.png)
Uma introdução aos modelos de difusão e difusão estável




Introdução
Imagine um mundo onde a criatividade transcende as limitações dos pincéis, da argila e da tela. Foi em 2022, na competição de arte da Feira Estadual do Colorado, que uma inscrição inovadora desafiou os limites convencionais da criação artística. A obra-prima de Jason M. Allen, “Théâtre d'Opéra Spatial” ganhou o primeiro prêmio e desafiou a convenção. Não por meios tradicionais, mas com a ajuda de um programa de IA chamado No meio da jornada, que usa um modelo de difusão para gerar imagens. Ao transformar um aviso de texto em uma imagem hiper-realista, a criação de Allen não apenas cativou o público e os jurados, mas também desencadeou uma forte reação de artistas que o acusaram de, essencialmente, trapacear.

Entrada do “Théâtre d'Opéra Spatial” para a Feira Estadual do Colorado.
No entanto, a ascensão do Midjourney e de outros avanços da IA apenas mostra o que é possível com os modelos de difusão. Esses modelos generativos se tornaram uma força a ser reconhecida, atraindo atenção e ultrapassando os limites da síntese de imagens anteriormente regida por Redes adversárias generativas (GANs) [1]. Na verdade, diz-se que os modelos de difusão são superando GANs na síntese de imagens [2]. Neste artigo, exploramos os fundamentos teóricos dos modelos de difusão, descobrindo seu funcionamento interno e entendendo seus componentes fundamentais e sua notável eficácia. Ao longo do caminho, destacaremos uma das famílias mais populares de modelos de difusão: a difusão estável. Junte-se a nós para descobrir os segredos por trás do sucesso dos modelos de difusão e como eles estão revolucionando a geração de imagens. Ao final, você terá uma compreensão profunda do potencial transformador deles, inspirando o reino da criatividade impulsionada pela IA.
Modelos de difusão
Os modelos de difusão são modelos generativos que aprendem com os dados durante o treinamento e geram exemplos semelhantes com base no que aprenderam. Esses modelos se inspiram na termodinâmica de não equilíbrio e alcançaram qualidade de ponta na geração de várias formas de dados. Alguns exemplos incluem a geração de imagens de alta qualidade e até mesmo áudio (por exemplo. Modelos de difusão de áudio [3]). Se você estiver interessado em como os modelos de difusão podem ser aplicados em configurações de áudio, confira nosso blog em clonagem de voz. Em poucas palavras, os modelos de difusão funcionam corrompendo os dados de treinamento por meio da adição de ruído gaussiano (chamado processo de difusão direta) e, em seguida, aprender como recuperar as informações originais revertendo esse processo de ruído passo a passo (chamado processo de difusão reversa). Uma vez treinados, esses modelos podem gerar novos dados amostrando o ruído gaussiano aleatório e passando-o pelo processo de eliminação de ruído aprendido. Os modelos de difusão vão além da simples criação de imagens de alta qualidade. Eles ganharam popularidade ao enfrentar os conhecidos desafios associados ao treinamento adversário em GANs. Os modelos de difusão oferecem vantagens em termos de estabilidade de treinamento, eficiência, escalabilidade, e paralelização. Nas seções a seguir, vamos nos aprofundar nos detalhes dos modelos de difusão. Vamos explorar o processo de difusão direta, a processo de difusão reversae uma visão geral das etapas envolvidas no processo de treinamento. Além disso, também obteremos uma intuição sobre o cálculo do função de perda. Ao examinar esses componentes, adquiriremos uma compreensão abrangente de como os modelos de difusão funcionam e como eles alcançam resultados impressionantes.
Processo de difusão direta
O processo de difusão direta consiste em adicionar gradualmente ruído gaussiano a uma imagem de entrada, passo a passo, para um total de T etapas. Na etapa 0, temos a imagem original, na etapa 1, uma imagem levemente corrompida que fica ainda mais corrompida passo a passo até que todas as informações da imagem original sejam perdidas.

Processo de difusão direta [4]
Para formalizar esse processo, podemos vê-lo como um processo fixo Cadeia Markov com passos T, onde a imagem em timestep t mapeia para seu estado subsequente em timestep t+1. Dessa forma, cada etapa depende apenas da anterior, o que nos permite derivar uma fórmula de formato fechado para obter a imagem corrompida em qualquer etapa de tempo desejada, ignorando a necessidade de computação iterativa.

Formulação de difusão direta [4]
Consequentemente, essa fórmula de forma fechada permite a amostragem direta de xem qualquer etapa de tempo, acelerando significativamente o processo de difusão direta.
Agendadores
Além disso, a adição de ruído em cada etapa segue um padrão deliberado. UM Agendadora determina a quantidade de ruído a ser adicionada. No original Artigo sobre modelos probabilísticos de difusão de ruído (DDPM) [4], os autores definem um cronograma linear que varia β de 0,0001 no passo de tempo 0 a 0,02 no passo de tempo T. No entanto, várias alternativas ganharam popularidade, como o esquema de cosseno introduzido no Artigo sobre modelos probabilísticos de difusão de denoising aprimorados [5]. Por exemplo, a imagem a seguir mostra a diferença entre usar um cronograma linear e um esquema de cosseno para o processo de difusão direta. Um cronograma linear é exibido na primeira linha, enquanto a segunda linha demonstra o cronograma de cosseno aprimorado.

Programadores lineares e cossenos, extraídos do artigo DDPM aprimorado [5]
Os autores do artigo Improved DDPM argumentam que o cronograma de cosseno oferece desempenho superior. Um cronograma linear pode levar a uma rápida perda de informações na imagem de entrada. Como resultado, isso geralmente leva a um processo de difusão abrupto. Em contraste, o esquema do cosseno fornece uma degradação mais suave. Portanto, permite que as etapas posteriores operem em imagens que não estão completamente sobrecarregadas pelo ruído.
