.png)
Cuando la electrónica se une al aprendizaje automático




En este post intentamos resumir la experiencia de trabajar en un proyecto que combina procesamiento de señales, aprendizaje automático y electrónica. Su objetivo era desarrollar un dispositivo manipulable integrado en un sensor a partir del cual inferir el tipo de movimiento o actividad realizado por su usuario. Por inferencia nos referimos a la clasificación de la actividad basada en un conjunto de clases conocidas y predefinidas. Estos tres campos mencionados han generado interés de forma individual durante décadas, y cada uno de ellos presenta una variedad de desafíos característicos de su naturaleza. Por lo tanto, nuestro objetivo es dar a nuestros lectores una idea de los principales desafíos a los que nos enfrentamos al abordar el proyecto.
Comprensión de la electrónica

La pieza central del dispositivo es una unidad de medición inercial (IMU) que contiene un acelerómetro y un giroscopio. La primera mide la aceleración del dispositivo y la segunda la velocidad angular (ambas en tres ejes). Aunque no diseñamos el hardware para este proyecto, nos aseguramos de poder recibir e interpretar las mediciones formateadas según un protocolo de comunicación. Para ello, transmitimos los datos a través de BLE (Bluetooth Low Energy) a un PC que almacena la información recopilada del dispositivo. En primer lugar, necesitábamos interactuar con el dispositivo para recopilar los datos y procesarlos de forma coherente. Por ejemplo, es necesario tener en cuenta un cambio en la frecuencia de muestreo para garantizar la compatibilidad. Cuando se trabaja con ángulos formateados en 16 bits, se requiere un paso posterior de desempaquetado. Conocer las especificaciones del hardware es crucial para definir qué tipo de técnicas de procesamiento aplicar.
Procesamiento de señales
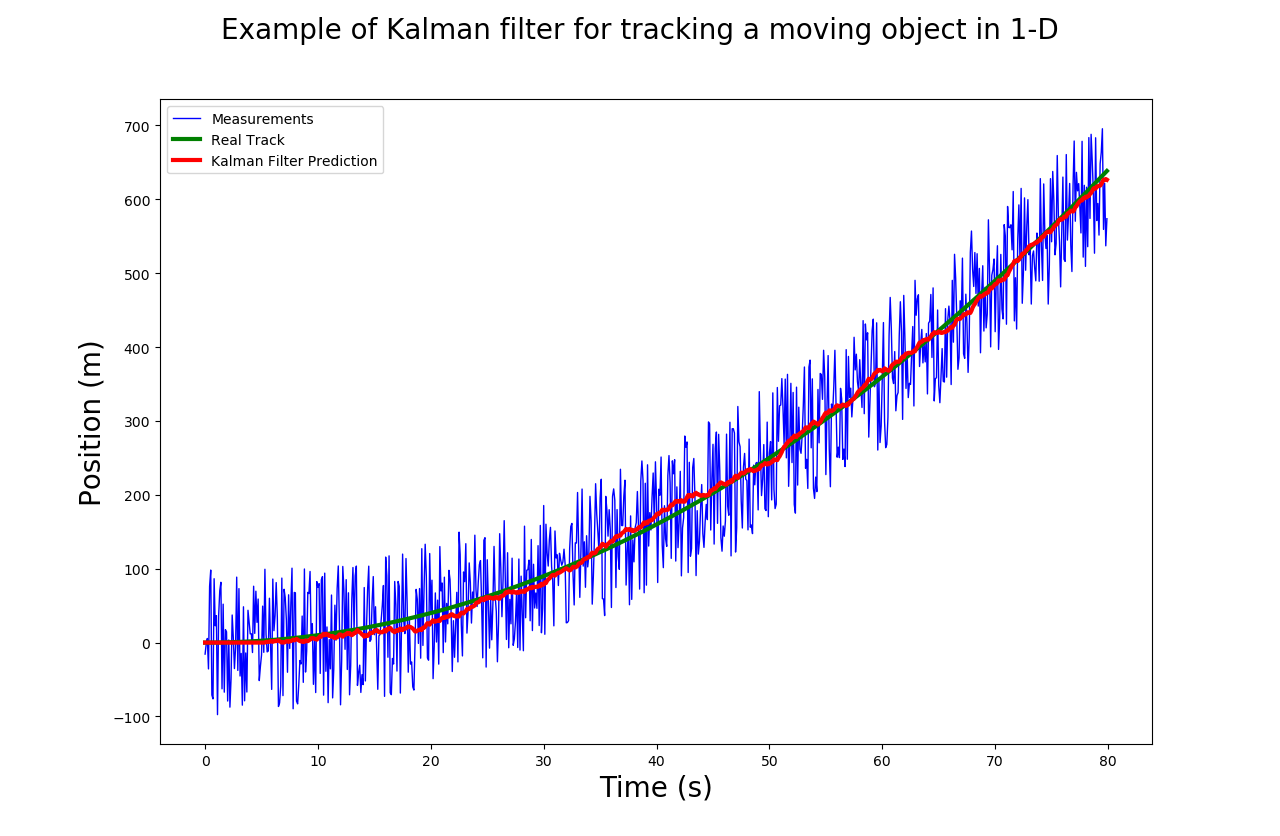
Dado que los datos no son información en sí mismos, las mediciones sin procesar ayudan poco a resolver el problema sin un procesamiento posterior. Por lo tanto, el procesamiento de señales viene a traducir estas mediciones sin procesar en información valiosa. Analizamos el rango de datos, la periodicidad y el impacto del ruido, y aplicamos filtros de paso de banda y de Kalman para suavizar la señal. Cuando se trabaja con datos multivariantes, la transformación de dimensionalidad puede resultar útil: las mediciones triaxiales pueden transformarse en medidas unidimensionales (como una magnitud) o proyectarse en espacios de mayor interés (por ejemplo, cuaterniones, PCA). La observación de diferentes representaciones de datos nos lleva a comprender mejor la realidad. Por ejemplo, cuando la aceleración medida es constante y su magnitud es igual a la gravedad, significa que el dispositivo se deja en una posición inmóvil.
Aprendizaje automático
