.png)
AWS Sagemaker Neo com Keras




Valide rapidamente se o SageMaker Neo reduzirá a latência e os custos. Você tem seu novo modelo brilhante e quer reduzir a latência e os custos, vamos começar a trabalhar.
Neste post, vamos:
- Salvar uma treinado modelo Keras
- Compilar com o SageMaker Neo
- Implantar para EC2

1. Modelo de compilação
Onde você alimenta seu modelo para Neo.
Usaremos um InceptionV3 pré-treinado para este tutorial, mas você pode usar qualquer modelo que quiser ou até mesmo seu próprio modelo personalizado.
[perfectpullquote align="full” bordertop="false” cite= "” link= "” color= "” class= "” size=" "]
Observe que o Neo suporta todas as estruturas DL populares, mostraremos o processo para Keras, mas ele pode ser aplicado ao Tensorflow, PyTorch com pequenas alterações. Essas diferenças estão listadas em https://docs.aws.amazon.com/sagemaker/latest/dg/neo-troubleshooting.html
[/perfect pullquote]
de keras.applications.inception_v3 importe inceptionV3 de keras.layers import Inputmodel = inceptionV3 (weights='imagenet', input_tensor=input (shape= (224, 224, 3))) model.save ('inceptionV3.h5')
Saída:
model.summary () ____________________________________________________________________ Número do parâmetro de forma de saída da camada (tipo) Conectado a ========================================================================== input_1 (InputLayer) (Nenhum, 224, 224, 3) 0 ____________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________ conv2d_1 (Conv2D) (Nenhum, 111, 111, 32) 864 input_1 [0] [0] ____________________________________________________________________________...
Aqui você deve se concentrar apenas na última linha, a única coisa que importa de agora em diante é que você tenha seu modelo salvo como um .h5 arquivo.
Neo espera uma compressão .tar.gz arquivo com o .h5 por dentro, então:
tar -czvf InceptionV3.tar.gz Iniciação V3.h5
Estamos quase prontos para compilar nosso modelo, só precisamos faça o upload para um bucket do S3 e siga seu caminho.
[perfectpullquote align="full” bordertop="false” cite= "” link= "” color= "” class= "” size=" "]
Se você não está familiarizado com o AWS S3, não se preocupe, é como o Google Drive, mas para desenvolvedores. Há muitos recursos sobre como usá-lo, e eles só são necessários nesta etapa.
[/perfect pullquote]
[caption id="attachment_289" align="alignnone” width="966"]
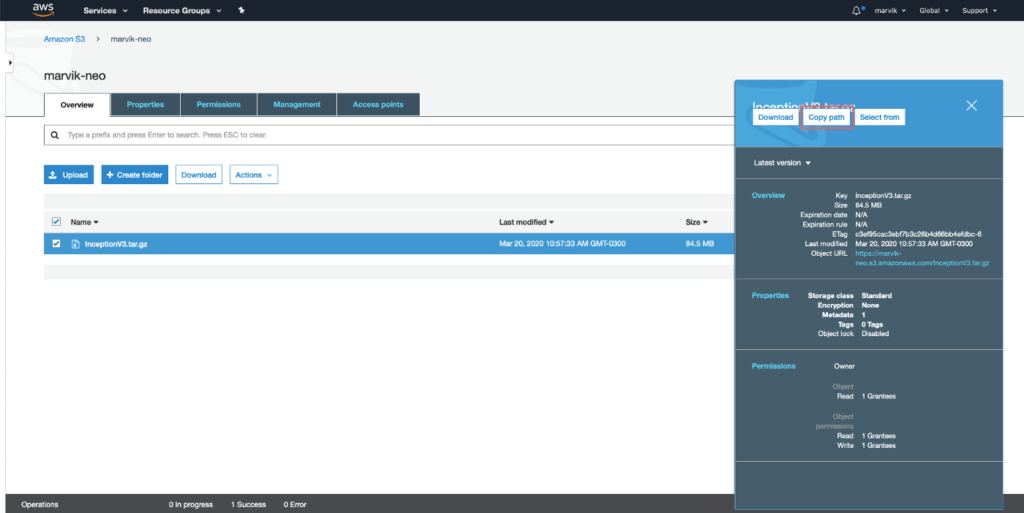
Obtendo o caminho do S3 [/caption]
Na verdade, compilando o modelo
Essa parte pode ser feita de três maneiras:
- Console da AWS
- SDK DA AWS
- AWS cli
Estamos seguindo a primeira rota, pois as outras exigem alguma configuração. Vá para o Console da AWS, depois para SageMaker e por último até Trabalhos de compilação na barra esquerda.
