.png)
Implantando o Llama2 com o NVIDIA Triton Inference Server




Intro
Servidor de inferência NVIDIA Triton é um software de servidor de inferência de código aberto que permite a padronização da implantação de modelos de maneira rápida e escalável, tanto na CPU quanto na GPU. Ele oferece aos desenvolvedores a liberdade de escolher a estrutura certa para seus projetos sem afetar a implantação da produção. Também ajuda os desenvolvedores a oferecer inferência de alto desempenho em dispositivos na nuvem, no local e de ponta. Neste tutorial, vamos nos concentrar em empacotar e implantar com eficiência Modelos de linguagem grande (LLM), como o Llama2 🦙, usando o NVIDIA Triton Inference Server 🧜 ♂️, deixando-os prontos para produção em pouco tempo.
Implantando o Llama2 usando o Hugging Face
Para implantar um modelo Hugging Face, por exemplo, Llama2, na NVIDIA Triton, há duas abordagens possíveis:
- Usando o backend Python da Triton
- Usando os modelos Triton's Ensemble
Backend Python
Para usar o backend python do Triton, a primeira etapa é definir o modelo usando a classe TritonPythonModel com as seguintes funções:
inicializar ()- Essa função é executada quando o Triton carrega o modelo. Geralmente é usado para carregar qualquer modelo ou dado necessário. O uso dessa função é opcional.executar ()- Essa função é executada a cada solicitação. Geralmente, ele contém a lógica completa do pipeline.
Aqui está um exemplo completo da implementação do modelo Llama2 no ecossistema Triton: importar aplicativo os importar json importar triton_python_backend_utils como pb_utils importar numpy como np importar tocha do pipeline de importação de transformadores, AutoTokenizer, AutoModelForCausalLM, TextIteratorStreamer import huggingface_hub do threading import Thread huggingface_hub b.login (token= "”) ## Adicione sua classe de credenciais HF TritonPythonModel: def initialize (self, args): self.tokenizer = autotokenizer.from_pretrained (“meta-llama/llama-2-13b-chat-hf”) self.model = automodelForCausalLm.from_ <s><SYS>pré-treinado (“meta-llama/llama-2-13b-chat-hf”, load_in_8bit= True, torch_dtype=torch.float16, device_map='auto') self.model.resize_token_embeddings (len (self.tokenizer)) def get_prompt (self, mensagem: str, chat_history: list [ple [str, str]], system_prompt: str) -> str: texts = [f' [INST] < >\n{system_prompt}\n< >\n\n'] # A primeira entrada do usuário é _não_ removida do_strip = False para user_input, resposta em chat_history: user_input = user_input.strip () if do_strip else user_history input do_strip = Textos verdadeiros.append (f' {user_input} [/INST] {response.strip ()} [</SYS></s><s> INST] ') message = message.strip () if do_strip else message texts.append (f' {message} [/INST]') return “.join (texts) def execute (self, requests): answers = [] para solicitação em solicitações: # Decodifique o tensor de bytes em entradas de texto = pb_utils.get_input_tensor_by_name (, “prompt”) inputs = inputs.as_numpy () # Chame o pipeline do modelo DEFAULT_SYSTEM_PROMPT = “" "Você é um assistente de IA útil. Mantenha respostas curtas de no máximo 2 frases." "” prompts = [self.get_prompt (i [0] .decode (), [], DEFAULT_SYSTEM_PROMPT) para i nas entradas] self.tokenizer.pad_token = “[PAD]” self.tokenizer.padding_side = “left” inputs = self.tokenizer (prompts, return_tensors='pt', padding=true) .to ('cuda') output_sequences = self.model.generate (**inputs, do_sample=true, max_length=3584, temperatura=0,01, top_p=1, top_k=20, repetition_penalty=1.1) saída = self.tokenizer.batch_decode (output_sequences, SKIP_SPECIAL_TOKENS = true) # Codifique o texto em tensor de bytes para enviar de volta a inferência_ response = pb_utils.inferenceResponse (output_tensors= [pb_utils.tensor (“generated_text”, np.array ([[o.encode () for o in output]]),)]) responses.append (inference_response) return answers def finalize (self, args): self.generator = None A segunda etapa é criar uma configuração arquivo para o modelo. O objetivo deste arquivo é que o Triton entenda como processar o modelo. Geralmente inclui especificações para as entradas e saídas dos modelos, o ambiente de execução e os recursos de hardware necessários. Abaixo está o arquivo de configuração do nosso exemplo do Llama2: nome: backend “llamav2": entrada “python” [{name: “prompt” data_type: TYPE_STRING dims: [1]}] output [{name: “generated_text” data_type: TYPE_STRING dims: [1]}] instance_group [{kind: KIND_GPU}] Finalmente, os arquivos deve seguir a seguinte estrutura: model_repository/ |-- 1 | |-- model.py |-- config.pbtxt
Modelos de conjunto
Um modelo de conjunto representa um pipeline de um ou mais modelos de aprendizado de máquina cujas entradas e saídas estão interconectadas. Esse conceito também pode ser aplicado à lógica de pré e pós-processamento, tratando-os como blocos/modelos independentes que são então montados juntos no Triton. Essa abordagem exige primeiro a conversão do modelo em uma representação serializada, como o OnNX, antes de implantá-lo no servidor Triton. Depois de convertido, há duas maneiras de implantar o modelo no servidor Triton:
- Tokenizador do lado do cliente: Somente o modelo é implantado no servidor Triton, enquanto a tokenização é feita inteiramente no lado do cliente.
- Tokenizador do lado do servidor: Tanto o tokenizador quanto o modelo são implantados no servidor.
[caption id="attachment_2797" align="aligncenter” width="600"]

Tokenizador do lado do cliente versus do lado do servidor [/caption] O repositório modelo deve conter três pastas diferentes com a seguinte estrutura: model_repository/ |-- ensemble_model | |-- 1 | |-- config.pbtxt |-- model | |-- 1 | |-- llamav2.onnx | |-- config.pbtxt |-- tokenizer | |-- 1 | | |-- config.json | | |-- model.py | | |-- special_tokens_map.json | | |-- tokenizer.json | |-- config.pbtxt Vamos examinar o conteúdo e o propósito de cada uma dessas pastas:
- modelo_conjunto: Essa pasta deve conter uma subpasta chamada
1(denotando a versão do modelo), junto com umconfig.pbtxtarquivo. O arquivo descreve a lógica de como uma solicitação de inferência é passada pelos diferentes elementos do pipeline de conjunto (neste caso, o tokenizador e o modelo). nome: “ensemble_model” max_batch_size: 0 platform: “ensemble” input [{name: “prompt” data_type: TYPE_STRING dims: [-1]}] output [{name: “output_0" data_type: TYPE_FP32 dims: [-1, 2]}] ensemble_scheduling {step [{model_name: “tokenizer” model_version: -1 input_map {key: “prompt” value: “prompt”} output_map [{key: “input_ids” value: “input_ids”}, {key: “attention_mask” value:” attention_mask”}]}, {model_name: “model” model_version: -1 input_map [{key: “input_ids” value: “input_ids”}, {key: “attention_mask” value: “attention_mask”}] output_map {key: “output_0"}}
- modelo: Essa pasta também deve conter uma subpasta chamada
1que contém a representação serializada do modelo e aconfig.pbtxtarquivo que contém os detalhes de configuração dos modelos. nome: plataforma “modelo”: backend “onnxruntime_onnx”: “onnxruntime” default_model_filename: “llamav2.onnx” max_batch_size: 0 input [{name: “input_ids” data_type: TYPE_INT64 dims: [-1, -1]}, {name: Tipo de dados “attention_mask”: TYPE_INT64 dims: [-1, -1]}] saída [{name: “output_0" data_type: TYPE_FP32 dims: [-1, 2]}] instance_group [{count: 1 tipo: KIND_GPU}]
- tokenizador: Essa pasta contém uma subpasta chamada
