.png)
Una guía de incorporación a los LLM




Los grandes modelos lingüísticos (LLM) han captado la mayor parte de la atención de la comunidad de IA en los últimos meses. Mantenerse al día sobre este mundo puede parecer caótico y abrumador. Esta publicación pretende resumir los aspectos más destacados de este tema, profundizando en los detalles técnicos de estos modelos sin descuidar la visión global.
Los LLM en pocas palabras
Los LLM son un subconjunto de modelos lingüísticos que tienen un número particularmente alto de parámetros (normalmente miles de millones) y son capaces de generar texto similar al humano. Estos modelos, como el GPT-3, se basan en grandes cantidades de texto y pueden realizar una variedad de tareas relacionadas con el lenguaje, como la traducción de idiomas, la finalización de textos e incluso la redacción de artículos e historias. Se basan en gran medida en la arquitectura Transformer (La atención es todo lo que necesitas, 2017) que se compone de dos bloques: el codificador y el decodificador. La función del codificador consiste en procesar la entrada y «codificar» la información que se pasa al decodificador, utilizando el mecanismo de atención durante todo el mensaje. El decodificador genera la salida token por token utilizando la salida del codificador y sus propios tokens generados de forma autorregresiva. Esto significa que cada token de salida se predice teniendo en cuenta los tokens que le preceden en la oración, de forma causal. Se lanzaron diferentes tipos de modelos utilizando uno o ambos tipos de bloques transformadores, agrupados principalmente en tres categorías:
- Similar al GPT: también llamado autorregresivo, solo modelos de decodificadores.
- Similar a Bert: también llamado codificación automática modelos, solo codificador. Tienen acceso total a todas las entradas sin necesidad de una máscara. Por lo general, estos modelos construyen una representación bidireccional de la oración completa.
- Similar a BART/T5: también llamado secuencia a secuencia o codificador-decodificador.
Los modelos generativos pertenecen a las familias autorregresivas o de secuencia a secuencia, ya que el bloque decodificador es el responsable de la generación del lenguaje.
¿Por qué modelos GRANDES?
El lenguaje natural es complejo y es fácil pensar que necesitamos grandes arquitecturas para modelarlo. Pero, ¿qué entendemos por grande? Google BERT, pionera de los modelos basados en Transformers, comprende de 110 millones (base) a 340 millones de parámetros (grandes). Los LLM varían entre decenas y cientos de miles de millones de parámetros, lo que significa órdenes de magnitud superiores a los de otros modelos lingüísticos «tradicionales», y por tradicional nos referimos a los que se descubrieron hace 4 o 5 años.
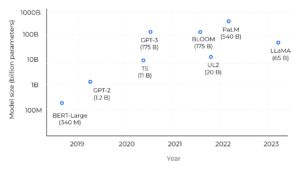
Comparación de tallas de modelos en los últimos años.
¡El salto es enorme! En primer lugar, estamos hablando de modelos básicos: modelos de gran tamaño entrenados con enormes cantidades de datos sin etiquetar, normalmente mediante un aprendizaje autosupervisado, capaces de realizar una amplia variedad de tareas. Estos modelos están diseñados para adaptarse con precisión a las tareas posteriores, e incluyen aún más datos sobre este paso. Está demostrado que cuando la escala de parámetros supera un cierto nivel, estos modelos ampliados muestran algunas habilidades especiales que no están presentes en los modelos lingüísticos a pequeña escala, como la capacidad de seguir aprendizaje en contexto (es decir, adaptar su resultado a unos pocos ejemplos a partir de indicaciones). Sin embargo, solo aumentar el tamaño del modelo no es suficiente para escalar la capacidad. Los LLM requieren una enorme cantidad de datos para capturar los matices del idioma con precisión. C4 Common Crawl Corpus, uno de los conjuntos de datos de preentrenamiento más utilizados, contiene unos 750 GB de datos, lo que da como resultado 175 000 millones de tokens. Los conjuntos de datos se suelen utilizar en combinación para ampliar sus conocimientos con otras fuentes, como Wikipedia, libros, código de Github o publicaciones de StackExchange/StackOverflow. Dado que los LLM se entrenan y ajustan con precisión estos conjuntos de datos, la información se «memoriza» en las ponderaciones del modelo, lo que solo es posible si se tienen suficientes parámetros para ajustarlos. Hacer funcionar estos modelos de gran tamaño no es algo trivial en términos de hardware. Si bien las grandes empresas pueden pagar la infraestructura, la comunidad se esfuerza por optimizar los modelos para que funcionen con menos recursos (con técnicas como Lora-izquierda o mediante el uso de int8 precision).
