.png)
Construindo uma base de dados confiável: qualidade de dados para LLMs




Obter um valor substancial com grandes modelos de linguagem (LLMs) pode ser um desafio sem uma base de dados escalável. Os pontos de dados são coletados de várias fontes e definidos de várias maneiras diferentes. Isso pode fazer com que estejam em direções opostas e não tenham consistência. A falta de documentação adequada da entidade e de uma estratégia sólida de qualidade de dados se resumem ao fato de os engenheiros preencherem manualmente essa lacuna e resolverem as discrepâncias.
Ao investir em uma base de dados escalável, esse paradigma passa por uma mudança fundamental. Os dados são bem documentados, claramente possuídos e estruturados, e os LLMs podem limitar seu escopo de tomada de decisão para se concentrar exclusivamente nos elementos com governança clara e gerenciamento de mudanças bem implementado.
Introdução
Grandes modelos de linguagem (LLMs) são sistemas avançados de inteligência artificial que foram treinados em grandes quantidades de dados de texto para entender e gerar uma linguagem semelhante à humana. Esses modelos, como GPT-4 da OpenAI, consistem em milhões (ou até bilhões) de parâmetros, permitindo que eles compreendam padrões linguísticos, contextos e semânticas complexos.

Os LLMs ganharam imensa importância em uma ampla variedade de aplicações devido à sua notável compreensão de idiomas e capacidades de geração. Veja como eles estão causando impacto:
- Compreensão da linguagem natural: Os LLMs podem compreender e analisar texto com uma compreensão semelhante à humana. Eles se destacam em tarefas como análise de sentimentos, classificação de texto e reconhecimento de entidades nomeadas, permitindo uma melhor compreensão das intenções e emoções do usuário.
- Geração de texto: Esses modelos podem gerar texto coerente e contextualmente relevante. Podemos pensar na criação de conteúdo, chatbots, suporte automatizado ao cliente e redação criativa como exemplos desse recurso.
- Tradução de idiomas: Os LLMs facilitam a tradução de idiomas precisa e sensível ao contexto, quebrando barreiras linguísticas e permitindo uma comunicação eficaz em escala global.
- Sumarização e extração de conteúdo: Eles se destacam na condensação de grandes volumes de texto em resumos concisos, auxiliando na recuperação de informações e no resumo do conteúdo.
- Geração de código e suporte técnico: Os LLMs podem gerar trechos de código, solucionar problemas técnicos e oferecer assistência de programação, aumentando a produtividade do desenvolvedor.
Visite nossa postagem sobre LLMs (Um guia de integração para LLMs) para obter detalhes mais detalhados.
Sumarização e extração de conteúdo
Aprofundando o caso de uso do resumo, a recuperação envolve pesquisar os dados disponíveis para encontrar o conteúdo que melhor corresponda à solicitação do usuário. Em modelos baseados em recuperação, o sistema identifica partes preexistentes de conteúdo (por exemplo, frases, parágrafos, documentos) de um banco de dados que se assemelha à consulta do usuário e as apresenta a ele.

Imagem tirada de Simplificado postagem no blog sobre criando um aplicativo de resumo de texto com Langchain
Mesmo que isso pareça (e realmente seja) incrível, não é tão simples assim. A saída está diretamente relacionada à entrada (o famoso Garbage-In-Garbage-Out entra em cena). Se inserirmos dados de baixa qualidade ou dados selecionados incorretamente em nossos modelos, podemos esperar que o resultado também seja de baixa qualidade.
Alguns exemplos de “entrada de lixo” são dados ausentes ou desbalanceados, o que afeta o processo de recuperação, produzindo resultados errôneos ou de baixa qualidade.
A qualidade dos dados está no centro de todos os aplicativos de ML (aprendizado de máquina), e os LLMs não são exceção. O objetivo desta postagem é explorar a importância da qualidade dos dados no processo de interação com um LLM e melhorar seu desempenho. Nesse sentido, mergulharemos nos riscos que devemos evitar e quais considerações devemos tomar ao enfrentar essa tarefa significativa.
Os lagos de dados em evolução: enfrentando os desafios
Natureza dinâmica dos data lakes
Um data lake é um sistema de armazenamento poderoso e versátil que permite às organizações armazenar grandes quantidades de dados estruturados e não estruturados em sua forma bruta.
Os data lakes são criados para escalar horizontalmente, acomodando petabytes de dados ou mais. Essa escalabilidade garante que, à medida que o volume de dados aumenta, o desempenho do sistema permaneça estável, tornando-o adequado para cargas de trabalho de big data (como LLMs!).