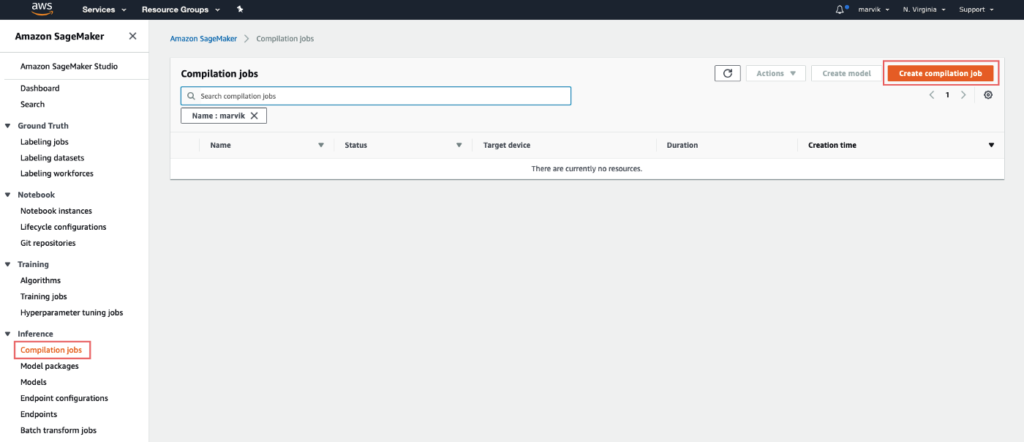
Configurações do trabalho:
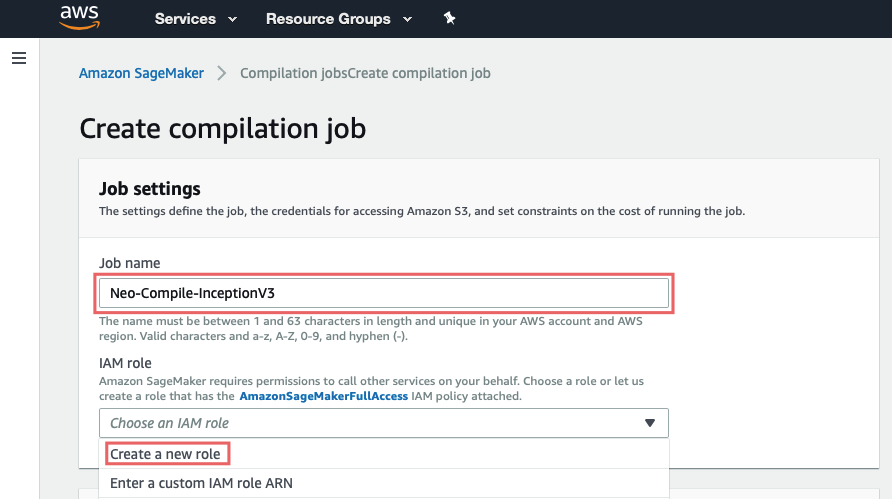
Aqui você deve simplesmente dê um nome e criar uma função para o trabalho (isso configura as permissões para o S3)
Para facilitar, escolha Qualquer balde S3e crie uma função.