Arquitecturas publicadas (hasta la fecha)
Exploraremos con más detalle los modelos básicos que han protagonizado los últimos años de investigación y desarrollo sobre la generación de idiomas. Es evidente que empresas líderes como Google, Meta AI y OpenAI invierten en la formación de estos modelos y, algunas de ellas, se abren a la comunidad con fines comerciales o de investigación. Muchos de ellos están disponibles en el Cara abrazada plataforma, junto con ajustes personalizados. Del pasado al presente, los primeros modelos sobresalientes fueron el BART (2019, codificador-decodificador) y el GPT-3 (2020, autorregresivo). BART se diseñó para ser una alternativa más flexible a los modelos anteriores, como BERT y GPT-2, que eran autorregresivos o bidireccionales, pero no ambos. A BART le siguen el T0, el T5, el mT5 (T5 multilingüe) y el UL2. Se trata de modelos basados en transformadores capaces de realizar tareas como la traducción de idiomas, el resumen de textos y la respuesta a preguntas. Muchos de ellos (los que son propiedad de Google) se ajustaron con una técnica llamada «Flan» (que significa Fine-tuned Language Net), que mejoraba el rendimiento desde cero al aplicar el ajuste de las instrucciones. Como el artículo dice: «Dado que la fase de ajuste de las instrucciones de FLAN solo requiere un número reducido de actualizaciones en comparación con la gran cantidad de cálculos que implica el entrenamiento previo del modelo, es el postre metafórico del curso principal del preentrenamiento». Crearon un conjunto de datos de instrucciones mezclando conjuntos de datos existentes de tareas de comprensión del lenguaje natural (NLU) y generación del lenguaje natural (NLG), y redactaron plantillas que utilizan instrucciones de lenguaje natural para describir la tarea de cada conjunto de datos. Para aumentar la diversidad, también incluyeron algunas plantillas que «le dieron la vuelta a la tarea» (por ejemplo, para la clasificación de opiniones, escribieron plantillas en las que pedían que se generara una reseña de una película).

Conjuntos de datos y tareas utilizados en FLAN (azul: NLU, verde azulado: NLG).
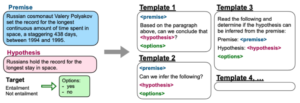
Instrucciones para NLI generadas en FLAN.
Pero, ¿por qué nadie habla de Flan? Para la familia autorregresiva y después de GPT-3 (2020) llegó InstructGPT (2022). El GPT-3 fue diseñado para completarlo rápidamente, entrenado para predecir la siguiente palabra en un gran conjunto de datos de texto de Internet. En cambio, InstructGPT va mucho más allá de recibir instrucciones para realizar la tarea lingüística que el usuario desea. El auge comenzó a finales de 2022, cuando se lanzó OpenAI Chat GPT, un modelo similar a InstructGpt, que está entrenado para seguir una instrucción en un mensaje y dar una respuesta detallada. A medida que se hizo público, los usuarios de todo el mundo empezaron a experimentar y a descubrir sus capacidades por sí mismos. Otros modelos similares al GPT que aparecieron últimamente fueron OPT, Palm, Bloom, Dolly y LLama. Este último se lanzó solo con licencia de investigación, pero muchos desarrolladores aprovecharon el modelo y lo ajustaron con sus propios conjuntos de datos. Desde entonces, nacieron modelos adaptados a las instrucciones, como Stanford Alpaca, Vicuña, Koala (y muchos guanacos).

Modelos de cimientos relevantes (violeta) y sus versiones ajustadas (verde).
Atributos e innovación
¿Qué más debemos saber sobre estos modelos? ¿Cuáles son las tendencias en este tema? Los siguientes son algunos de los conceptos que se utilizan en los modelos SOTA:
- Cadena de pensamiento: Hacer que el modelo explique paso a paso cómo llega a una respuesta, una técnica conocida como Cadena de pensamiento o COT (Wei et al., 2022) . Compensación: el COT puede aumentar tanto la latencia como el costo debido al aumento del número de tokens de salida.
- RLHF: utilizar métodos del aprendizaje por refuerzo para optimizar directamente un modelo lingüístico con comentarios humanos. Esta técnica entrena a un modelo secundario para que «piense como un ser humano» (llamado modelo de recompensa) y puntuar los resultados del modelo principal. Puede encontrar más información sobre este tema en Ilustrando el aprendizaje por refuerzo a partir de la retroalimentación humana (RLHF).
- Ingeniería rápida: también conocida como In-Context Prompting, se refiere a los métodos para comunicarse con la LLM escribiendo la entrada del modelo para conducir su comportamiento y lograr el resultado deseado.
- LLM con recuperación aumentada: Los modelos lingüísticos de recuperación se utilizan en los casos en los que queremos que el modelo lingüístico genere una respuesta basada en datos específicos, en lugar de basarse en los datos de entrenamiento del modelo. Esto se explica con más detalle en la siguiente sección.
