.png)
Um guia de integração para LLMs




Grandes modelos de linguagem (LLMs) estão capturando a maior parte da atenção da comunidade de IA nos últimos meses. Manter-se atualizado sobre esse mundo pode parecer caótico e bastante opressor. Esta postagem pretende resumir os destaques desse tópico, mergulhando nos detalhes técnicos desses modelos sem negligenciar a visão global.
LLMs em poucas palavras
Os LLMs são um subconjunto de modelos de linguagem que têm um número particularmente alto de parâmetros (normalmente bilhões) e são capazes de gerar texto semelhante ao humano. Esses modelos, como o GPT-3, são treinados em grandes quantidades de texto e podem realizar uma variedade de tarefas relacionadas ao idioma, como tradução de idiomas, preenchimento de texto e até mesmo composição de artigos e histórias. Eles dependem muito da arquitetura Transformer (Atenção é tudo que você precisa, 2017) que é composto por dois blocos: o codificador e o decodificador. A função do codificador é processar a entrada e “codificar” as informações que são passadas para o decodificador, usando o mecanismo de atenção em todo o prompt. O decodificador gera a saída token por token usando a saída do codificador e seus próprios tokens gerados de forma autorregressiva. Isso significa que cada token de saída é previsto observando os tokens que vieram antes dele na frase, de uma forma causal. Diferentes tipos de modelos foram lançados usando um ou ambos os tipos de blocos de transformadores, agrupados principalmente em três categorias:
- Tipo GPT: também chamado autorregressivo, apenas modelos de decodificadores.
- Tipo Bert: também chamado codificação automática modelos, somente codificador. Eles têm acesso total a todas as entradas sem a necessidade de uma máscara. Normalmente, esses modelos constroem uma representação bidirecional de toda a frase.
- Tipo BART/T5: também chamado sequência a sequência ou codificador-decodificador.
Os modelos generativos pertencem às famílias autorregressivas ou sequência-a-sequência, já que o bloco decodificador é o responsável pela geração da linguagem.
Por que modelos GRANDES?
A linguagem natural é complexa e é fácil pensar que precisamos de grandes arquiteturas para modelá-la. Mas o que queremos dizer com grande? Google BERT, pioneira nos modelos baseados em Transformers, compreende parâmetros de 110M (base) a 340M (grandes). Os LLMs variam de dezenas a centenas de bilhões de parâmetros, o que significa ordens de magnitude maiores do que outros modelos de linguagem “tradicionais” - e por tradicional queremos dizer aqueles descobertos há 4-5 anos.
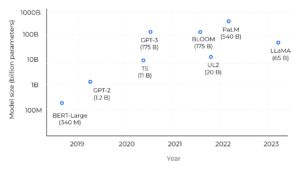
Comparação do tamanho do modelo nos últimos anos.
O salto é enorme! Em primeiro lugar, estamos falando sobre modelos básicos - grandes modelos treinados em enormes quantidades de dados não rotulados, geralmente por meio de aprendizado autosupervisionado, capazes de uma ampla variedade de tarefas. Esses modelos foram projetados para serem ajustados às tarefas posteriores, incluindo ainda mais dados nesta etapa. Está provado que quando a escala de parâmetros excede um determinado nível, esses modelos ampliados mostram algumas habilidades especiais que não estão presentes em modelos de linguagem de pequena escala, como a capacidade de seguir aprendizagem contextualizada (ou seja, adaptar sua saída a alguns exemplos de solicitação). Mas apenas aumentar o tamanho do modelo não é suficiente para escalar a capacidade. Os LLMs exigem uma grande quantidade de dados para capturar as nuances da linguagem com precisão. Corpus C4 Common Crawl, um dos conjuntos de dados de pré-treinamento mais usados, contém cerca de 750 GB de dados, resultando em 175 bilhões de tokens. Os conjuntos de dados geralmente são usados em combinação para expandir seus conhecimentos com outras fontes, como Wikipédia, Livros, código do Github ou postagens do StackExchange/StackOverflow. Como os LLMs são treinados e ajustados nesses conjuntos de dados, as informações são, portanto, “memorizadas” nos pesos do modelo, o que só é possível se houver parâmetros suficientes para ajustar. Conseguir executar esses modelos grandes não é trivial em termos de hardware. Embora as grandes empresas possam pagar pela infraestrutura, a comunidade está se esforçando para otimizar os modelos para que funcionem com menos recursos (com técnicas como Lora à esquerda ou usando a precisão int8).