1que contém o*.jsone*.txtarquivos gerados pelo HuggingFace e ummodel.pyque contém a lógica para invocar a tokenização do texto. Importe os digitando import Dict, Liste import numpy as np import triton_python_backend_utils como pb_utils dos transformadores import AutoTokenizer, PretrainedTokenizer, classe TensorType TritonPythonModel: tokenizer: pretrainedTokenizer def initialize (self, args: Dict [str, str]) -> Nenhum: “"” Inicialize o processo de tokenização:param args: argumentos do arquivo de configuração do Triton “"” # mais variáveis em https://github.com/triton-inference-server/python_backend/blob/main/src/python.cc path: str = os.path. join (args ["model_repository"], args ["model_version"]) self.tokenizer = autotokenizer.from_pretrained (path) def execute (self, requests) -> “List [List [pb_utils.tensor]]”: “"” Analise e tokenize cada solicitação:solicitações de parâmetros: 1 ou mais solicitações recebidas pelo servidor Triton. :return: texto como tensores de entrada “"” answers = [] # para loop para solicitações em lote (desativado em nosso caso) para solicitação em solicitações: # dados binários digitados de volta para string query = [t.decode (“UTF-8") para t em pb_utils.get_input_tensor_by_name (request, “TEXT”) .as_numpy () .tolist ()] tokens: Dict [str, np.ndarray] = self.tokenizer (text=query, return_tensors=tensortype.numpy) # tensorrt usa int32 como tipo de entrada, ort usa int64 tokens = {k: v.astype (np.int64) para k, v em tokens.items ()} # comunica os resultados da tokenização às saídas do servidor Triton = list () para input_name em self.tokenizer.model_input_names: tensor_input = pb_utils.tensor (input_name, tokens [input_name]) outputs.append (tensor_input) inference_response = pb_utils.inferenceResponse (output_tensors=outputs) responses.append (inference_response) retornar respostas Também deve inclua oconfig.pbtxtespecificando os detalhes da configuração dos tokenizadores. nome: “tokenizer” max_batch_size: 0 backend: entrada “python” [{name: “prompt” data_type: TYPE_STRING dims: [-1]}] output [{name: “input_ids” data_type: TYPE_INT64 dims: [-1, -1]}, {name: “attention_mask” data_type a_type: TYPE_INT64 dims: [-1, -1]}] instance_group [{count: 1 tipo: KIND_GPU}]
Executando inferências
Depois que o modelo for implantado, podemos prosseguir com a configuração do Triton Server. Isso pode ser feito com bastante facilidade usando a imagem pré-criada do Docker disponível na NVIDIA GPU Cloud (NGC).
Configuração do servidor
Abaixo estão as etapas para colocar seu servidor Triton em funcionamento.
- Execute o contêiner docker para o Triton Server usando o seguinte comando: docker run --gpus=all -it --shm-size=1g --rm -p 8000:8000 -p 8001:8001 -p 8002:8002 -v $ {PWD} :/workspace/ -v $ {PWD} /model_repository: /models nvcr.io/nvidia/tritonseritonseriton ver:23.08-py3 bas Triton expõe três portas por padrão, que são especificadas no comando docker run:
- 8000: solicitações da API HTTP REST
- 8001: solicitações gRPC
- 8002: Métricas e monitoramento via Prometeu
- Uma vez dentro do contêiner, instale as dependências necessárias para executar seu modelo: pip install app pip install torch pip install transformers pip install huggingface_hub pip install accelerate pip install bitsandbytes pip install scipy
- Com as dependências estabelecidas, execute o seguinte comando para executar o Triton Server: docker run --gpus all -it --rm -v $ {PWD} :/work -w /work nvcr.io/nvidia/tritonserver:23.08-py3. /gen_vllm_env.sh
Configuração do cliente
Quanto à configuração do cliente, os clientes podem interagir com o Triton Server usando Protocolo HTTP/REST ou Protocolo GRPC. O endpoint depende do protocolo e da versão da API que estamos usando.
