en funcionamiento su servidor Triton.
- Ejecute el contenedor docker para Triton Server con el siguiente comando: docker run --gpus=all -it --shm-size=1g --rm -p 8000:8000 -p 8001:8001 -p 8002:8002 -v $ {PWD} :/workspace/ -v $ {PWD} /model_repository: /models nvcr.io/nvidia/tritonserver:23.08-py3 bas Triton expone tres puertos de forma predeterminada, que se especifican en el comando docker run:
- 8000: solicitudes de API REST HTTP
- 8001: Solicitudes de gRPC
- 8002: Métricas y monitorización mediante Prometeo
- Una vez dentro del contenedor, instala las dependencias necesarias para ejecutar tu modelo: pip install app pip install torch pip install transformers pip install huggingface_hub pip install accelerate pip install bitsandbytes pip install scipy
- Con las dependencias establecidas, ejecuta el siguiente comando para ejecutar Triton Server: docker run --gpus all -it --rm -v $ {PWD} :/work -w /work nvcr.io/nvidia/tritonserver:23.08-py3. /gen_vllm_env.sh
Configuración del cliente
En cuanto a la configuración del cliente, los clientes pueden interactuar con Triton Server mediante Protocolo HTTP/REST o Protocolo GRPC. El punto final depende del protocolo y la versión de API que estemos utilizando.
- Para HTTP necesitaremos usar el
host local: 8000punto final, incluya el nombre del modelo en la URL y los datos de entrada en el cuerpo de la solicitud. He aquí un ejemplo en el que se usa curl: curl --location --request POST 'http://localhost:8000/v2/models/llamav2/infer'\ --header 'Content-Type: application/json'\ --data-raw '{«inputs»: [{«name»: «prompt», «shape»: [1], «datatype»: «BYTES», «data»: ["Hello"]}]}' - Para gRPC, necesitaremos usar el punto final localhost:8001.
La configuración de Triton Client también se puede realizar configurando una imagen de Docker prediseñada, como se muestra a continuación:
- Ejecute el contenedor docker para Triton Client docker run -it --net=host -v $ {PWD} :/workspace/ nvcr.io/nvidia/tritonserver:23.08-py3-sdk bash
- A continuación, ejecute el script de inferencia. Este es un ejemplo de script de Python que utiliza solicitudes HTTP: desde tritonclient.utils import * import tritonclient.http como httpclient import time import numpy as np tm1 = time.perf_counter () con HttpClient.InferenceServerClient (url="localhost:8000", verbose=false, concurrency=32) como cliente: # Define input config input_text = [» Dónde está ¿Uruguay? "] , ["¿Quién es George Washington?"] , ["¿Quién es Lionel Messi?"] ,] text_obj = np.array (input_text, dtype="object») #.reshape (2,1) inputs = [HttpClient.inferInput («prompt», text_obj.shape, np_to_triton_dtype (text_obj.dtype)) .set_data_from_numpy (text_obj),] # Definir salidas de configuración de salida = [HttpClient.numpy (text_obj) inferRequestedOutput («generated_text»),] # Hit triton server n_requests = 1 responses = [] for i in range (n_requests): responses.append (client.async_infer ('llamav2', model_version='1', inputs=inputs, outputs=outputs)) para r en respuestas: result = r.get_result () content = result.as_numpy ('texto_generado') print (contenido) tm2 = time.perf_counter () print («Tiempo total transcurrido: {tm2-tm 1:0.2 f} segundos»)
Ejecución simultánea del modelo
Con Triton, puede ejecutar varios modelos o varias instancias del mismo modelo con los mismos recursos de GPU. Para habilitarlo, basta con añadir la siguiente línea en el archivo de configuración del modelo, justo debajo del grupo_instancia section: instance_group [{count: 2 kind: KIND_GPU}] Puedes cambiar el recuento de inferencias permitidas para la misma instancia del modelo y observar cómo afecta al rendimiento. Si tienes acceso a varias GPU, también puedes cambiar la grupo_instancia ajustes para colocar varias instancias de ejecución en diferentes GPU. Por ejemplo, la siguiente configuración colocará dos instancias de ejecución en la GPU 0 y tres instancias de ejecución en las GPU 1 y 2. instance_group [{count: 2 kind: KIND_GPU gpus: [0]}, {count: 3 kind: KIND_GPU gpus: [1, 2]}]
Procesamiento dinámico por lotes
Triton proporciona una función de procesamiento por lotes dinámico, que permite combinar varias solicitudes en la ejecución del mismo modelo, lo que aumenta considerablemente el rendimiento de la inferencia. El siguiente diagrama muestra cómo funciona esta función. [caption id="attachment_2853" align="aligncenter» width="804"]