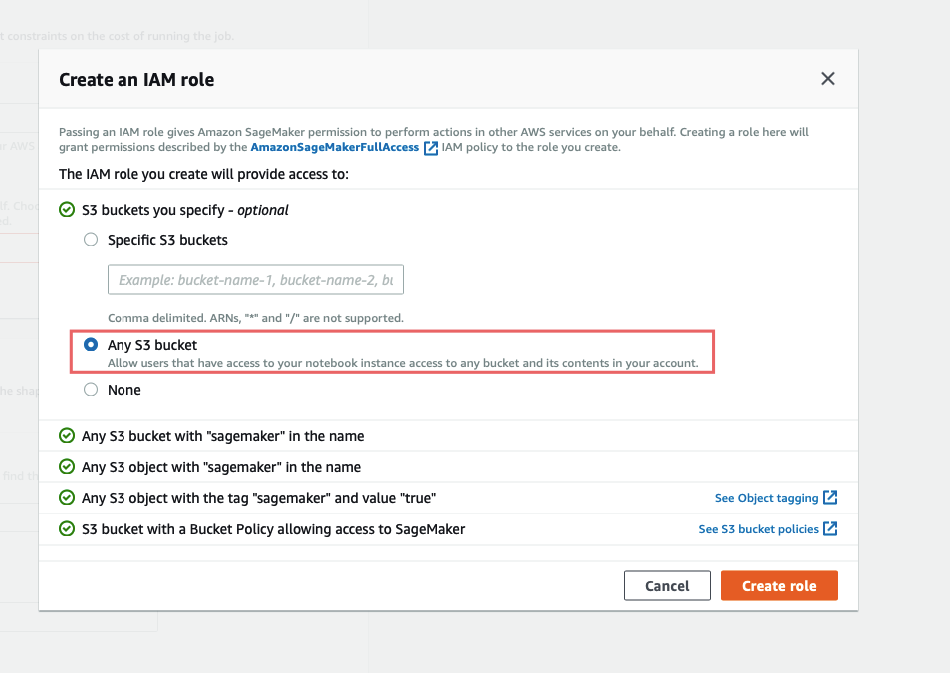
Configuração de entrada:
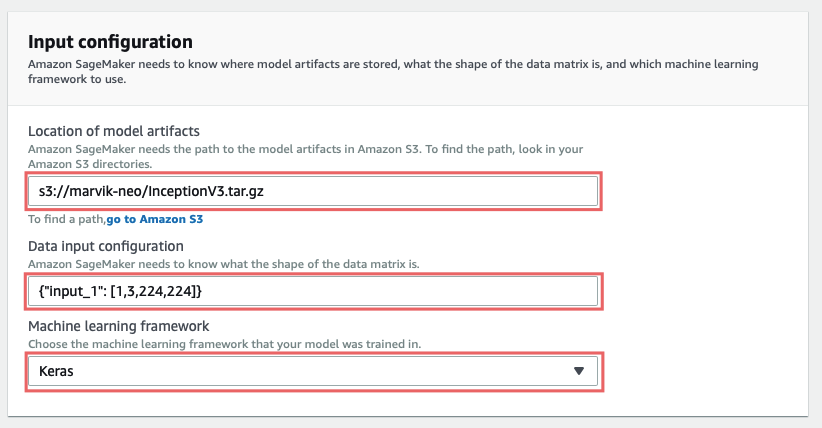
Em Localização dos artefatos do modelo você deve inserir o caminho para o modelo que você carregou, deve começar com s3://.
Configuração de entrada de dados espera {” <input_layer_name>“: [1,<number_image_channels>,<image_height>,<image_width>]} . Você pode obter esses dados fazendo modelo.summary () e procurando as informações da primeira camada:
________________________________________________________________________ Camada (tipo) Número do parâmetro de forma de saída conectado a =================================================================== input_1 (InputLayer) (Nenhuma, 224, 224, 3) 0 ____________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________ conv2d_1 (Conv2D) (Nenhum, 111, 111, 32) 864 input_1 [0] [0] ____________________________________________________________________________...
A camada de entrada do nosso modelo é entrada_1 e olhando para (Nenhum, 224, 224, 3) podemos obter o resto dos números de que precisamos.
Então, no nosso caso, seria {"entrada_1": [1, 3, 224, 224]}, se você olhar com atenção, notará que o os números estão em ordem diferente, isso é muito importante e não funcionará de outra forma.
[perfectpullquote align="full” bordertop="false” cite= "” link= "” color= "” class= "” size=" "]
Se você está curioso para saber por que isso acontece: Neo espera artefatos do modelo Keras em NHWC (Nnúmero de amostras, Hoito, WLargura, Número de Ccanais), mas, estranhamente, a configuração de entrada de dados deve ser especificada em NCHW (NNúmero de amostras, Número de Ccanais, Hoito, W(largura). Para obter mais informações sobre isso, incluindo formatos para PyTorch, Tensorflow ou se seu modelo tiver várias entradas, consulte Quais formatos de dados de entrada o Neo espera?
[/perfect pullquote]
Configuração de saída:

Finalmente, em Local de saída S3 você deve digitar o caminho para uma pasta do S3 na qual deseja que os artefatos de saída sejam salvos.
