.png)
AWS Sagemaker Neo con Keras




Valide rápidamente si SageMaker Neo reducirá la latencia y los costos. Si tiene su nuevo y brillante modelo y quiere reducir la latencia y los costos, pongámoslo en marcha.
En este post haremos lo siguiente:
- Guardar un entrenó Modelo Keras
- Compilar funciona con SageMaker Neo
- Despliegue es para EC2

1. Modelo de compilación
Donde le das tu modelo a Neo.
Usaremos un InceptionV3 previamente entrenado para este tutorial, pero puedes usar cualquier modelo que quieras o incluso tu propio modelo personalizado.
[perfectpullquote align="full» bordertop="false» cite= "» link= "» color= "» class= "» size=" "]
Tenga en cuenta que Neo es compatible con todos los marcos de DL populares. Mostraremos el proceso para Keras, pero se puede aplicar a Tensorflow y PyTorch con cambios menores. Estas diferencias se enumeran en https://docs.aws.amazon.com/sagemaker/latest/dg/neo-troubleshooting.html
[/cita perfecta]
desde keras.applications.inception_v3 importar InceptionV3 desde keras.layers importar Inputmodel = InceptionV3 (weights='imagenet', Input_tensor=input (shape =( 224, 224, 3))) model.save ('InceptionV3.h5')
Salida:
model.summary () ____________________________________________________________ Capa (tipo) Parámetro de forma de salida # Conectado a ==================================================================== input_1 (InputLayer) (Ninguno, 224, 224, 3) ____________________________________________________________________________________________ conv2d_1 (None, 224, 30) Conv2D) (Ninguno, 111, 111, 32) 864 input_1 [0] ____________________________________________________...
Aquí solo debes concentrarte en la última línea, lo único que importa de ahora en adelante es que guarde su modelo como .h5 expediente.
Neo espera un comprimido .tar.gz archivo con el .h5 adentro, así que:
tar -czvf InceptionV3.tar.gz Inceptionv3.h5
Estamos casi listos para compilar nuestro modelo, solo necesitamos subirlo a un bucket de S3 y sigue su camino.
[perfectpullquote align="full» bordertop="false» cite= "» link= "» color= "» class= "» size=" "]
Si no está familiarizado con AWS S3, no se preocupe, es como Google Drive pero para desarrolladores. Hay muchos recursos sobre cómo usarlo y solo es necesario en este paso.
[/cita perfecta]
[caption id="attachment_289" align="alignnone» width="966"]
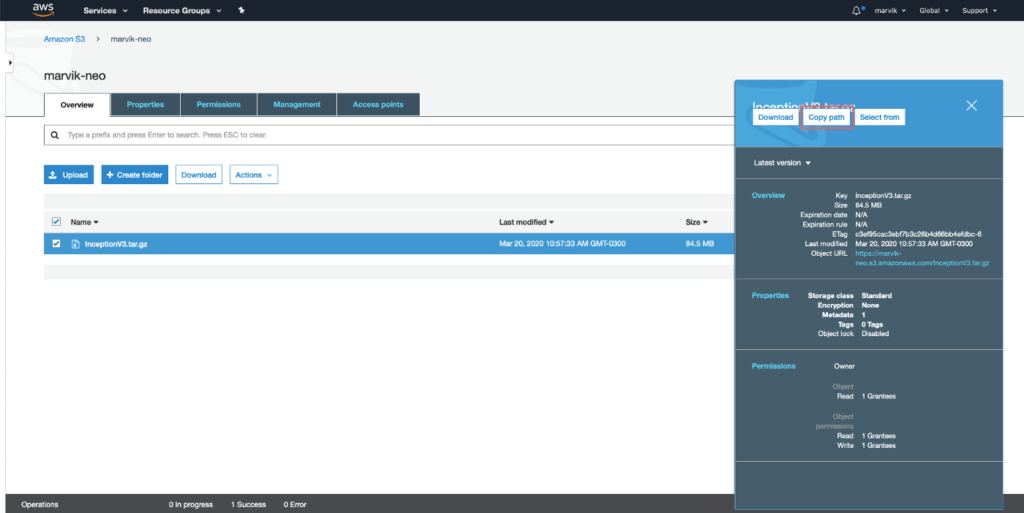
Obtener la ruta S3 [/caption]
Compilando realmente el modelo
Esta parte se puede realizar de tres maneras:
- Consola AWS
- SDK DE AWS
- CLI de AWS
Vamos a tomar la primera ruta, ya que las demás requieren cierta preparación. Ve a la Consola AWS, luego a Creador de salvia y por último Trabajos de compilación en la barra izquierda.