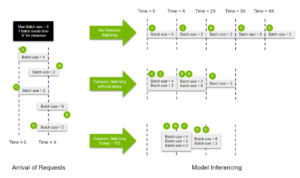
Flujo de procesamiento dinámico por lotes de NVIDIA Triton [/caption] Habilitación procesamiento por lotes dinámico agrupa secuencias consecutivas dentro del límite máximo de tamaño de lote, lo que permite empaquetar las solicitudes en la GPU de manera más eficiente. Además, puede asignar un retraso limitado al programador, lo que le permitirá recopilar más solicitudes de inferencia para que las utilice el mezclador dinámico. Este es un ejemplo de configuración del procesamiento dinámico por lotes para nuestro modelo Llama2: name: «llamav2" backend: «python» max_batch_size: 8 input [{name: «prompt» data_type: TYPE_STRING dims: [-1]}] output [{name: «generated_text» data_type: TYPE_STRING dims: [-1]}] instance_group [{kind: KIND_GPU}] dynamic_batching {preferred_batch_size: [2, 4, 8] max_queue_delay_microseconds: 300}
- El
tamaño_máx. de lotela propiedad establece el tamaño máximo de lote permitido por el modelo - El
[-1]en las dimensiones de entrada y salida indica que esas dimensiones son, de hecho, dinámicas y pueden cambiar de una solicitud a otra. - La sección dynamic_batching habilita el procesamiento por lotes dinámico para el modelo. También permite configurar otras propiedades, como:
- La propiedad preferred_batch_size que indica los tamaños de lote que el dosificador dinámico debe intentar crear.
- El
retardo máximo de cola en microsegundosLa propiedad determina el tiempo de retraso máximo permitido en el planificador para que otras solicitudes se unan al lote dinámico.
Procesamiento por lotes irregular
Las solicitudes se pueden agrupar en lotes de forma dinámica cuando todas las entradas comparten la misma forma. En situaciones en las que las formas de entrada difieren con frecuencia, se debe aplicar un relleno para garantizar que las formas coincidan y poder utilizar el procesamiento por lotes dinámico. Procesamiento por lotes irregular es una función que nos permite evitar este relleno especificando cuál de las entradas no requiere la verificación de forma en el archivo de configuración del modelo: input [{name: «prompt» data_type: TYPE_STRING dims: [-1] allow_ragged_batch: true}]
Implementación de Llama2 mediante vLLM
VLLM es una biblioteca de inferencia y servicio de LLM de código abierto. Utiliza Atención a la página, un nuevo algoritmo de atención que gestiona eficazmente las claves y valores de atención, lo que permite lograr un rendimiento excepcionalmente alto sin requerir ningún cambio en la arquitectura del modelo. También es compatible procesamiento por lotes continuo de solicitudes entrantes que permiten un mayor uso de la GPU. ¿Qué es el procesamiento continuo por lotes? La idea se presentó por primera vez en el documento Orca: un sistema de servicio distribuido para modelos generativos basados en transformadores. En lugar de esperar a que todas las secuencias de un lote terminen de generarse, emplea una programación a nivel de iteración, en la que el tamaño del lote se determina para cada iteración. Como resultado, una vez que se completa una secuencia de un lote, se puede insertar una nueva secuencia en su lugar, lo que permite un mayor uso de la GPU. La imagen pretende ilustrar con más detalle la diferencia entre el procesamiento por lotes estático y continuo. Cada celda corresponde a un token. Las casillas amarillas representan los símbolos de aviso, las celdas azules representan los símbolos generados y las celdas rojas representan los símbolos de final de secuencia. [caption id="attachment_2850" align="aligncenter» width="957"]

Procesamiento por lotes estático frente a procesamiento por lotes continuo [/caption] En procesamiento por lotes estático, el proceso de generación concluye cuando finaliza la última secuencia (es decir, la secuencia S2), lo que resulta en una subutilización de la capacidad de la GPU. Por otro lado, procesamiento por lotes continuo funciona de manera diferente. Tan pronto como una secuencia emite un símbolo de fin de secuencia, podemos insertar sin problemas una nueva secuencia en su lugar, lo que garantiza una utilización óptima de la GPU. Esto se puede observar en la inserción de las secuencias S5, S6 y S7. Desventajas de vLLM:
- No permite el uso de varias GPU
- No permite la cuantificación
Ejecución de inferencias con vLLM
El procedimiento es similar al que hemos visto antes.