- Para HTTP, precisaremos usar o
host local: 8000endpoint, inclua o nome do modelo na URL e os dados de entrada no corpo da solicitação. Aqui está um exemplo usando curl: curl --location --request POST 'http://localhost:8000/v2/models/llamav2/infer'\ --header 'Content-Type: application/json'\ --data-raw '{“inputs”: [{“name”: “prompt”, “shape”: [1], “datatype”: “BYTES”, “data”: ["Olá"]}]}' - Para gRPC, precisaremos usar o endpoint localhost:8001.
A configuração do Triton Client também pode ser feita configurando uma imagem Docker pré-construída, conforme mostrado abaixo:
- Execute o contêiner docker para o Triton Client docker run -it --net=host -v $ {PWD} :/workspace/ nvcr.io/nvidia/tritonserver:23.08-py3-sdk bash
- Em seguida, execute seu script de inferência. Aqui está um exemplo de script Python usando solicitações HTTP: de tritonclient.utils import * import tritonclient.http como httpclient import time import numpy as np tm1 = time.perf_counter () com httpClient.inferenceServerClient (url="localhost:8000", verbose=false, concurrency=32) como cliente: # Defina a configuração de entrada g input_text = [["Onde fica o Uruguai?"] , ["Quem é George Washington?"] , ["Quem é Lionel Messi?"] ,] text_obj = np.array (input_text, dtype="object”) #.reshape (2,1) inputs = [httpClient.inferInput (“prompt”, text_obj.shape, np_to_triton_dtype (text_obj.dtype)) .set_data_from_numpy (text_obj),] # Defina saídas de configuração de saída = [HttpClient.inferRequestedOutput (“generated_text”),] # Acesse o servidor triton n_requests = 1 respostas = [] para i no intervalo (n_requests): responses.append (client.async_infer ('llamav2', model_version='1', inputs=inputs, outputs=inputs_inputs_infer ('llamav2', model_version='1') =outputs)) para r nas respostas: result = r.get_result () content = result.as_numpy ('generated_text') print (content) tm2 = time.perf_counter () print (F'Tempo total decorrido: {tm2-tm 1:0,2 f} segundos')
Execução simultânea do modelo
Com o Triton, você pode executar vários modelos ou várias instâncias do mesmo modelo usando os mesmos recursos de GPU. Para habilitar isso, basta adicionar a seguinte linha no arquivo de configuração do modelo, logo abaixo do grupo_instância section: instance_group [{count: 2 kind: KIND_GPU}] Você pode alterar a contagem de inferências permitidas para a mesma instância do modelo e observar como isso afeta o desempenho. Se você tiver acesso a várias GPUs, também poderá alterar o grupo_instância configurações para colocar várias instâncias de execução em diferentes GPUs. Por exemplo, a configuração a seguir colocará duas instâncias de execução na GPU 0 e três instâncias de execução nas GPUs 1 e 2. instance_group [{count: 2 kind: KIND_GPU gpus: [0]}, {count: 3 kind: KIND_GPU gpus: [1, 2]}]
Dosagem dinâmica
O Triton fornece um recurso de lote dinâmico, que permite combinar várias solicitações na mesma execução do modelo, aumentando substancialmente a taxa de transferência da inferência. O diagrama abaixo mostra como esse recurso funciona. [caption id="attachment_2853" align="aligncenter” width="804"]
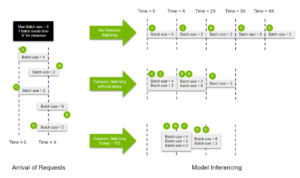
Habilitando o fluxo dinâmico de lotes do NVIDIA Triton [/caption] dosagem dinâmica agrupa sequências consecutivas dentro do limite máximo de tamanho do lote, resultando em um empacotamento mais eficiente de solicitações na GPU. Além disso, você pode alocar um atraso limitado para o agendador, permitindo que ele colete mais solicitações de inferência para o batcher dinâmico usar. Aqui está um exemplo de configuração de lote dinâmico para nosso modelo Llama2: nome: backend “llamav2": “python” max_batch_size: 8 entradas [{name: “prompt” data_type: TYPE_STRING dims: [-1]}] output [{name: “generated_text” data_type: TYPE_STRING dims: [-1]}] instance_group [{tipo: KIND_GPU}] dynamic_batching {preferred_batch_size: [2, 4, 8] max_queue_delay_microseconds: 300}