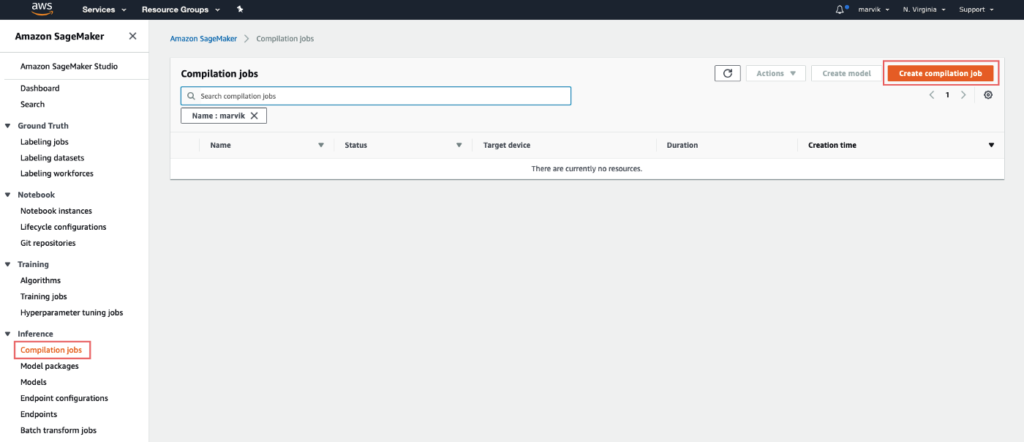
Configuración del trabajo:
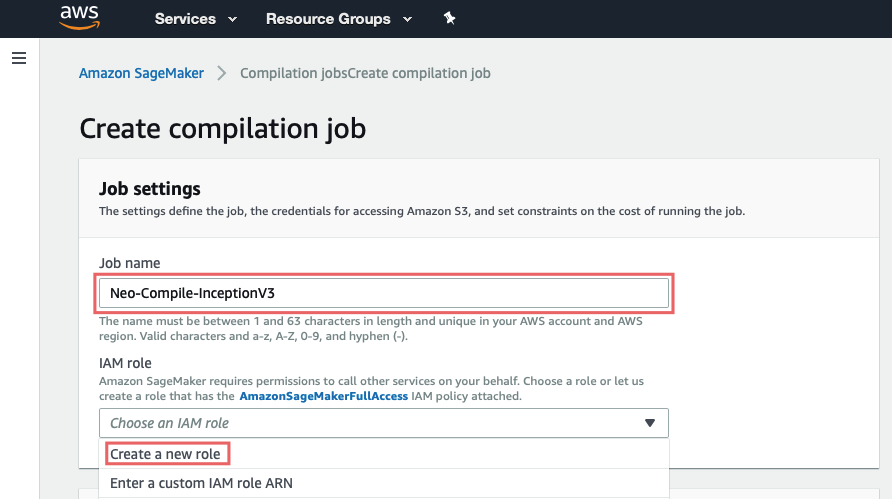
Aquí deberías simplemente dar un nombre y crear un rol para el trabajo (esto configura los permisos para S3)
Para mayor facilidad, elija Cualquier cubo S3, y crear un rol.