Arquiteturas lançadas (até esta data)
Exploraremos com mais detalhes os modelos básicos que foram os protagonistas dos últimos anos de pesquisa e desenvolvimento em geração de idiomas. Há um claro destaque de empresas líderes como Google, Meta AI e OpenAI investindo no treinamento desses modelos e, algumas delas, na abertura à comunidade para fins de pesquisa e/ou comerciais. Muitos deles estão disponíveis no Abraçando o rosto plataforma, junto com ajustes finos personalizados. Do passado ao presente, os primeiros modelos excepcionais foram o BART (2019, codificador-decodificador) e o GPT-3 (2020, autorregressivo). BART foi projetado para ser uma alternativa mais flexível aos modelos anteriores, como BERT e GPT-2, que eram autorregressivos ou bidirecionais, mas não ambos. Seguindo o BART estão T0, T5, mT5 (T5 multilíngue) e UL2. Esses são modelos baseados em transformadores capazes de realizar tarefas como tradução de idiomas, resumo de texto e resposta a perguntas. Muitos deles (os de propriedade do Google) foram ajustados usando uma técnica chamada “Flan” (para Fine-Tuned Language Net), melhorando o desempenho zero aplicando o ajuste de instruções. Como o papel diz: “Como a fase de ajuste de instruções do FLAN requer apenas um pequeno número de atualizações em comparação com a grande quantidade de computação envolvida no pré-treinamento do modelo, é a sobremesa metafórica do curso principal do pré-treinamento”. Eles criaram um conjunto de dados de instruções misturando conjuntos de dados existentes de tarefas de compreensão de linguagem natural (NLU) e geração de linguagem natural (NLG) e criaram modelos que usam instruções de linguagem natural para descrever a tarefa de cada conjunto de dados. Para aumentar a diversidade, eles também incluíram alguns modelos que “inverteram a tarefa” (por exemplo, para classificação de sentimentos, eles escreveram modelos pedindo a geração de uma crítica de filme).

Conjuntos de dados e tarefas usados no FLAN (azul: NLU, azul-petróleo: NLG).
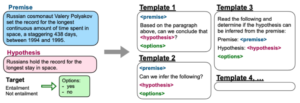
Instruções para NLI geradas em FLAN.
Mas por que ninguém fala sobre Flan? Para a família autorregressiva e depois do GPT-3 (2020) veio o InstructGPT (2022). O GPT-3 foi projetado para preenchimento imediato, treinado para prever a próxima palavra em um grande conjunto de dados de texto da Internet. Em vez disso, o InstructGPT vai muito além de ser treinado em instruções para realizar a tarefa de idioma que o usuário deseja. O boom começou no final de 2022, quando a OpenAI lançou Bate-papo GPT, um modelo irmão do InstructGPT, que é treinado para seguir uma instrução em um piscar de olhos e fornecer uma resposta detalhada. À medida que ela foi tornada pública, usuários de todo o mundo começaram a experimentar e descobrir suas capacidades sozinhos. Outros modelos semelhantes ao GPT que surgiram recentemente foram OPT, Palm, Bloom, Dolly e LLama. O último foi lançado apenas com licença de pesquisa, mas muitos desenvolvedores aproveitaram o modelo e o aperfeiçoaram com seus próprios conjuntos de dados. Desde então, nasceram modelos adaptados às instruções, como Stanford Alpaca, Vicuna, Koala (e muitos guanacos).

Modelos de base relevantes (roxo) e suas versões ajustadas (verde).
Atributos e inovação
O que mais devemos saber sobre esses modelos? Quais são as tendências nesse tópico? A seguir estão alguns dos conceitos usados nos modelos SOTA:
- Cadeia de pensamento: Solicitar que o modelo explique passo a passo como ele chega a uma resposta, uma técnica conhecida como Cadeia de pensamento ou COT (Wei et al., 2022) . Combinação: o COT pode aumentar a latência e o custo devido ao aumento do número de tokens de saída.
- RLHF: usando métodos de aprendizado por reforço para otimizar diretamente um modelo de linguagem com feedback humano. Essa técnica treina um modelo secundário para “pensar como um humano” (chamado modelo de recompensa) e pontuar os resultados do modelo principal. Mais informações sobre esse tópico podem ser encontradas em Ilustrando o aprendizado por reforço a partir do feedback humano (RLHF).
- Engenharia rápida: também conhecido como In-Context Prompting, refere-se a métodos de como se comunicar com o LLM escrevendo a entrada do modelo para conduzir seu comportamento até o resultado desejado.
- LLMs com recuperação aumentada: Os modelos de linguagem de recuperação são usados em casos em que queremos que o modelo de linguagem gere uma resposta com base em dados específicos, em vez de com base nos dados de treinamento do modelo. Isso é explicado mais detalhadamente na próxima seção.