Imagem tirada de O que é um data lake? artigo de AWS
Os data lakes seguem uma abordagem de “esquema na leitura”. Isso significa que os dados são ingeridos no lago sem a necessidade de definir previamente uma estrutura rígida, como é o caso dos bancos de dados e data warehouses tradicionais (“schema-on-write”).
Por isso, os Data Lakes acomodam diversos tipos e formatos de dados, tornando-os incrivelmente flexíveis.
No entanto, essa flexibilidade vem como uma faca de dois gumes que pode acabar fazendo mais mal do que bem. Sem a governança adequada e uma forte estratégia de qualidade de dados, o que queríamos ser um Data Lake se torna o temido “pântano de dados”.

Imagem tirada de data edo muito engraçado seção de desenhos animados
Um pântano de dados geralmente é o resultado da falta de processos e padrões. Os dados em um pântano de dados são difíceis de encontrar, manipular, analisar e, é claro, trabalhar com modelos de ML.
Coletando pontos de dados de várias fontes
Como os Data Lakes acomodam dados estruturados, semiestruturados e não estruturados, eles permitem que as organizações lidem com uma grande variedade de fontes de dados. Isso é particularmente importante no cenário atual de dados, onde as informações vêm de vários canais e formatos. No entanto, existem muitos desafios relacionados à coleta de pontos de dados de várias fontes, apenas para mencionar os principais:
- Integração: A integração dessas fontes diferentes exige processos complexos de transformação e normalização de dados para garantir a consistência e a compatibilidade dos dados.
- Disparidade de qualidade: Fontes diferentes podem ter níveis variados de qualidade de dados. Algumas fontes podem conter dados incompletos, imprecisos ou desatualizados, o que pode afetar negativamente a precisão e a confiabilidade da análise.
- Granularidade: As fontes de dados podem fornecer dados em diferentes níveis de granularidade. Integrar e agregar dados com diferentes níveis de detalhes pode gerar desafios na manutenção de insights precisos.
Se todos esses desafios não forem enfrentados adequadamente, há um grande risco de acabar encontrando os conhecidos “Silos de Dados”, onde, em vez de ter a “Fonte da Verdade” desejada, nos deparamos com um mar de inconsistências e incompatibilidades. Tentar trabalhar com um LLM nesse tipo de ambiente acaba sendo uma tarefa messiânica.
A verdade fragmentada: desvendando definições de dados díspares
Como mencionamos anteriormente, definições de dados inconsistentes levariam a um desempenho ruim do LLM, mas o que exatamente queremos dizer com “desempenho ruim”? Vamos ver alguns exemplos:
- Alucinações: Alucinação se refere à tendência de gerar conteúdo que parece plausível, mas não é baseado em informações factuais ou precisas. Esse fenômeno ocorre quando os LLMs produzem texto que parece coerente e relevante, mas na verdade é fabricado ou inventado, potencialmente levando à geração de conteúdo falso ou enganoso.
- Duplicidade de informações: Quando não podemos garantir a exclusividade dos dados, coisas estranhas podem acontecer. Os LLMs podem não conseguir criar um contexto consistente em um ambiente de duplicidade, levando a resultados de baixa qualidade.
- Lista de dependências: No processo de análise de documentos grandes em documentos menores, informações importantes são perdidas, afetando negativamente a qualidade da saída.
O papel da qualidade dos dados no desempenho do LLM
Vamos dar um passo atrás e tentar entender melhor o que significa qualidade de dados e como ela é medida. A qualidade dos dados é definida como a integridade dos dados em qualquer estágio de seu ciclo de vida. Isso envolve garantir que os dados atendam às necessidades da empresa. A qualidade dos dados pode ser afetada em qualquer estágio do pipeline de dados, antes da ingestão, na produção ou até mesmo durante a análise.
Há seis dimensões principais que as empresas usam para medir e entender a qualidade de seus dados. Vamos examiná-los mais de perto.