Processo de difusão reversa
Ao contrário do processo de difusão direta, o processo de difusão reversa representa um desafio computacional, pois a formulação de q (x|x) se torna intratável ou não computável. Para enfrentar os desafios do processo de difusão reversa, os modelos de aprendizado profundo se destacam, aproximando esse elusivo processo de difusão reversa com uma rede neural.
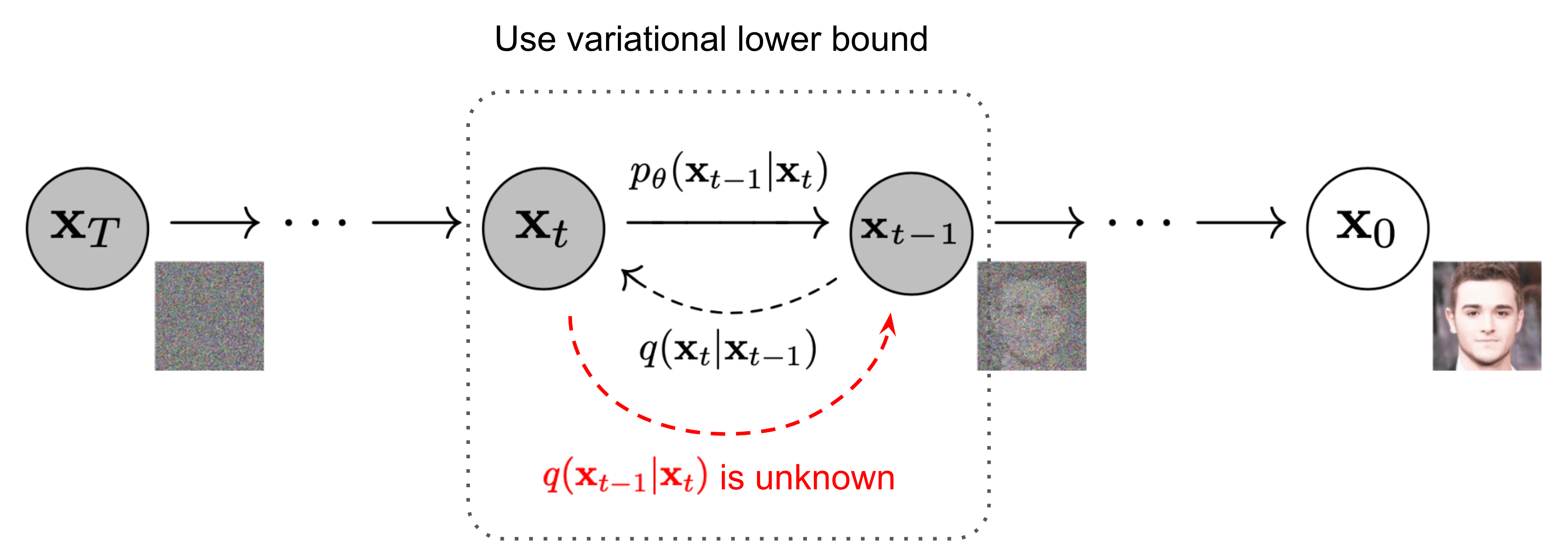
Processo de difusão reversa [6]
De um modo geral, o papel dessa rede neural é prever todo o ruído presente na imagem em um determinado intervalo de tempo t. Então, comparando essa previsão com o ruído real adicionado à imagem, a rede pode ser treinada. No momento da inferência, essas redes ainda preveem todo o ruído presente na imagem no intervalo de tempo t e, em seguida, basta remover uma fração do ruído presente de acordo com o Scheduler usado. Como resultado, ao prever o ruído no passo de tempo t, podemos ficar tentados a tentar recuperar a imagem original em apenas uma etapa. No entanto, alguns experimentos empíricos mostraram que etapas menores são necessárias para alcançar maior estabilidade. Daí a necessidade de remover apenas uma fração do ruído presente na imagem na etapa de tempo t para obter a imagem na etapa de tempo t-1. Alguns artigos e blogs podem ser enganosos no sentido de que, ao lê-los, as pessoas tendem a acreditar que a rede prevê o ruído adicionado pelo timestep t-1 até timestep São A.Embora isso possa ser esclarecido examinando o código fornecido por seus autores.
Arquitetura de rede neural
Você pode se perguntar sobre a arquitetura dessa rede neural. De um modo geral, os modelos de difusão usam algum tipo de variante U-Net para aproximar o processo de difusão reversa. Essa escolha decorre da popularidade da U-Net na comunidade de Visão Computacional. Além disso, parece uma ótima opção, considerando que o único requisito é que a entrada e a saída do modelo de difusão mantenham dimensionalidade idêntica, exceto nos modelos de difusão de superresolução [7].
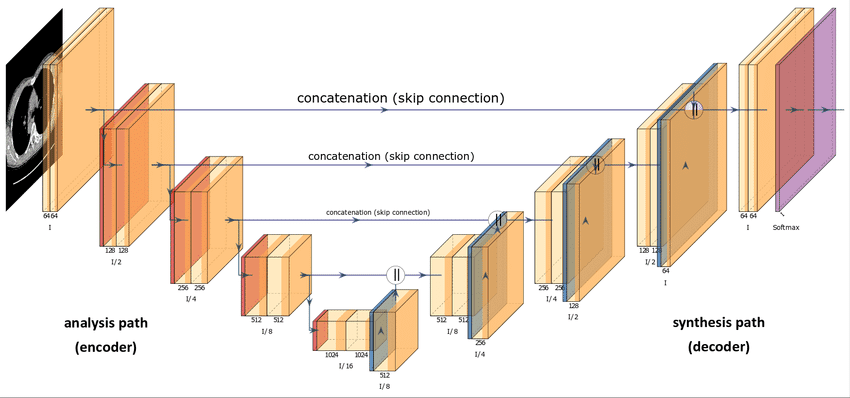
Arquitetura U-Net [8]
Com relação aos detalhes de implementação descritos no documento do DDPM, as principais opções de arquitetura envolvem:
- O codificador e decodificador os caminhos têm o mesmo número de níveis, incorporando um gargalo entre eles.