- O
tamanho máximo do lotepropriedade define o tamanho máximo do lote permitido pelo modelo - O
[-1]nas dimensões de entrada e saída indica que essas dimensões são de fato dinâmicas e podem mudar de uma solicitação para outra. - A seção dynamic_batching permite o agrupamento dinâmico em lotes para o modelo. Também permite configurar outras propriedades, como:
- A propriedade preferred_batch_size que indica os tamanhos dos lotes que o batcher dinâmico deve tentar criar.
- O
max_queue_delay_microssegundosa propriedade determina o tempo máximo de atraso permitido no agendador para que outras solicitações ingressem no lote dinâmico.
Dosagem irregular
As solicitações podem ser agrupadas dinamicamente quando todas as entradas compartilham a mesma forma. Em situações em que as formas de entrada frequentemente diferem, o preenchimento deve ser aplicado para garantir que as formas correspondam e para poder usar o agrupamento dinâmico. Dosagem irregular é um recurso que nos permite evitar esse preenchimento, especificando quais das entradas não exigem a verificação de forma no arquivo de configuração do modelo: input [{name: “prompt” data_type: TYPE_STRING dims: [-1] allow_ragged_batch: true}]
Implantando o Llama2 usando vLLM
vLLM é uma biblioteca de inferência e serviço de LLM de código aberto. Ele utiliza Atenção paginada, um novo algoritmo de atenção que gerencia com eficácia as chaves e os valores da atenção, fazendo com que ele alcance um rendimento excepcionalmente alto sem exigir nenhuma alteração na arquitetura do modelo. Ele também suporta dosagem contínua de solicitações recebidas, permitindo maior utilização da GPU. O que é dosagem contínua? A ideia foi apresentada pela primeira vez no artigo Orca: um sistema de serviço distribuído para modelos generativos baseados em transformadores. Em vez de esperar que todas as sequências em um lote terminem a geração, ele emprega o agendamento em nível de iteração, em que o tamanho do lote é determinado para cada iteração. Como resultado, quando uma sequência em um lote é concluída, uma nova sequência pode ser inserida em seu lugar, permitindo maior uso da GPU. A imagem pretende ilustrar ainda mais a diferença entre dosagem estática e contínua. Cada célula corresponde a um token. As células amarelas representam tokens imediatos, as células azuis representam os tokens gerados e os glóbulos vermelhos representam os tokens de fim de sequência. [caption id="attachment_2850" align="aligncenter” width="957"]

Dosagem estática versus dosagem contínua [/caption] Em dosagem estática, o processo de geração termina quando a última sequência (ou seja, sequência S2) termina, resultando na subutilização da capacidade da GPU. Por outro lado, dosagem contínua opera de forma diferente. Assim que uma sequência emite um token de fim de sequência, podemos inserir facilmente uma nova sequência em seu lugar, garantindo a utilização ideal da GPU. Isso pode ser visto na inserção das sequências S5, S6 e S7. Desvantagens do vLLM:
- Não permite o uso múltiplo de GPU
- Não permite quantização
Executando inferências com vLLM
O procedimento é semelhante ao que vimos antes.
