.png)
Construyendo una base de datos confiable: calidad de datos para los LLM




Lograr un valor sustancial con modelos lingüísticos grandes (LLM) puede ser un desafío sin una base de datos escalable. Los puntos de datos se recopilan de múltiples fuentes y se definen de diferentes maneras. Esto podría provocar que vayan en direcciones opuestas y carezcan de coherencia. La falta de una documentación adecuada de la entidad y de una estrategia sólida de calidad de los datos se reduce a que los ingenieros cierren manualmente esta brecha y resuelvan las discrepancias.
Al invertir en una base de datos escalable, este paradigma experimenta un cambio fundamental. Los datos están bien documentados, tienen una propiedad clara y están estructurados, y los LLM pueden limitar su alcance de toma de decisiones para centrarse exclusivamente en los elementos, con una gobernanza clara y una gestión del cambio bien implementada.
Introducción
Los modelos lingüísticos grandes (LLM) son sistemas avanzados de inteligencia artificial que se han entrenado con cantidades masivas de datos de texto para comprender y generar un lenguaje similar al humano. Estos modelos, como GPT-4 de OpenAI, constan de millones (o incluso miles de millones) de parámetros, lo que les permite comprender patrones lingüísticos, contextos y semánticas complejos.

Los LLM han adquirido una importancia inmensa en una amplia gama de aplicaciones debido a sus notables capacidades de generación y comprensión del lenguaje. Así es como están teniendo un impacto:
- Comprensión del lenguaje natural: Los LLM pueden comprender y analizar textos con una comprensión similar a la humana. Se destacan en tareas como el análisis de sentimientos, la clasificación de textos y el reconocimiento de entidades nombradas, lo que permite comprender mejor las intenciones y emociones de los usuarios.
- Generación de texto: Estos modelos pueden generar textos coherentes y contextualmente relevantes. Podemos pensar en la creación de contenido, los chatbots, la atención al cliente automatizada y la escritura creativa como ejemplos de esta función.
- Traducción de idiomas: Los LLM facilitan la traducción de idiomas precisa y sensible al contexto, derribando las barreras lingüísticas y permitiendo una comunicación eficaz a escala global.
- Resumen y extracción de contenido: Se destacan por condensar grandes volúmenes de texto en resúmenes concisos, lo que ayuda a recuperar la información y resumir el contenido.
- Generación de código y soporte técnico: Los LLM pueden generar fragmentos de código, solucionar problemas técnicos y ofrecer asistencia de programación, lo que mejora la productividad de los desarrolladores.
No dudes en visitar nuestra publicación sobre LLMs (Una guía de incorporación a los LLM) para obtener más detalles.
Resumen y extracción de contenido
Al profundizar en el caso de uso del resumen, la recuperación implica buscar en los datos disponibles para encontrar el contenido que mejor se adapte a la solicitud del usuario. En los modelos basados en la recuperación, el sistema identifica los contenidos preexistentes (por ejemplo, frases, párrafos o documentos) de una base de datos que coinciden estrechamente con la consulta del usuario y se los presenta.

Imagen tomada de Streamlit entrada de blog sobre creación de una aplicación de resumen de texto con Langchain
Aunque esto suena (y realmente es) increíble, no es tan sencillo. La salida está directamente relacionada con la entrada (entra en escena el famoso Garbage-In-Garbage-Out). Si incorporamos datos de mala calidad o datos seleccionados incorrectamente en nuestros modelos, podemos esperar que el resultado también sea de mala calidad.
Algunos ejemplos de «basura» son los datos faltantes o desequilibrados, lo que afecta al proceso de recuperación y produce resultados erróneos o de mala calidad.
La calidad de los datos está en el centro de todas las aplicaciones de ML (aprendizaje automático) y los LLM no son la excepción. El propósito de esta publicación es explorar la importancia de la calidad de los datos en el proceso de interactuar con un LLM y mejorar su rendimiento. En este sentido, profundizaremos en los riesgos que debemos evitar y las consideraciones que debemos tener en cuenta al enfrentarnos a esta importante tarea.
La evolución de los lagos de datos: sorteando los desafíos
Naturaleza dinámica de los lagos de datos
Un lago de datos es un sistema de almacenamiento potente y versátil que permite a las organizaciones almacenar grandes cantidades de datos estructurados y no estructurados en su forma original.
Los lagos de datos están diseñados para escalar horizontalmente, con capacidad para petabytes de datos o más. Esta escalabilidad garantiza que, a medida que aumenta el volumen de datos, el rendimiento del sistema se mantenga estable, lo que lo hace adecuado para cargas de trabajo de big data (¡como LLM!).