- Cada estágio do codificador consiste em dois blocos residuais com redução da resolução convolucional, exceto no nível final.
- Cada estágio do decodificador consiste em três blocos residuais. Além disso, os autores definem x2 blocos de aumento de amostragem do vizinho mais próximo com convoluções para restaurar a entrada do nível anterior.
- O caminho do decodificador se conecta a cada estágio no caminho do codificador por meio de pular conexões.
- O uso de módulos de atenção em uma única resolução de mapa de recursos dentro do modelo.
- Além disso, o intervalo de tempo t é codificado em um incorporação de tempo. Isso é bastante semelhante ao Codificação posicional sinusoidal apresentado no Papel do transformador [9].
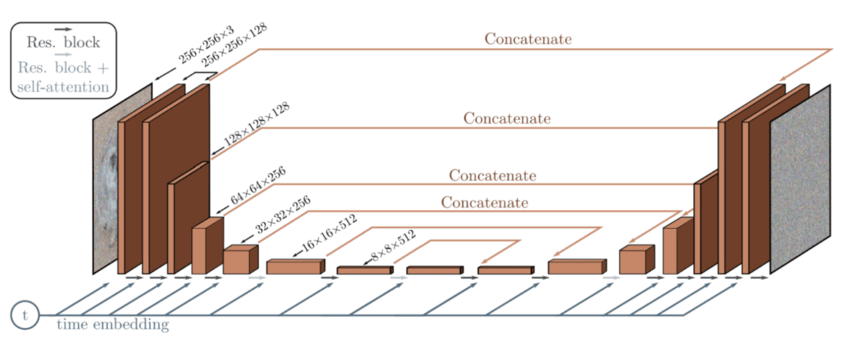
Arquitetura do modelo de difusão baseada na U-Net [10]
Essas incorporações temporais ajudam a rede neural a obter certas informações sobre em qual estado (etapa) a imagem está atualmente. Isso é útil para saber se há mais ou menos ruído atualmente presente na imagem, fazendo com que o modelo subtraia mais ou menos ruído. De um modo geral, em intervalos de tempo mais baixos, o processo de difusão direta adiciona menos ruído do que em intervalos de tempo mais altos. Como exemplo, é assim que todo o processo de difusão direta/reversa se parece:

Processo de difusão direta e reversa [11]
Cálculo de perdas
Para treinar um modelo de difusão, o objetivo é encontrar as transições reversas de Markov que maximizem a probabilidade dos dados de treinamento. Isso equivale a minimizar o Limite inferior variacional (VLB) na probabilidade logarítmica negativa. Embora seja chamado de limite inferior, é tecnicamente um limite superior, o negativo do Limite inferior de evidências (ELBO). No entanto, seguimos a literatura de referência para obter consistência em diferentes fontes. Na prática, maximizar a probabilidade se traduz em minimizar a probabilidade logarítmica negativa
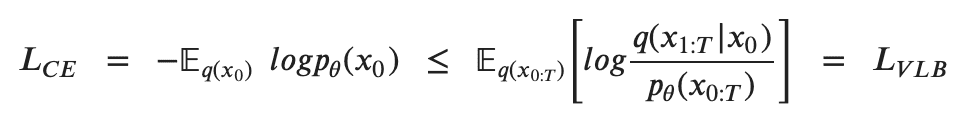
A desigualdade de Jensen para minimizar a entropia cruzada como objetivo de aprendizagem [6]
Para converter cada termo na equação para ser analiticamente computável, o objetivo pode ser reescrito posteriormente para ser uma combinação de vários Divergência KL e termos de entropia [12]. Além disso, para analisar uma formulação passo a passo mais detalhada, visite O blog de Lilian Weng[6] em modelos de difusão.
Reformulação com KL Divergence
A divergência KL mede a distância estatística assimétrica entre distribuições de probabilidade, quantificando o quanto uma distribuição P difere de uma distribuição de referência Q. Formular o VLB em termos de divergências KL é desejável, pois as distribuições de transição na cadeia de Markov são gaussianas e a divergência KL entre gaussianas tem uma forma fechada. A representação matemática da divergência KL para distribuições contínuas é:
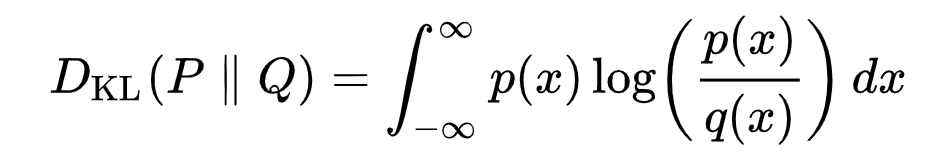
Formulação de divergência KL [13]
Mas como isso se parece na prática? Fornecemos um exemplo de gráfico ilustrando a divergência KL de uma distribuição variável P (distribuição azul) de uma distribuição de referência Q (distribuição vermelha). A curva verde representa a função dentro da integral na definição da divergência KL, e a área total sob a curva representa o valor da divergência KL de P desde Q em um momento específico, exibido numericamente.

KL Representação de divergência para duas distribuições dadas: Q (distribuição de referência) e P (distribuição variável) [13]
A Divergência KL compara as distribuições gaussianas no pipeline de treinamento de difusão: a distribuição de referência da difusão direta com o ruído gaussiano adicionado e o ruído previsto durante a difusão reversa.