Ligado Dispositivo alvo você precisa especificar em qual plataforma você vai implantar esse modelo, isso é crucial para que a otimização funcione corretamente. Neste guia, estamos implantando em Nuvem, se você estiver interessado em implantar no Dispositivos Edge fique ligado na Parte 2.
[perfectpullquote align="full” bordertop="false” cite= "” link= "” color= "” class= "” size=" "]
Por que isso é crucial? No nível superficial, ele precisa saber se será executado em GPU ou CPU para otimizar o gráfico de computação, se será executado em GPU pode combinar várias camadas, como conv2d+bn+relu para evitar salvar resultados intermediários desnecessários na memória, obtendo menor latência e menor consumo de memória. E em um nível mais baixo, ele realmente gerará código específico da plataforma, como CUDA ou LLVM IR.[/perfect pullquote]
Tudo o que resta é bater Criare aguarde a conclusão da compilação.
2. Implante o modelo

Até esse ponto, tínhamos:
- Salvou nosso modelo Keras
- Compilou o modelo
Vamos dar uma olhada nas saídas em cada etapa; na etapa 1, obtemos um arquivo contendo todos os dados do modelo, que podem ser usados para inferência carregando-o com Keras' model.load () . No entanto, na etapa 2, os artefatos que Neo retorna não podem mais ser usados com Keras, eles só podem ser executados usando um tempo de execução específico do neo.
Isso significa que você só precisa instalar o tempo de execução do Neo no dispositivo de destino, sem necessidade de keras ou tf, que a propósito economiza uma tonelada de espaço e sobrecarga de instalação.
[perfectpullquote align="full” bordertop="false” cite= "” link= "” color= "” class= "” size=" "]
Isso pode parecer estranho à primeira vista, mas é necessário para atingir a latência mais baixa. Por quê? Bem, quando você salva um modelo do Keras, na verdade está salvando um gráfico, esse gráfico especifica quais operações devem ser feitas e em que ordem. Um exemplo pode ser alimentar a entrada por meio de uma camada densa, obter a saída e passá-la como entrada para uma camada Softmax.
Então, quando é hora de fazer uma inferência, Keras lê o gráfico e executa as operações especificadas para fornecer uma saída.
Depois que Neo compila o modelo, o gráfico agora tem operações que não estão definidas em Keras, como no exemplo anterior conv2d+bn+relu , isso significa que Keras não saberia qual código executar, esse é um dos motivos da necessidade de um tempo de execução específico.
Na verdade, nos artefatos do modelo compilado, há um arquivo que otimizou o código para cada operação no gráfico, que é então usado pelo tempo de execução.
[/perfect pullquote]
Então, já que escolhemos como Dispositivo alvo uma ml_m5 nós vamos para inicie um ubuntu EC2 m5. grande exemplo e instale as dependências necessárias.
sudo apt-get update pip3 install dlr numpy
Em seguida, precisamos fazer o upload dos arquivos compilados para a instância.
Baixar InceptionV3-ml_m5.tar.gz (de Local de saída S3) e extraí-lo. Para fazer o upload, você pode usar scp na sua máquina assim:
<ec2 ip>scp -i "<path to pem file>" compiled.tar ubuntu@: ~/compiled_model_neo.tar
Então, no exemplo, fazemos algumas arrumações:
Observe que os artefatos devem estar todos dentro de uma pasta, neste caso começo.
tar xvf compiled_model_neo.tar mkdir inception mv compiled.params inception/compiled.params mv compiled_model.json inception/compiled_model.json mv compiled.so inception/compiled.so
Agora, tudo o que resta para execute o modelo é criar .py um arquivo pode executá-lo.
vim dlr-neo.py
importe numpy como np de dlr import DLRModel # Carregue o modelo de modelo compilado = DLRModel ('inception', 'cpu') print (“Input”, model.get_input_names ()) # Carregue uma imagem armazenada como uma matriz numpy image = np.load ('inception/image.npy') .astype (np.float32) input_data = {'input_1': image} # Prever saída = model.run (input_data) top1 = np.argmax (out [0]) prob = np.max (out) print (“Classe: %s, probabilidade: %f”% (top1, prob))
Considerações finais
Hoje nós compilado e disponibilizar um modelo keras para um Instância EC2, no entanto, talvez você queira implantar em um dispositivo de ponta, como um NVIDIA Jetson ou um Raspberry Pi, isso não é apenas possível, mas também realmente beneficia da otimização, pois sem ela pode nem mesmo funcionar.



.png)