Pipelines de recuperação
Embora a capacidade de codificar conhecimento seja especialmente importante para certas tarefas de PNL, os modelos descritos memorizam o conhecimento implicitamente, tornando difícil determinar qual conhecimento foi armazenado e onde é mantido no modelo. Além disso, o espaço de armazenamento e, portanto, a precisão do modelo, são limitados pelo tamanho da rede. Para capturar mais conhecimento mundial, a prática padrão é treinar grandes redes, o que pode ser proibitivamente lento ou caro. A capacidade de recuperar texto contendo conhecimento explícito melhoraria a eficiência do pré-treinamento, ao mesmo tempo em que permitiria que o modelo tivesse um bom desempenho em tarefas intensivas em conhecimento sem usar bilhões de parâmetros. Isso evitaria que o modelo tivesse alucinações (em vez de ter as informações para responder à consulta, a rede a inventa de forma realista, mas imprecisa). Os pipelines de recuperação têm documentos armazenados e indexados para recuperação posterior. No momento da consulta, os documentos mais relevantes para a consulta são recuperados e passados para um LLM, que é responsável por gerar a resposta. Estruturas de código aberto úteis para criar pipelines personalizados são Palheiro, LangChain e Índice LLAMA.
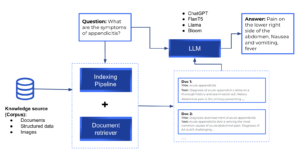
Pipeline geral de recuperação.
Revisão final
Até agora, vimos o panorama geral dos LLMs e seu potencial na compreensão e geração de linguagem natural. Examinamos os fundamentos dos modelos de grandes linguagens e as capacidades dos modelos de bilhões de parâmetros e descobrimos as arquiteturas mais relevantes até agora. Deixamos explícito que a inovação não se deve aos componentes da arquitetura (já que os LLMs são baseados em blocos Transformer), mas ao treinamento e ajuste fino dos modelos. Do nosso ponto de vista, qual é a causa dessa explosão nos modelos de linguagem? Tirar proveito de modelos grandes que são pré-treinados em um grande corpus permite que você se concentre apenas no ajuste fino de sua tarefa posterior. E, para alguns modelos como o ChatGPT, talvez você nem precise de nenhum ajuste fino. Desde que a OpenAI lançou seu modelo ao público, muito entusiasmo se espalhou em torno desse tópico e muitos desenvolvedores querem estar à altura, inundando as redes sociais com suas próprias implementações. Relaxe, a maioria deles confia nas mesmas estruturas e introduz uma nova técnica de ajuste fino ou conjunto de dados (como é o caso de todos os bebês de lhama). Muitas pessoas acreditam que o ChatGPT tem o potencial de substituir os mecanismos de pesquisa devido à sua grande quantidade de informações e à agregação de respostas personalizadas. O Google até instruiu algumas equipes a mudarem seu foco para o desenvolvimento de produtos de IA, enquanto a Microsoft entrou no mercado de chatbots com o Bing Chat, que combina o ChatGPT com seu mecanismo de busca. No entanto, para substituir totalmente os mecanismos de pesquisa, os modelos do ChatGPT precisam citar fontes para suas respostas, portanto, os mecanismos de pesquisa ainda têm a vantagem de fornecer informações precisas e confiáveis. Além disso, os mecanismos de pesquisa têm a capacidade de rastrear a web e coletar informações de uma ampla variedade de fontes, enquanto o ChatGPT depende de dados pré-existentes. As técnicas de recuperação podem resolver esse problema, juntamente com o uso de agentes, para aumentar as capacidades de grandes modelos. Coisas incríveis como GPT automático estão chegando! Em conclusão, o surgimento dos modelos de linguagem grande (LLMs) revolucionou o processamento de linguagem natural e abriu possibilidades interessantes para a inteligência artificial. Com a capacidade de pré-treinar modelos em grandes quantidades de dados, os LLMs podem alcançar um desempenho notável em uma ampla variedade de tarefas linguísticas, desde classificação de texto até tradução automática. Embora a arquitetura dos LLMs seja baseada em blocos de transformadores, seu verdadeiro poder está no treinamento e no ajuste fino desses modelos. Embora a execução desses modelos grandes possa ser um desafio em termos de hardware, a comunidade está trabalhando para otimizá-los para que funcionem com menos recursos. Com o desenvolvimento contínuo dos LLMs, podemos esperar ainda mais avanços na compreensão e geração da linguagem natural no futuro.



.png)