Não vamos nos aprofundar na matemática dos modelos de difusão. No entanto, esperamos que isso ajude como uma visão geral de como esses modelos calculam perdas e atualizam seus parâmetros. O modelo prevê ruído em um intervalo de tempo específico t, usando desvio padrão fixo e média real da difusão direta, juntamente com média e desvio padrão do ruído adicionado. Calculamos a divergência KL das imagens nessas distribuições. Essa computação abrange todas as imagens em lote, facilitando a retropropagação da rede neural.
Processo de treinamento
Em cada lote do processo de treinamento, as seguintes etapas são executadas:
- Amostragem de um intervalo de tempo aleatório t para cada amostra de treinamento dentro do lote (por exemplo, imagens)
- Adicionar ruído gaussiano usando a fórmula de forma fechada, de acordo com suas etapas de tempo t
- Convertendo os intervalos de tempo em incorporações para alimentar o U-Net ou modelos similares (ou outra família de modelos)
- Usando as imagens com incorporações de ruído e tempo como entrada para prever o ruído presente nas imagens
- Comparando o ruído previsto com o ruído real para calcular a função de perda
- Atualização dos parâmetros do modelo de difusão via retropropagação usando a função de perda
Esse processo se repete em cada época, usando as mesmas imagens. No entanto, diferentes intervalos de tempo geralmente são amostrados para cada imagem em épocas diferentes. Isso permite que o modelo aprenda a reverter o processo de difusão em qualquer etapa do tempo, aprimorando sua adaptabilidade.

Representação das imagens corrompidas em um lote fixo durante diferentes épocas durante o treinamento [14]
Processo de amostragem
Para amostrar novas imagens, a diferença está em que não temos uma imagem de entrada. Amostramos o ruído gaussiano aleatório e definimos quantas etapas de ruído (T) devem ser tomadas para gerar as novas imagens. Em cada etapa, o Modelo de Difusão prevê todo o ruído presente na imagem, tomando como entrada o intervalo de tempo atual. Em seguida, ele remove apenas uma fração desse ruído previsto. Obtemos nosso resultado de geração de imagem após as etapas de inferência T.
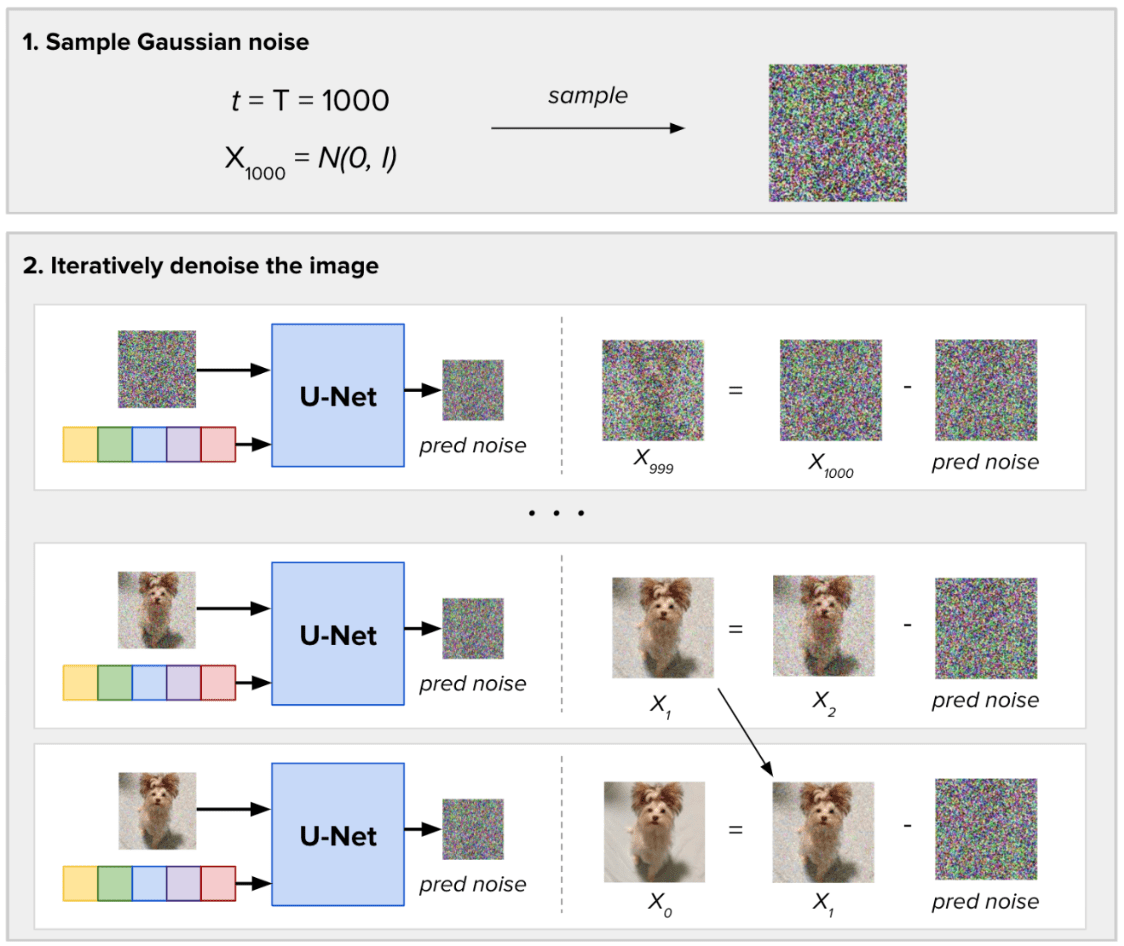
Processo de eliminação de ruído para uma única imagem
Difusão estável
O processo de difusão reversa em modelos de difusão tradicionais envolve a passagem iterativa de uma imagem em tamanho real pela arquitetura U-Net para obter o resultado final sem ruído. No entanto, essa natureza iterativa apresenta desafios em termos de eficiência computacional. Isso é enfatizado ao lidar com tamanhos de imagem grandes e um alto número de etapas de difusão (T). O tempo necessário para eliminar o ruído da imagem do ruído gaussiano durante a amostragem pode se tornar proibitivamente longo. Para resolver esse problema, um grupo de pesquisadores propôs uma nova abordagem chamada Difusão estável, originalmente conhecido como Modelo de difusão latente (LDM) [15]. Exploraremos os principais avanços em relação aos modelos de difusão apresentados neste artigo: trabalhar com imagens no espaço latente e condicionamento.