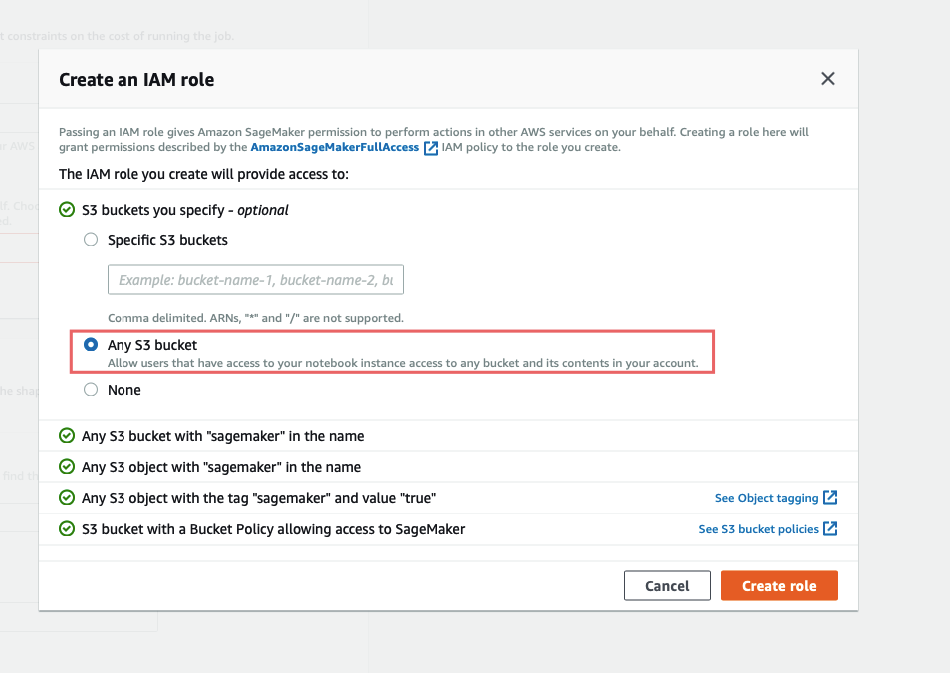
Configuración de entrada:
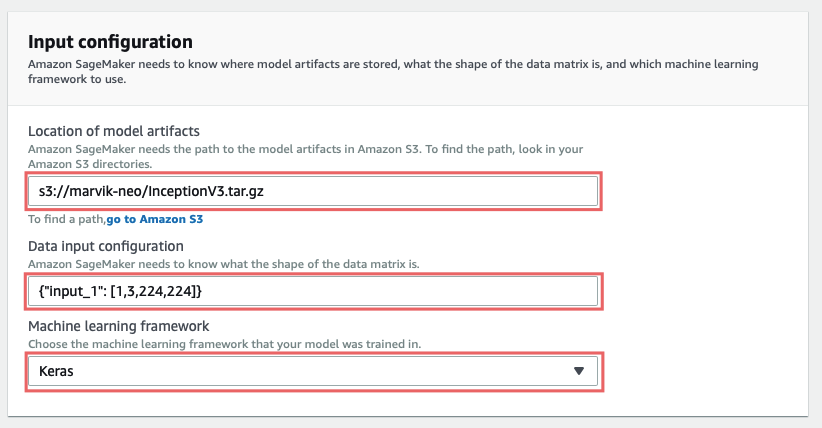
En Ubicación de los artefactos modelo debes introducir la ruta al modelo que has subido, debería empezar con s3://.
Configuración de entrada de datos espera {» <input_layer_name>«: [1,<number_image_channels>,<image_height>,<image_width>]} . Puede obtener estos datos haciendo modelo.summary () y buscando la información de la primera capa:
____________________________________________________________ Capa (tipo) Parámetro de forma de salida # Conectado a ========================================================== input_1 (InputLayer) (Ninguno, 224, 224, 3) 0 ____________________________________________________________________ conv2d_1 (Conv2D) (Ninguno), 111, 111, 32) 864 input_1 [0] ____________________________________________________________________...
La capa de entrada de nuestro modelo es entrada_1 y mirando (Ninguno, 224, 224, 3) podemos obtener el resto de los números que necesitamos.
Así que en nuestro caso sería {"entrada_1": [1, 3, 224, 224]}, si te fijas bien te darás cuenta de que el los números están en un orden diferente, esto es es muy importante y no funcionará de otro modo.
[perfectpullquote align="full» bordertop="false» cite= "» link= "» color= "» class= "» size=" "]
Si tiene curiosidad por saber por qué es eso: Neo espera que los artefactos del modelo Keras lleguen NHWC (Nnúmero de muestras, Hocho, WAnchura, número de Ccanales) pero, curiosamente, la configuración de entrada de datos debe especificarse en NCHW (NNúmero de muestras, Número de Ccanales, Hocho, WAnchura). Para obtener más información sobre esto, incluidos los formatos para PyTorch, Tensorflow o si tu modelo tiene varias entradas, consulta ¿Qué formas de datos de entrada espera Neo?
[/cita perfecta]
Configuración de salida:

Por fin, en Ubicación de salida S3 debe escribir la ruta a la carpeta S3 en la que desea guardar los artefactos de salida.
En Dispositivo objetivo debe especificar en qué plataforma va a implementar este modelo, esto es crucial para que la optimización funcione correctamente. En esta guía vamos a realizar el despliegue en Nube, si está interesado en realizar la implementación en Dispositivos Edge estad atentos a la segunda parte.