Imagen tomada de ¿Qué es un lago de datos? artículo de AWS
Los lagos de datos siguen un enfoque de «esquema en función de la lectura». Esto significa que los datos se introducen en el lago sin necesidad de definir previamente una estructura rígida, como es el caso de las bases de datos y almacenes de datos tradicionales («esquema al escribir»).
Por ello, los lagos de datos admiten diversos tipos y formatos de datos, lo que los hace increíblemente flexibles.
Sin embargo, esta flexibilidad es un arma de doble filo que podría terminar haciendo más daño que bien. Sin una gobernanza adecuada y una estrategia sólida de calidad de los datos, lo que queríamos que fuera un lago de datos se convierte en el temido «pantano de datos».

Imagen tomada de dataedo muy gracioso sección de dibujos animados
Un pantano de datos suele ser el resultado de la falta de procesos y estándares. Los datos de un pantano de datos son difíciles de encontrar, manipular, analizar y, por supuesto, trabajar con modelos de aprendizaje automático.
Recopilación de puntos de datos de varias fuentes
Como los lagos de datos alojan datos estructurados, semiestructurados y no estructurados, permiten a las organizaciones gestionar una amplia variedad de fuentes de datos. Esto es particularmente importante en el panorama de datos actual, donde la información proviene de múltiples canales y formatos. Sin embargo, existen muchos desafíos relacionados con la recopilación de puntos de datos de múltiples fuentes, solo por mencionar los principales:
- Integración: La integración de estas fuentes dispares requiere procesos complejos de transformación y normalización de datos para garantizar la coherencia y la compatibilidad de los datos.
- Disparidad de calidad: Las diferentes fuentes pueden tener diferentes niveles de calidad de datos. Algunas fuentes pueden contener datos incompletos, inexactos u obsoletos, lo que puede afectar negativamente a la precisión y confiabilidad del análisis.
- Granularidad: Las fuentes de datos pueden proporcionar datos con diferentes niveles de granularidad. La integración y la agregación de datos con diferentes niveles de detalle pueden generar desafíos a la hora de mantener información precisa.
Si no se abordan adecuadamente todos estos desafíos, existe un enorme riesgo de acabar encontrándonos con los conocidos «silos de datos», donde en lugar de tener la deseada «Fuente de la verdad» nos topamos con un mar de inconsistencias e incompatibilidades. Intentar trabajar con un máster en este tipo de entorno resulta ser una tarea mesiánica.
La verdad fragmentada: desentrañando definiciones de datos dispares
Como mencionamos anteriormente, las definiciones de datos inconsistentes conducirían a un bajo rendimiento de LLM, pero ¿qué queremos decir exactamente con «bajo rendimiento»? Veamos algunos ejemplos:
- Alucinaciones: La alucinación se refiere a la tendencia a generar contenido que parece plausible pero que no se basa en información fáctica o precisa. Este fenómeno ocurre cuando los LLM producen texto que parece coherente y relevante, pero que en realidad es fabricado o inventado, lo que puede llevar a la generación de contenido falso o engañoso.
- Duplicidad de información: Cuando no podemos garantizar la unicidad de los datos, pueden ocurrir cosas extrañas. Es posible que los LLM no puedan crear un contexto coherente en un entorno de duplicidad que conduzca a resultados de mala calidad.
- Pérdida de dependencias: En el proceso de analizar documentos grandes para convertirlos en documentos más pequeños, se pierden datos importantes que afectan negativamente a la calidad del resultado.
El papel de la calidad de los datos en el rendimiento de los LLM
Demos un paso atrás e intentemos entender mejor qué significa la calidad de los datos y cómo se mide. La calidad de los datos se define como el estado de los datos en cualquier etapa de su ciclo de vida. Implica garantizar que los datos se ajusten a las necesidades de la empresa. La calidad de los datos puede verse afectada en cualquier etapa de la cadena de datos, antes de la ingestión, durante la producción o incluso durante el análisis.
Hay seis dimensiones clave que las empresas utilizan para medir y comprender la calidad de sus datos. Vamos a analizarlos más de cerca.