Modelos de difusão latente
A difusão estável introduz uma modificação importante ao realizar o processo de difusão no espaço latente. Isso funciona usando um treinado Codificador E para codificar uma imagem em tamanho real para uma representação de menor dimensão (espaço latente). Em seguida, fazer o processo de difusão direta e o processo de difusão reversa dentro do espaço latente. Mais tarde, com um treinado Decodificador D, podemos decodificar a imagem de sua representação latente de volta ao espaço em pixels. Para construir o codificador e o decodificador, podemos treinar alguma variante de um Codificador automático variacional (VAE). Essa rede é então desacoplada para usar os dois componentes separadamente.
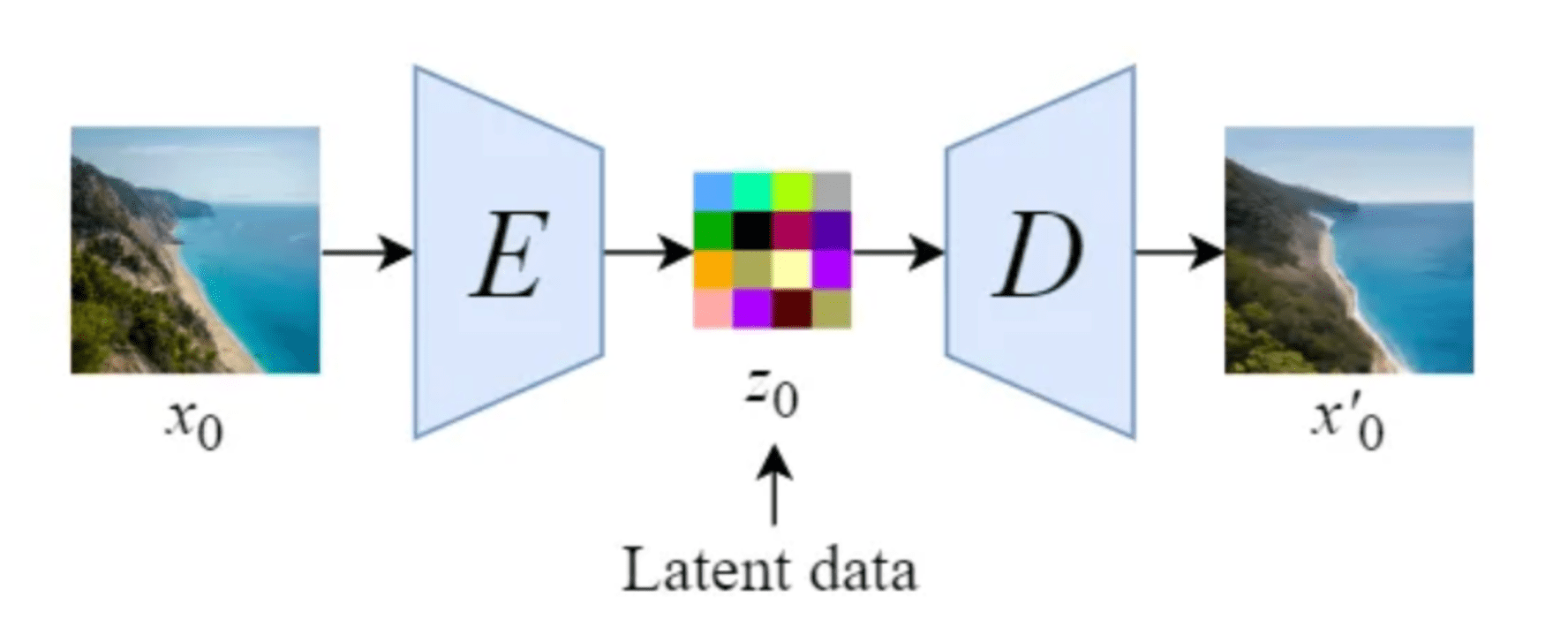
Ilustração de um autoencoder, conforme proposto pelo artigo Stable Diffusion [14]

Ilustração de uma visão geral do modelo de difusão estável no espaço latente [14]
Mudar as operações de difusão para o espaço latente na difusão estável aumenta a velocidade e reduz os custos. Esse avanço acelera os processos de remoção de ruído e amostragem, tornando-o uma solução eficiente para geração de imagens de alta qualidade e treinamento estável. Ao aproveitar o espaço latente, a difusão estável alivia a carga computacional no processo de difusão reversa. Isso permite uma eliminação mais rápida do ruído das imagens, aprimorando a velocidade e a estabilidade e robustez geral do modelo.
Condicionamento
Até então, a geração de imagens de uma classe específica era possível principalmente por meio da adição do rótulo da classe na entrada. Comumente conhecido como Orientação do classificador. No entanto, um dos recursos de destaque do modelo de difusão estável é sua capacidade de gerar imagens com base em solicitações de texto específicas ou outras entradas de condicionamento. Isso é conseguido através da introdução de mecanismos de condicionamento no modelo de difusão interna, também visto na literatura como Orientação sem classificadores (CFG) [16]. Para permitir o condicionamento, a U-Net de eliminação de ruído do modelo de difusão interna faz uso de um mecanismo de atenção cruzada. Isso permite que o modelo incorpore efetivamente as informações de condicionamento durante o processo de geração da imagem (eliminação de ruído). As entradas de condicionamento podem assumir várias formas, dependendo da saída desejada:
- As entradas de texto são primeiro transformadas em incorporações por meio de modelos de linguagem como BERT ou CLIP. No condicionamento, mapeamos essas incorporações na U-Net usando uma camada de atenção com várias cabeças, representada como Q, K e V no diagrama.