Tuberías de recuperación
Si bien la capacidad de codificar el conocimiento es especialmente importante para ciertas tareas de PNL, los modelos descritos memorizan el conocimiento de manera implícita, lo que dificulta determinar qué conocimiento se ha almacenado y dónde se guarda en el modelo. Además, el espacio de almacenamiento y, por lo tanto, la precisión del modelo, están limitados por el tamaño de la red. Para captar más conocimiento mundial, la práctica estándar consiste en entrenar redes grandes, que pueden ser prohibitivamente lentas o costosas. La capacidad de recuperar textos que contengan conocimientos explícitos mejoraría la eficacia de la formación previa y, al mismo tiempo, permitiría al modelo funcionar correctamente en tareas que requieren un uso intensivo de conocimientos sin utilizar miles de millones de parámetros. Esto evitaría que el modelo provocara alucinaciones (en lugar de disponer de la información necesaria para responder a la pregunta, la red la inventa de forma realista pero imprecisa). Las canalizaciones de recuperación tienen los documentos almacenados e indexados para su posterior recuperación. En el momento de la consulta, los documentos más relevantes para la consulta se recuperan y se pasan a un LLM, que es responsable de generar la respuesta. Los marcos de código abierto útiles para crear canalizaciones personalizadas son Pajar, Cadena LANG y Índice Llama.
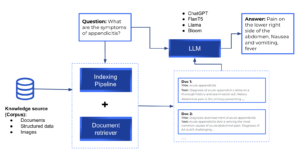
Canalización general de recuperación.
Revisión final
Hasta ahora hemos visto el panorama general de los LLM y su potencial en la comprensión y generación del lenguaje natural. Hemos analizado los aspectos básicos de los modelos de lenguajes de gran tamaño y las capacidades de los modelos con mil millones de parámetros, y descubrimos las arquitecturas más relevantes hasta la fecha. Hacemos explícito que la innovación no se debe a los componentes de la arquitectura (ya que los LLM se basan en bloques de Transformer) sino a la formación y el perfeccionamiento de los modelos. Desde nuestro punto de vista, ¿cuál es la causa de esta explosión de modelos lingüísticos? Aprovechar los modelos de gran tamaño que vienen previamente entrenados en un corpus enorme permite centrarse únicamente en afinar las tareas posteriores. Además, en el caso de algunos modelos, como ChatGPT, es posible que ni siquiera necesites realizar ningún ajuste. Desde que OpenAI lanzó su modelo al público, se ha hecho mucha publicidad en torno a este tema y muchos desarrolladores quieren estar a la altura, inundando las redes sociales con sus propias implementaciones. Relájese, la mayoría de ellas se basan en las mismas estructuras e introducen una nueva técnica o conjunto de datos de ajuste (como es el caso de todas las crías de llama). Muchas personas creen que ChatGPT tiene el potencial de reemplazar a los motores de búsqueda debido a su gran cantidad de información y a la agregación de respuestas personalizadas. Google incluso ha dado instrucciones a algunos equipos para que cambien su enfoque hacia el desarrollo de productos de inteligencia artificial, mientras que Microsoft ha entrado en el mercado de los chatbots con Bing Chat, que combina ChatGPT con su motor de búsqueda. Sin embargo, para reemplazar completamente a los motores de búsqueda, los modelos de ChatGPT deben citar las fuentes para sus respuestas, por lo que los motores de búsqueda aún tienen la ventaja a la hora de proporcionar información precisa y confiable. Además, los motores de búsqueda tienen la capacidad de rastrear la web y recopilar información de una amplia gama de fuentes, mientras que ChatGPT se basa en datos preexistentes. Las técnicas de recuperación pueden resolver este problema, junto con el uso de agentes, para mejorar las capacidades de los modelos de gran tamaño. Cosas grandiosas como GPT automático están llegando! En conclusión, el auge de los grandes modelos lingüísticos (LLM) ha revolucionado el procesamiento del lenguaje natural y ha abierto interesantes posibilidades para la inteligencia artificial. Gracias a la capacidad de preparar modelos con cantidades masivas de datos, los LLM pueden lograr un rendimiento notable en una amplia gama de tareas lingüísticas, desde la clasificación de textos hasta la traducción automática. Si bien la arquitectura de los LLM se basa en los bloques Transformer, su verdadero poder reside en el entrenamiento y el ajuste de estos modelos. Si bien la ejecución de estos modelos de gran tamaño puede ser un desafío en términos de hardware, la comunidad está trabajando para optimizarlos para que funcionen con menos recursos. Con el continuo desarrollo de los LLM, podemos esperar aún más avances en la comprensión y la generación del lenguaje natural en el futuro.



.png)