Imagen tomada de A continuación se explica cómo empezar con la calidad de los datos artículo
- Integridad: Mide si todos los elementos de datos necesarios están presentes en un conjunto de datos sin lagunas ni valores faltantes.
- Puntualidad: Evalúa si los datos están actualizados y disponibles cuando se necesitan para el análisis, la capacitación o la inferencia.
- Validez: Mide hasta qué punto los datos se ajustan a las reglas, restricciones y estándares predefinidos (es decir, el formato, el tipo o el rango).
- Precisión: Mide qué tan bien los datos reflejan con precisión el objeto que se describe y garantiza que representa con precisión las entidades del mundo real.
- Consistencia: Examina si los datos son coherentes y están en armonía en diferentes fuentes o dentro del mismo conjunto de datos.
- Singularidad: Garantiza que cada registro de datos represente una entidad distinta, lo que evita la duplicación.
Dicho todo esto, está claro que invertir en una estrategia de calidad sólida es una obviedad si queremos ofrecer un valor real con el uso de los LLM. No cabe duda de que podemos inventarnos un caso de uso sofisticado, pero al final, los casos de uso del mundo real que proporcionan un valor real con resultados de alta calidad son los que prosperarán.
Pongámonos un poco más prácticos y exploremos una serie de conceptos y técnicas para que esto funcione.
Creación de una infraestructura de datos basada en la calidad para los LLM
Evaluación de los requisitos de datos
Siempre que se lleve a cabo un proyecto que implique obtener el valor de un LLM, el primer paso es identificar los datos necesarios para respaldar el caso de uso. En esta etapa, es probable que analicemos las famosas 3 V del Big Data (volumen, velocidad y variedad) para describir la forma de los datos involucrados.