- Outras entradas condicionantes, como dados alinhados espacialmente, como mapas semânticos, imagens ou embutidos, agem de forma semelhante. No entanto, a integração desses mecanismos de condicionamento geralmente é alcançada por meio da concatenação.
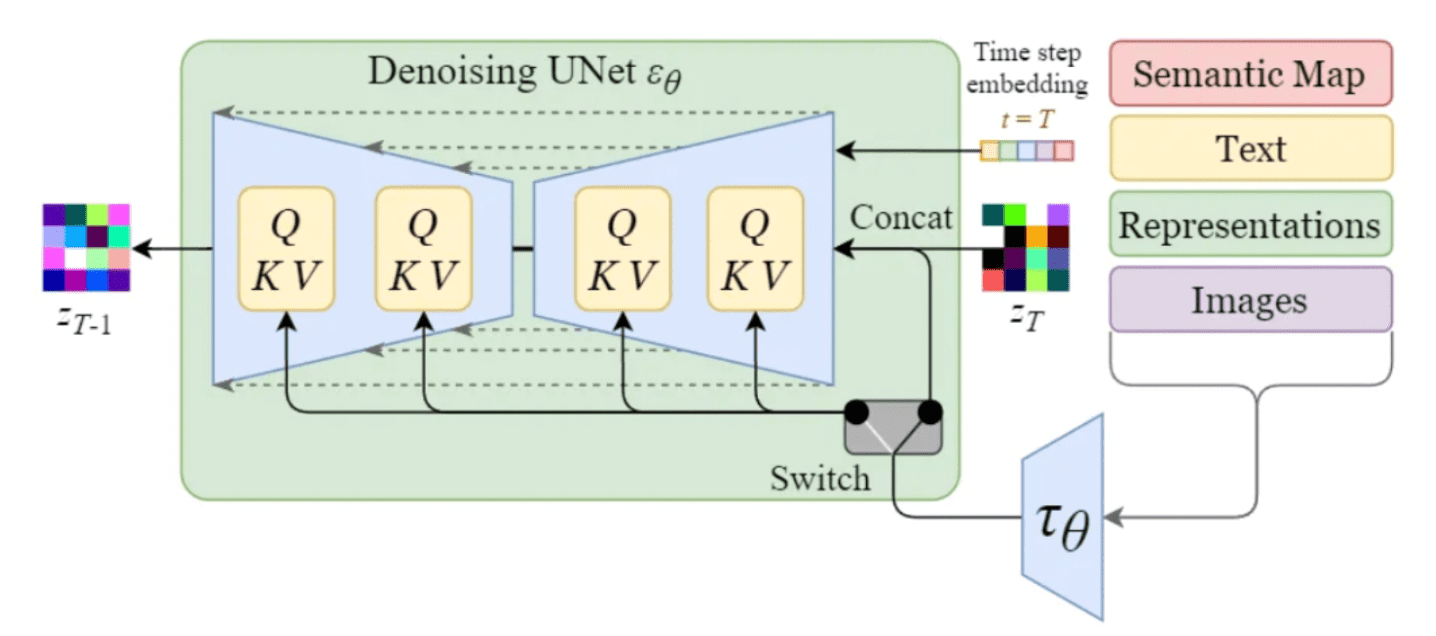
Mecanismo de condicionamento dentro da U-Net da Stable Diffusion [14]
Ao incorporar mecanismos de condicionamento, o modelo de difusão estável expande suas capacidades para gerar imagens com base em entradas adicionais específicas. Solicitações de texto, mapas semânticos ou imagens adicionais permitem uma síntese de imagens mais versátil e controlada. Usando engenharia rápida, é possível criar imagens ainda mais atraentes. Se você estiver interessado nas melhores práticas para aplicar a engenharia rápida tanto para modelos de linguagem grande quanto para difusão estável, confira nosso blog sobre engenharia rápida.
Arquitetura
Em nossa jornada pelos modelos de difusão latente e pelo poder do condicionamento, podemos notar um avanço notável no mundo da geração de imagens. Agora, é hora de dar uma olhada em como é todo o processo da Difusão Estável. Por um lado, durante formação, as imagens (x)0) são codificados por meio do Codificador E, alcançando a representação latente da imagem (z0). No processo de difusão direta, a imagem sofre a adição de ruído gaussiano, obtendo uma imagem ruidosa (zT). A imagem então passou pela U-Net, a fim de prever o ruído presente em zT. Essa comparação entre o ruído real adicionado na difusão direta e a previsão permite o cálculo da perda mencionada anteriormente. Com a perda calculada, atualizamos os parâmetros da U-Net por meio da retropropagação.