[perfectpullquote align="full» bordertop="false» cite= "» link= "» color= "» class= "» size=" "]
¿Por qué es crucial? A nivel superficial, necesita saber si se ejecutará en una GPU o CPU para optimizar el gráfico de cálculo, si se ejecutará en una GPU puede combinar varias capas, como conv2d+bn+relu para evitar guardar resultados intermedios innecesarios en la memoria, lo que permite reducir la latencia y el uso de la memoria. Además, en un nivel inferior, generará código específico para la plataforma, como CUDA o LLVM IR.[/cita perfecta]
Todo lo que queda es golpear Creary espere a que finalice la compilación.
2. Implemente el modelo

Hasta este punto teníamos:
- Guardó nuestro modelo Keras
- Compiló el modelo
Echemos un vistazo a las salidas de cada paso; en el paso 1 obtenemos un archivo que contiene todos los datos del modelo, que se puede usar como inferencia cargándolo con Keras modelo.load () . Sin embargo, en el paso 2, los artefactos que Neo devuelve ya no se pueden utilizar con Keras, solo se pueden ejecutar con un tiempo de ejecución neo específico.
Esto significa que solo tienes que instalar el tiempo de ejecución de Neo en el dispositivo de destino, sin necesidad de keras o tf, que por cierto ahorra un montón de espacio y gastos generales de instalación.
[perfectpullquote align="full» bordertop="false» cite= "» link= "» color= "» class= "» size=" "]
Esto puede parecer extraño al principio, pero es necesario para lograr una latencia más baja. ¿Por qué? Bueno, cuando guardas un modelo de Keras, en realidad estás guardando un gráfico, este gráfico especifica qué operaciones deben realizarse y en qué orden. Un ejemplo sería introducir la entrada a través de una capa densa, obtener la salida y pasarla como entrada a una capa Softmax.
Luego, cuando llega el momento de hacer una inferencia, Keras lee el gráfico y ejecuta las operaciones especificadas para obtener una salida.
Después de que Neo compile el modelo, el gráfico ahora tiene operaciones que no están definidas en Keras, como en el ejemplo anterior conv2d+bn+relu , esto significa que Keras no sabría qué código ejecutar, esta es una de las razones por las que se necesita un tiempo de ejecución específico.
De hecho, en los artefactos del modelo compilado hay un archivo que tiene un código optimizado para cada operación del gráfico, que luego es utilizado por el tiempo de ejecución.
[/cita perfecta]
Así que, dado que elegimos como Dispositivo objetivo un ml_m5 vamos a lanzar un ubuntu EC2 m5. Grande situación e instale las dependencias necesarias.
sudo apt-get update pip3 install dlr numpy
Luego tenemos que subir los archivos compilados a la instancia.
Descargar InceptionV3-ml_m5.tar.gz (desde Ubicación de salida S3) y extráigalo. Para subirlo puedes usar scp en tu máquina de esta manera:
<ec2 ip>scp -i "<path to pem file>" compiled.tar ubuntu@: ~/compiled_model_neo.tar
Luego, en la instancia, hacemos un poco de limpieza:
Tenga en cuenta que los artefactos deben estar todos dentro de una carpeta, en este caso comienzo.
tar xvf compiled_model_neo.tar mkdir inception mv compilado.params inicio/compilado.params mv compiled_model.json inicio/compiled_model.json mv compilado.so inicio/compiled.so
Ahora todo lo que queda por hacer ejecutar el modelo es crear .py un archivo puede ejecutarlo.
vim dlr-neo.py
import numpy as np desde dlr import DLRModel # Cargue el modelo compilado model = dlrModel ('inception', 'cpu') print («Input», model.get_input_names ()) # Cargue una imagen almacenada como una matriz numérica image = np.load ('inception/image.npy') .astype (np.float32) input_data = {'input_1': image} # Predecir salida = model.run (input_data) top1 = np.argmax (out [0]) prob = np.max (out) print («Clase: %s, probabilidad: %f»% (top1, prob))
Reflexiones finales
Hoy nosotros compilado y desplegar de un modelo de keras a un instancia EC2, sin embargo, es posible que desee realizar la implementación en un dispositivo de borde, como una NVIDIA Jetson o una Raspberry Pi, esto no es solo posible, pero también realmente beneficios desde la optimización ya que sin ella puede que ni siquiera funcione.



.png)