Un modelo de aprendizaje automático exitoso requiere datos de buena calidad. Esto significa buscar un conjunto de datos disponible públicamente o crear uno personalizado. Elegimos la segunda opción, ya que los datos deben representar con precisión el resultado de la IMU. Para crear el conjunto de datos, debemos definir de qué actividades (o clases) tomar muestras, obtener los datos y etiquetarlos correctamente. También es importante saber si se necesita algún tipo de segmentación, si el inicio y el final de la actividad están definidos o si necesitamos reconocerlos a partir de los datos. Si queremos que el modelo se generalice, debemos alimentarlo con las variaciones más relevantes. En nuestro caso, realizar las actividades por diferentes personas, en días diferentes. La creación de un conjunto de datos puede llevar mucho tiempo y se puede hacer de forma gradual: empezando con unas cuantas clases y, al mismo tiempo, avanzando en el análisis exploratorio de datos y la evaluación comparativa de modelos. Sabemos que este proceso es largo y tedioso, por lo que es imprescindible realizarlo en paralelo con otras tareas. Con el conjunto de datos en la mano, es hora de empezar con la ingeniería de funciones. ¿Son suficientes los datos sin procesar? ¿Todas las clases están representadas con las mismas características? ¿Sería útil crear nuevas características proyectando las existentes en otro espacio? ¿Y agregarlas? Además, ¿cómo recibiremos los datos en el momento de la inferencia? Si tenemos que procesar los datos en tiempo real, quizás sea mejor usar un algoritmo de ventana deslizante, pero si necesitamos procesar todos los datos al mismo tiempo, tal vez sea mejor introducir todos los datos en su conjunto. A continuación, comenzamos la parte de modelización. Como siempre, partimos de los modelos más simples, como los SVM, y pasamos a los más complejos, como los LSTM y los CNN. Este último, por ejemplo, es un modelo común de visión artificial, pero se puede adaptar a los datos de series temporales mediante la circunvolución en una sola dimensión. La mejor solución que se ofrece a menudo requiere pensar de manera innovadora. Por último, necesitamos una forma de medir la calidad de nuestro modelo. Aquí es donde entran en juego las métricas. Elegir la métrica correcta para su modelo y sus datos es crucial para evaluar el rendimiento del proyecto. Si sabes que los datos están sesgados hacia ciertas clases, por ejemplo, es posible que una métrica de precisión no refleje el rendimiento del modelo, por lo que se necesita otra métrica, como la puntuación F1.
Resumiendo
En el recorrido de este proyecto tan innovador, pusimos a prueba nuestra capacidad para incorporar diferentes disciplinas en el desarrollo. Afrontamos con éxito los desafíos que descubrimos en cada una de las áreas mencionadas. Es importante hacer una investigación inicial exhaustiva y refinarla de forma iterativa más adelante, cuando se tenga una comprensión más profunda del proyecto. De esta forma, no te puedes perder ninguna técnica de última generación. Como en todos los proyectos, las opciones más prometedoras suelen ser más arriesgadas, y los enfoques más clásicos y seguros suelen ser más limitados. Finalmente, llegamos a una comprensión práctica del proyecto y de las diferentes áreas que influyen en él: la definición, el análisis, la experimentación, el desarrollo (y la redefinición).



.png)