Imagen tomada de paquete artículo sobre Las 3 V del Big Data
También podríamos repasar las dimensiones de calidad de los datos que mencionamos anteriormente y definir cómo queremos que se comporten nuestros datos.
Sería crucial garantizar que las entidades estén correctamente identificadas y representadas en los conjuntos de datos. Las entidades serían las que representan y almacenan información sobre elementos o cosas de interés específicos en forma de objetos, conceptos o individuos distintos del mundo real. Sin la definición de entidad adecuada, no habría ningún contexto en el que trabajar en el LLM.
Cómo elegir el almacenamiento de datos adecuado
Como mencionamos anteriormente, los lagos de datos son una excelente opción para cuando necesitamos almacenar grandes cantidades de datos. Aunque hay algunas advertencias a tener en cuenta (también mencionadas), siguen siendo una de las bases en las que se basa todo proyecto de datos.
Sin embargo, estos sistemas rara vez funcionan por sí solos. En cambio, la necesidad de incluir otras herramientas surge cuando el caso de uso se vuelve más complejo.
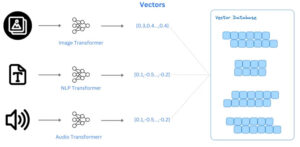
Imagen tomada de decube.io entrada de blog sobre bases de datos vectoriales
Por ejemplo, las bases de datos vectoriales son cada vez más populares en el contexto de los LLM debido a su capacidad para almacenar y administrar vectores de alta dimensión (¡como los generados por los LLM!). Estas bases de datos están optimizadas para almacenar, recuperar y buscar por similitud de datos vectoriales de manera eficiente. Son cruciales para las aplicaciones que incluyen la comparación de similitudes, los sistemas de recomendación y la recuperación de contenido, donde las relaciones entre los puntos de datos se basan en sus representaciones vectoriales en un espacio de alta dimensión.
Implementación de la documentación de datos
Las prácticas eficaces de documentación de datos son esenciales para mantener el linaje de datos y preservar el contexto de los datos durante todo su ciclo de vida. La documentación adecuada garantiza que los datos sigan siendo comprensibles, rastreables y confiables a lo largo del tiempo. La implementación de una documentación de datos integral incluye:
- Metadatos del documento: Cree un repositorio de metadatos que incluya información sobre cada conjunto de datos, como su origen, propósito, fecha de creación, frecuencia de actualización, propietario y reglas empresariales relevantes.
- Linaje de datos de captura: Documente el recorrido de los datos desde su origen hasta sus diversas transformaciones y usos. Incluya detalles sobre los procesos de extracción, transformación y carga (ETL) y cualquier paso intermedio.
- Incluya información sobre el esquema: Detalle la estructura de los conjuntos de datos, incluidos los nombres de las columnas, los tipos de datos, las restricciones y las relaciones. Esto proporciona una comprensión clara del diseño de los datos.
- Proporcione información contextual: Ofrezca explicaciones de los términos clave, acrónimos y conceptos específicos del dominio presentes en los datos. Esta información contextual ayuda a los usuarios a interpretar los datos con precisión.
- Control de versiones: Implemente el control de versiones para la documentación. A medida que los datos evolucionan, actualice la documentación para reflejar los cambios y garantizar que se conserve el contexto histórico.
Técnicas de aseguramiento de la calidad
¿Recuerdas que hablamos de Garbage-In Garbage-out al principio del post? Bueno, los ingenieros de datos adoptaron una técnica muy conocida para evitarlo. Su nombre es el patrón de escritura-audición-publicación (WAP).
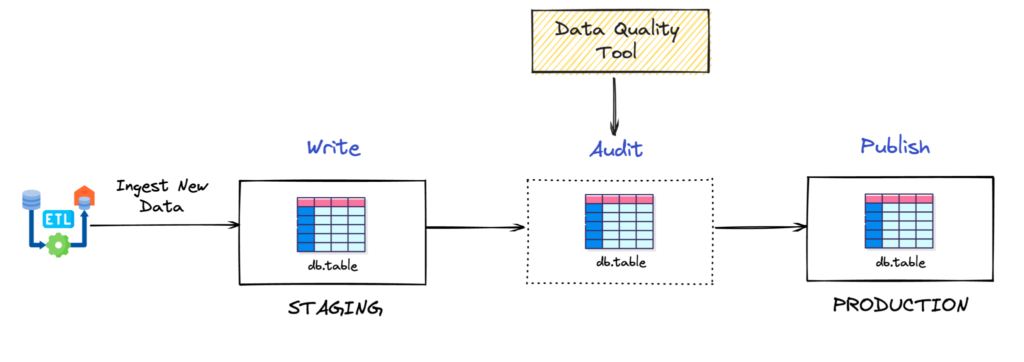
Imagen tomada de Optimización de la calidad de los datos en Apache Iceberg con escritura, auditoría, publicación y ramificación artículo de dremio
La técnica WAP se compone de 3 elementos: una sección de preparación, un proceso de validación de la calidad de los datos y una sección de producción. Tenga en cuenta que escribí «sección» en lugar de «tabla» tanto para la puesta en escena como para la producción. La razón de esto es que la técnica WAP podría extenderse más allá de los datos tabulares estructurados o semiestructurados. Cualquier dato (incluso texto, audio o imágenes) que sea adecuado para comprobar su calidad de cualquier forma, también es adecuado para el patrón WAP. Vamos a profundizar en cada una de las secciones.
- Puesta en escena: Puede ser una tabla en un almacén de datos o un archivo de texto en un lago de datos. Los datos vienen sin procesar o con poca transformación directamente desde la fuente.
- Proceso de validación de la calidad de los datos: Implica realizar todas las validaciones de calidad de datos necesarias para garantizar que los datos estén listos para la producción. ¿Recuerdas cuando hablamos de las seis dimensiones de la calidad de los datos? Bueno, ahora es el momento de hacer todo lo posible y convertirlas en pruebas reales y tangibles. Hay algunas herramientas interesantes que ayudan a construir la plataforma de pruebas, como Great Expectations, Soda y dbt tests.
- Producción: Si se aprueba el proceso de validación, los datos se trasladan a las secciones de producción, donde están listos para ser consumidos para su posterior transformación, análisis, entrenamiento de modelos de aprendizaje automático, inferencia o recuperación.
Conclusión
Hoy nos hemos dado cuenta de la importancia de la calidad de los datos en el contexto de los LLM. Hemos analizado temas como los sistemas de almacenamiento, cómo se mide la calidad de los datos, las implicaciones que podría tener una mala estrategia de calidad de los datos y también un patrón sencillo (WAP) sobre cómo implementarlo en la actualidad.
No importa lo repetitivo que suene, si alimentamos basura, produciremos basura.
Dicho todo esto, no tiene más remedio que tratar su estrategia de calidad de datos como un ciudadano de primera clase. Al invertir en una base de datos escalable, en la que los datos estén bien documentados, de propiedad clara y estructurados, ¡estará preparado para aprovechar los LLM para llevar a su organización al siguiente nivel!



.png)