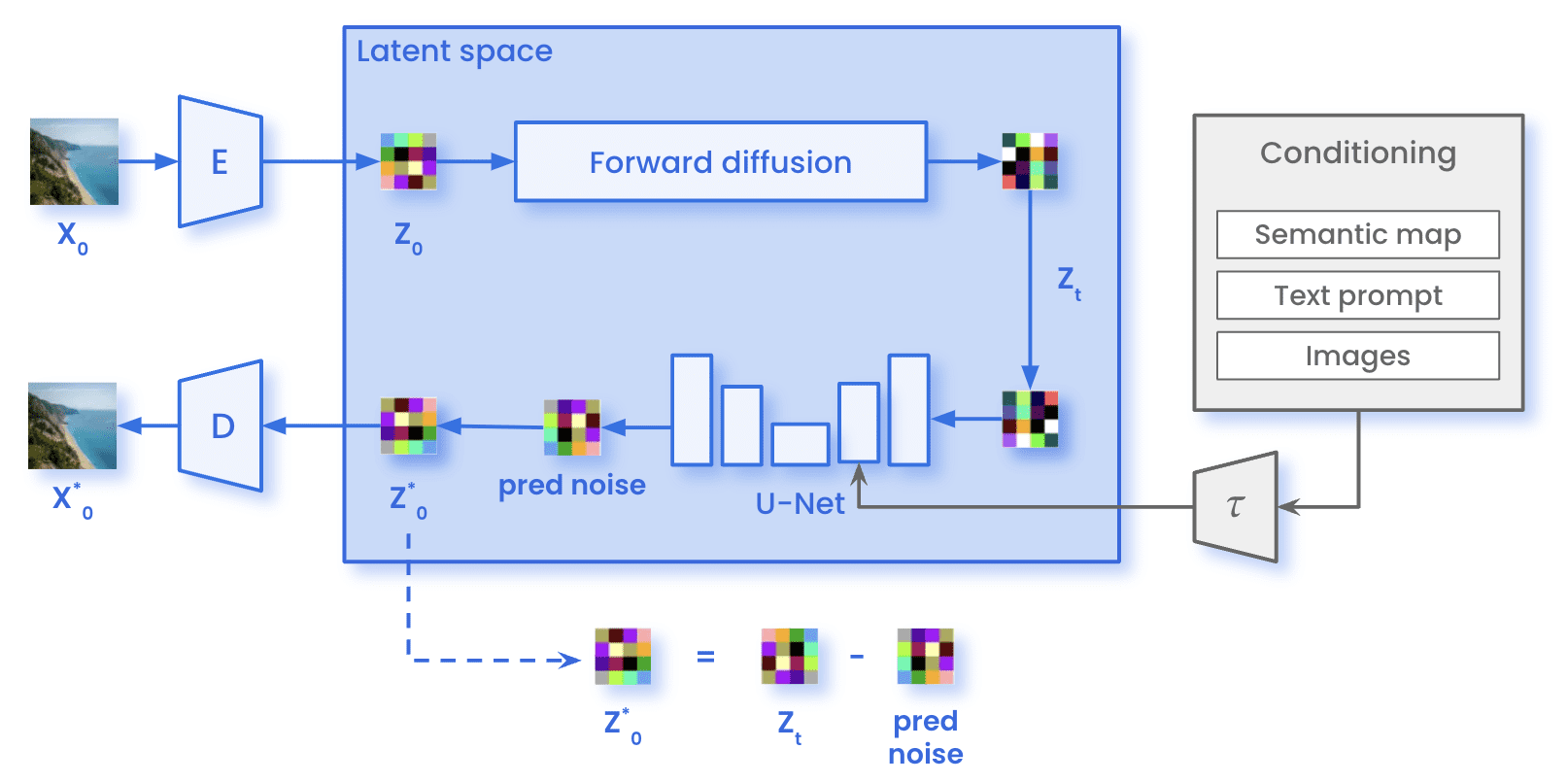
Arquitetura de difusão estável durante o treinamento
Por outro lado, o processo de difusão direta não ocorre durante a amostragem. Acabamos de amostrar o ruído gaussiano com as mesmas dimensões presentes no espaço latente (zT). Esse ruído passa pela U-Net pelo número especificado de etapas de inferência T. Em cada etapa t, o U-Net prevê todo o ruído presente na imagem. O modelo remove apenas uma fração do ruído previsto para obter a representação da imagem em um intervalo de tempo t-1. Depois que todas as etapas de inferência T são iterativas, obtemos a representação dentro do espaço latente da imagem gerada (0). Usando o Decodificador D, podemos então transformar essa imagem do espaço latente para o espaço em pixels (X̂0).
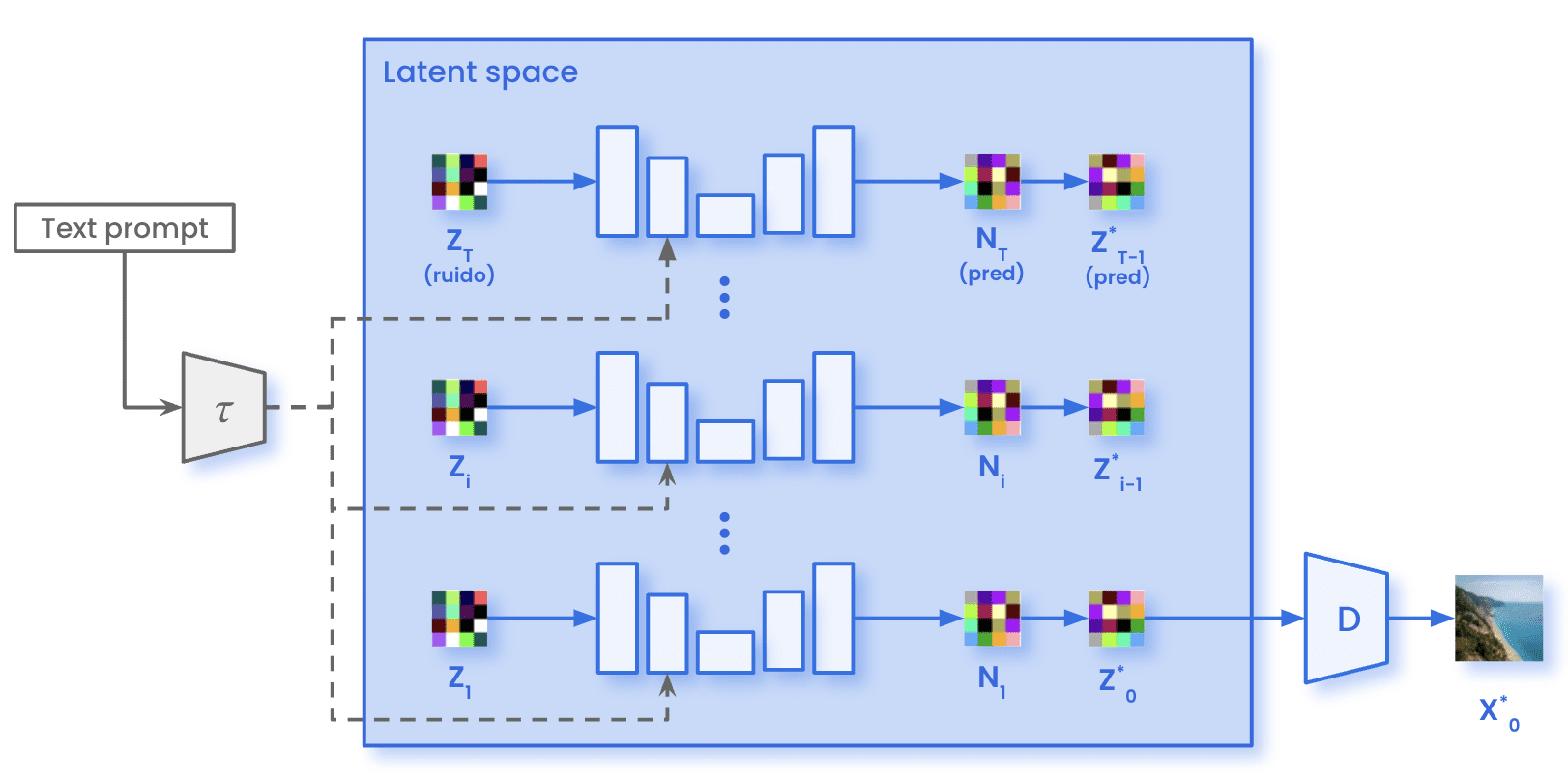
Arquitetura de difusão estável durante a amostragem
Casos de uso
Os modelos de difusão oferecem soluções versáteis para resolver vários problemas. Alguns dos casos de uso mais comuns em que os modelos de difusão se destacam são:
- Geração de imagem por meio de solicitação: gere imagens com base em solicitações textuais ou entradas de condicionamento, permitindo uma síntese de imagens controlada e personalizável.
- Superresolução de imagem: melhore a resolução e a qualidade das imagens de baixa resolução, gerando versões de alta resolução com detalhes e nitidez aprimorados.
- Adaptação de domínio e transferência de estilo: transferir o estilo ou as características de uma imagem ou domínio para outro, permitindo a adaptação de modelos treinados em um domínio de origem para um bom desempenho em um domínio alvo com diferentes características visuais.
- Imagem na pintura: preencha partes ausentes ou corrompidas de uma imagem, reconstruindo os detalhes que faltam para criar imagens visualmente completas e coerentes.
- Pintura de imagem: expanda a imagem para fora de suas fronteiras criando continuidade e gerando uma imagem maior.

A primeira imagem é um exemplo do que é possível fazer com o Midjourney, tirada da seção superior de sua página da web. A segunda imagem mostra um exemplo de pintura embutida para substituir o cachorro (via pintura embutida) por um gato (via solicitação) [15].
Principais conclusões
Em resumo, aqui estão as principais conclusões que queremos que você aprenda ao ler este artigo:
- Os modelos de difusão consistem em dois processos: difusão direta e difusão reversa.
- O processo de difusão direta consiste em adicionar iterativamente ruído gaussiano. Ao usar a fórmula de formato fechado em apenas uma etapa, eliminamos a necessidade de iteração. Isso permite uma geração mais rápida das imagens corrompidas.