Imagem tirada de Veja como começar com a qualidade dos dados artigo
- Completude: Ele mede se todos os elementos de dados necessários estão presentes em um conjunto de dados sem lacunas ou valores ausentes.
- Pontualidade: Ele avalia se os dados estão atualizados e disponíveis quando necessário para análise, treinamento ou inferência.
- Validade: Ele mede o quão bem os dados estão em conformidade com regras, restrições e padrões predefinidos (ou seja, formato, tipo ou intervalo).
- Precisão: Ele mede o quão bem os dados refletem com precisão o objeto que está sendo descrito, garantindo que ele represente com precisão as entidades do mundo real.
- Consistência: Ele examina se os dados são coerentes e estão em harmonia em diferentes fontes ou dentro do mesmo conjunto de dados.
- Exclusividade: Ele garante que cada registro de dados represente uma entidade distinta, evitando a duplicação.
Com tudo isso dito, fica claro que investir em uma estratégia de qualidade forte é óbvio se quisermos fornecer valor real com o uso de LLMs. Com certeza, podemos criar um caso de uso sofisticado, mas, no final, os casos de uso do mundo real que fornecem valor real com resultados de alta qualidade são os que prosperarão.
Vamos colocar um pouco mais a mão na massa e explorar uma série de conceitos e técnicas para fazer isso funcionar.
Construindo uma infraestrutura de dados orientada pela qualidade para LLMs
Avaliação dos requisitos de dados
Sempre que passar por um projeto que envolva a obtenção do valor de um LLM, a primeira etapa é identificar os dados necessários para apoiar o caso de uso. Neste estágio, provavelmente examinaremos os famosos 3 V's do Big Data — volume, velocidade e variedade — para descrever a forma dos dados envolvidos.