- Cree una nueva imagen de contenedor de Docker derivada de
tritonserver: 23.08-py3docker build -t tritonserver_vllm. - Prepare el repositorio y los archivos del modelo:
- Los archivos deben seguir la siguiente estructura: model_repository/ |-- vllm |-- 1 | |-- model.py |-- config.pbtxt |-- vllm_engine_args.json
- El
vllm_engine_args.jsonel archivo debe contener lo siguiente: {«model»: «meta-llama/llama-2-7b-chat-hf», «disable_log_requests»: «true»} - Este es un ejemplo del archivo de configuración. Tenga en cuenta que el procesamiento dinámico por lotes de Triton está deshabilitado (
tamaño_máx. de lote = 0) para permitir que vLLM gestione el procesamiento por lotes por sí solo. name: backend «vllm»: «python» max_batch_size: 0 model_transaction_policy {decoupl:True} input [{name: «PROMPT» data_type: TYPE_STRING dims: [-1]}] output [{name: «generated_text» data_type: TYPE_STRING dims: [-1]}] instance_group [{count: 1 tipo: KIND_MODEL}] - El
model.pyEl archivo pretende definir el modelo utilizando la clase TritonPythonModel como en el enfoque de backend de Python. Aquí puede encontrar un ejemplo sobre cómo configurar un modelo usando vLLM.
- Inicie el servidor Triton: docker run --gpus all -it --rm -p 8001:8001 --shm-size=1g --ulimit memlock=-1 --ulimit stack=67108864 -v $ {PWD} :/work -w /work tritonserver_vllm tritonserver --model-store. /model_repository
- Inicie el cliente Triton y ejecute su script de inferencia. docker run --gpus all -it --rm -v $ {PWD} :/work -w /work nvcr.io/nvidia/tritonserver:23.08-py3. /gen_vllm_env.sh
Aquí es un ejemplo de secuencia de comandos de Python que utiliza la biblioteca cliente gRPC.
Resultados
Hemos realizado y medido las capacidades de inferencia de Triton para las implementaciones de los modelos HuggingFace y vLLM. En particular, nos centramos especialmente en probar las funciones de ejecución simultánea de modelos y procesamiento dinámico por lotes de Triton. Para ello, utilizamos el modelo Llama chat 7B de Meta y lo implementamos en una instancia EC2 g5.xlarge equipada con una GPU de 24 GB.
Rendimiento de ejecución simultánea
1 instancia 2 instancias Tiempo de ejecución 9,79 s Rendimiento de 6,72 s 10,6 token/s 15,5 token/s
(*) Para ajustar las instancias del modelo a la GPU disponible, tuvimos que hacer una cuantificación de 8 bits
Rendimiento dinámico de procesamiento por lotes
Tamaño del lote = 1 Tamaño del lote = 8 Tiempo de ejecución de HFVLLMHFVLLM 9,79 s 2,06 s 17.07s Rendimiento de 3.12 s 10,6 token/s 50 token/s 66,5 token/s 363 token (s)
Observaciones finales
A lo largo de este tutorial, hemos revisado varias técnicas para implementar modelos de aprendizaje automático en el ecosistema Triton, lo que nos permitió acelerar el tiempo de inferencia hasta x7 sin perder precisión. Los siguientes son algunos de los principales resultados obtenidos durante nuestras pruebas:
- Al aprovechar la función de ejecución simultánea de modelos de Triton, hemos obtenido un aumento de x1.5 en rendimiento mediante la implementación de dos instancias paralelas del modelo Llama2 7B cuantificadas a 8 bits.
- Implementación procesamiento por lotes dinámico agregó un adicional aumento x5 en el rendimiento del modelo.
- Por último, la incorporación del marco vLLM superó los resultados del procesamiento dinámico por lotes con un aumento x7. Como inconveniente, vLLM no permite la cuantificación del modelo, por lo que no pudimos probar instancias simultáneas de Llama2 7B en este marco debido a requisitos computacionales.
Para profundizar en estos ejemplos, echa un vistazo a nuestra repo! 🔗
Referencias
- Implementación de modelos de HuggingFace Implementación de modelos de HuggingFace
- Cómo implementar modelos de caras abrazadas en el servidor de inferencia Triton de Nvidia a escala
- Modelo Triton Ensemble para implementar Transformers en producción
- vLLM: servicio de LLM fácil, rápido y económico con PageDAttention



.png)