- O processo de difusão reversa envolve a utilização de uma rede neural para aproximar o processo de eliminação de ruído. Esse processo é iterativo, passo a passo, até recuperar a imagem original.
- Modelos de difusão latente (LDMs) melhoram a eficiência da geração de imagens com base em difusão ao realizar o processo de difusão no espaço latente. Essa abordagem acelera significativamente o processo de geração, especialmente para imagens grandes e etapas de difusão mais longas.
- Alguns modelos de difusão oferecem a possibilidade de orientar a geração usando entradas adicionais. Textos e imagens são algumas das entradas orientadoras comuns.
- Os modelos de difusão encontraram aplicações em vários casos de uso. Algumas delas incluem: geração de imagem por meio de solicitação, pintura embutida na imagem, adaptação de domínio/transferência de estilo e superresolução de imagem. Esses modelos oferecem soluções versáteis para tarefas que vão desde a síntese criativa de imagens até o aprimoramento e a restauração de imagens.
Em conclusão, os modelos de difusão se tornaram um novo paradigma eficaz para geração e manipulação de imagens. Ao combinar os princípios dos processos de difusão com técnicas de aprendizado profundo, esses modelos oferecem novos caminhos para gerar imagens de alta qualidade. Esperamos que este blog sirva para obter uma compreensão mais profunda de como os modelos de difusão funcionam. E fique surpreso com mais conteúdo relacionado em futuros blogs!
Referências
- Redes adversárias generativas Goodfellow et al. (2014)
- Modelos probabilísticos de difusão de redução de ruído (DDPM), Ho et al. (2020)
- Modelos de difusão superam GANs na síntese de imagens, Dhariwal e Nichol (2021)
- Modelos probabilísticos de difusão de redução de ruído aprimorados, Nichol e Dhariwal (2021)
- Síntese de imagens de alta resolução com modelos de difusão latente, Rombach et al. (2022)
- Orientação de difusão sem classificadores, Ho e Salimans (2022)
- Introdução aos modelos de difusão para aprendizado de máquina, AssemblyAI (2022)
- A difusão estável ilustrada, Jay Alammar (2022)
- Modelo de difusão claramente explicado!, Steins (2022)
- Difusão estável claramente explicada!, Steins (2023)
- Uma imagem gerada pela IA ganhou um prêmio de arte. Artistas não estão felizes, Kevin Roose (2022)
- Como funcionam os modelos de difusão: a matemática do zero, Karagiannakos e Adaloglouon (2022)
- O que são modelos de difusão?, Lilian Weng (2022)



.png)