Imagem tirada de pacote artigo sobre 3 V's de Big Data
Também podemos examinar as dimensões de qualidade de dados que mencionamos anteriormente e definir como queremos que nossos dados se comportem.
Garantir que as entidades sejam identificadas e representadas corretamente nos conjuntos de dados seria crucial. As entidades seriam aquelas que representam e armazenam informações sobre itens específicos ou coisas de interesse na forma de objetos, conceitos ou indivíduos distintos do mundo real. Sem a definição adequada da entidade, não haveria contexto no qual o LLM pudesse trabalhar.
Escolhendo o armazenamento de dados certo
Como mencionamos anteriormente, os Data Lakes são uma ótima opção para quando precisamos armazenar grandes quantidades de dados. Embora haja algumas ressalvas a serem consideradas (também mencionadas), elas continuam sendo uma das bases sobre as quais todo projeto de dados se baseia.
No entanto, esses sistemas raramente funcionam sozinhos. Em vez disso, a necessidade de incluir outras ferramentas surge quando o caso de uso se torna mais complexo.
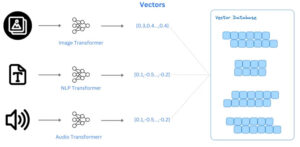
Imagem tirada de decube.io postagem no blog sobre bancos de dados vetoriais
Por exemplo, bancos de dados vetoriais estão se tornando cada vez mais populares no contexto de LLMs devido à sua capacidade de armazenar e gerenciar vetores de alta dimensão (como aqueles gerados por LLMs!). Esses bancos de dados são otimizados para armazenamento, recuperação e pesquisa por similaridade eficientes de dados vetoriais. Eles são cruciais para aplicações que envolvem comparação de similaridades, sistemas de recomendação e recuperação de conteúdo, em que as relações entre os pontos de dados são baseadas em suas representações vetoriais em um espaço de alta dimensão.
Implementando documentação de dados
Práticas eficazes de documentação de dados são essenciais para manter a linhagem de dados e preservar o contexto dos dados durante todo o ciclo de vida. A documentação adequada garante que os dados permaneçam compreensíveis, rastreáveis e confiáveis ao longo do tempo. A implementação de uma documentação de dados abrangente inclui:
- Metadados do documento: Crie um repositório de metadados que inclua informações sobre cada conjunto de dados, como origem, finalidade, data de criação, frequência de atualização, proprietário e regras comerciais relevantes.
- Linhagem de dados de captura: Documente a jornada dos dados desde sua origem até suas várias transformações e usos. Inclua detalhes sobre processos de extração, transformação, carregamento (ETL) e quaisquer etapas intermediárias.
- Incluir informações do esquema: Detalhe a estrutura dos conjuntos de dados, incluindo nomes de colunas, tipos de dados, restrições e relacionamentos. Isso fornece uma compreensão clara do layout dos dados.
- Forneça informações contextuais: Ofereça explicações sobre os principais termos, acrônimos e conceitos específicos de domínio presentes nos dados. Essas informações contextuais ajudam os usuários a interpretar os dados com precisão.
- Controle de versão: Implemente o controle de versão para documentação. À medida que os dados evoluem, atualize a documentação para refletir as mudanças e garantir que o contexto histórico seja preservado.
Técnicas de garantia de qualidade
Lembra que falamos sobre Garbage-In Garbage-out no começo do post? Bem, os engenheiros de dados adotaram uma técnica bem conhecida para evitá-la. Seu nome é padrão write-audit-publish (WAP).
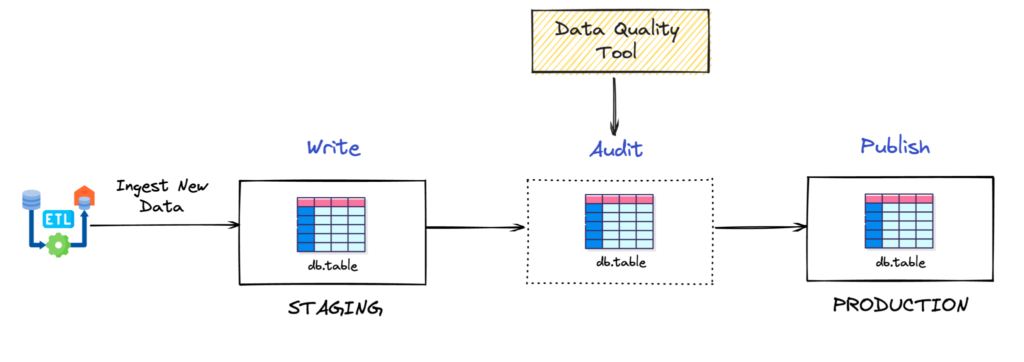
Imagem tirada de Simplificando a qualidade dos dados no Apache Iceberg com gravação, auditoria, publicação e ramificação artigo de dremio
A técnica WAP é formada por 3 elementos: uma seção de preparação, um processo de validação da qualidade de dados e uma seção de produção. Observe que eu escrevi “seção” em vez de “tabela” para preparação e produção. A razão para isso é que a técnica WAP pode ser estendida além dos dados tabulares estruturados/semiestruturados. Cada dado (até mesmo texto, áudio ou imagens) que é adequado para ser testado em relação à qualidade de qualquer forma, também é adequado para o padrão WAP. Vamos nos aprofundar em cada uma das seções.
- Encenação: Pode ser uma tabela em um data warehouse ou um arquivo de texto em um data lake. Os dados vêm brutos ou com pouca transformação diretamente da fonte.
- Processo de validação da qualidade de dados: Envolve a realização de todas as validações de qualidade de dados necessárias para garantir que os dados estejam prontos para produção. Lembra quando falamos sobre as seis dimensões da qualidade de dados? Bem, agora é hora de apostar tudo e transformá-los em testes reais e tangíveis. Existem algumas ferramentas interessantes que ajudam a criar a plataforma de teste, como os testes Great Expectations, Soda e dbt.
- Produção: Se o processo de validação for aprovado, os dados serão transferidos para as seções de produção, onde estarão prontos para serem consumidos para posterior transformação, análise, treinamento de modelos de ML, inferência ou recuperação.
Conclusão
Hoje, pudemos perceber a importância da qualidade de dados no contexto dos LLMs. Abordamos tópicos como sistemas de armazenamento, como a qualidade dos dados é medida, quais implicações podem ter uma estratégia de qualidade de dados ruim e também um padrão direto (WAP) sobre como implementá-la hoje.
Não importa o quão repetitivo pareça, se alimentarmos o lixo, produziremos lixo.
Com tudo isso dito, você não tem escolha a não ser tratar sua estratégia de qualidade de dados como um cidadão de primeira classe. Ao investir em uma base de dados escalável, onde os dados são bem documentados, de propriedade clara e estruturados, você estará pronto para aproveitar os LLMs para levar sua organização ao próximo nível!



.png)