- Crie uma nova imagem de contêiner docker derivada de
servidor triton: 23.08-py3docker build -t tritonserver_vllm. - Prepare o repositório e os arquivos do modelo:
- Os arquivos devem seguir a seguinte estrutura: model_repository/ |-- vllm |-- 1 | |-- model.py |-- config.pbtxt |-- vllm_engine_args.json
- O
vllm_engine_args.jsono arquivo deve conter o seguinte: {“model”: “meta-llama/llama-2-7b-chat-hf”, “disable_log_requests”: “true”} - Aqui está um exemplo do arquivo de configuração, observe que o lote dinâmico do Triton está desativado (
tamanho_máximo do lote = 0) para permitir que o vLLM gerencie o lote sozinho. nome: backend “vllm”: “python” max_batch_size: 0 model_transaction_policy {decoupled: True} input [{name: “PROMPT” data_type: TYPE_STRING dims: [-1]}] output [{name: “generated_text” data_type: TYPE_STRING dims: [-1]}] output [{name: “generated_text” data_type: TYPE_STRING dims: [-1]}] output [{name: “generated_text” data_type: TYPE_STRING dims: [-1]}]]}] instance_group [{count: 1 tipo: KIND_MODEL}] - O
model.pyfile pretende definir o modelo usando a classe TritonPythonModel como na abordagem de backend do Python. Aqui você pode encontrar um exemplo de como configurar um modelo usando o vLLM.
- Inicie o servidor Triton: docker run --gpus all -it --rm -p 8001:8001 --shm-size=1g --ulimit memlock=-1 --ulimit stack=67108864 -v $ {PWD} :/work -w /work tritonserver_vllm tritonserver --model-store. /model_repositório
- Inicie o cliente Triton e execute seu script de inferência. docker run --gpus all -it --rm -v $ {PWD} :/work -w /work nvcr.io/nvidia/tritonserver:23.08-py3. /gen_vllm_env.sh
Aqui é um exemplo de script em Python usando a biblioteca cliente gRPC.
Resultados
Realizamos e medimos os recursos de inferência da Triton para implementações de modelos HuggingFace e vLLM. Em particular, nos concentramos especialmente em testar a execução simultânea do modelo e os recursos de dosagem dinâmica da Triton. Para fazer isso, usamos o modelo Llama chat 7B da Meta e o implantamos em uma instância EC2 g5.xlarge, equipada com uma GPU de 24 GB.
Desempenho de execução simultânea
1 instância 2 instâncias Tempo de execução 9,79s Taxa de transferência de 6,72 s 10,6 token/s 15,5 token/s
(*) Para ajustar as instâncias do modelo na GPU disponível, tivemos que fazer a quantização de 8 bits
Desempenho dinâmico de dosagem
Tamanho do lote = 1 Tamanho do lote = 8 Tempo de execução do HFVLLMHFVLLM 9,79s 2,06s 17,07s Taxa de transferência de 3,12 s 10,6 token/s 50 token/s 66,5 token/s 363 token (s)
Observações finais
Ao longo deste tutorial, analisamos várias técnicas para implantar modelos de aprendizado de máquina no ecossistema Triton, o que nos permitiu acelerar o tempo de inferência em até x7 sem perder a precisão. A seguir estão alguns dos principais resultados obtidos durante nossos testes:
- Ao explorar o recurso de execução simultânea de modelos do Triton, obtivemos um aumento de x1,5 na taxa de transferência por meio da implantação de duas instâncias paralelas do modelo Llama2 7B quantizadas em 8 bits.
- Implementar dosagem dinâmica adicionou um adicional aumento de 5x na taxa de transferência do modelo.
- Finalmente, a incorporação da estrutura vLLM superou os resultados do agrupamento dinâmico com um aumento de x7. Como desvantagem, o vLLM não permite a quantização do modelo, portanto, não pudemos testar instâncias simultâneas do Llama2 7B sob essa estrutura devido aos requisitos computacionais.
Para se aprofundar nesses exemplos, dê uma olhada em nosso reposse! 🔗



.png)