.png)
Del profesor al alumno: destilación de modelos para una implementación rentable de LLM




No sorprende que los modelos de IA estén creciendo, con un aumento en los datos de entrenamiento y la cantidad de parámetros. Por ejemplo, mientras que el GPT-3.5 de OpenAI se entrenó con 175 mil millones de parámetros y más de 570 GB de datos de diversas fuentes, el GPT-4 probablemente se entrenó con cerca de 1 billón de parámetros y terabytes de datos.
Por muy bueno que parezca, tener modelos tan grandes puede ser un desafío para las aplicaciones del mundo real, donde la implementación es extremadamente difícil debido a los requisitos y costos computacionales intensivos (especialmente en los dispositivos periféricos). También puede resultar exagerado... A veces, el rendimiento no compensa el coste y la latencia.
Aquí es donde Modelo de destilación es muy útil. En este blog, exploraremos qué es la destilación modelo, cómo se hace y cómo se usa en diferentes escenarios.
¿Qué es la destilación modelo?
También conocida como destilación del conocimiento, es una técnica en la que se utiliza un modelo de profesor de mayor capacidad y mejor calidad para capacitar a un modelo de estudiante más compacto con una mejor eficiencia de inferencia.1
Principalmente, implica transferencia de conocimientos de un modelo grande y complejo a uno más pequeño y eficiente. Esto permite lograr niveles similares de precisión y rendimiento y, al mismo tiempo, es menos exigente desde el punto de vista computacional, lo que lo hace apropiado para su implementación en dispositivos con recursos limitados.
El paradigma profesor-alumno
Entonces, ¿qué pasa con la relación profesor-alumno? Como habrás adivinado, llamaremos al modelo preentrenado el profesor, como un LLM, del que se extraerá el conocimiento. El estudiante modelo será el que aprenderá las cualidades y los comportamientos del modelo docente. A través de la destilación, se espera sacar provecho de la compacidad del estudiante, sin sacrificar demasiado la calidad del modelo.2
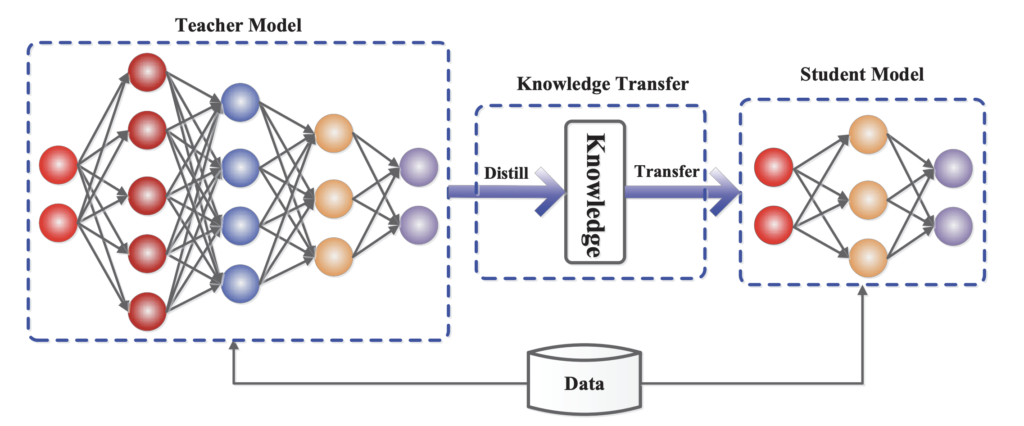
La figura 1 muestra un marco general entre profesores y alumnos para la destilación modelo. Ilustra cómo el modelo del profesor, que es una red neuronal compleja y previamente entrenada, transfiere el conocimiento adquirido a un modelo estudiantil más compacto a través de este proceso que llamamos destilación. Esto implica utilizar un conjunto de datos compartido para extraer los conocimientos esenciales del modelo docente, que luego se transfieren al modelo estudiantil.
Vale... pero ¿cómo?
Entiendes el concepto. Ahora: ¿cómo lo hacemos realmente transferir conocimiento? A pesar de que se han propuesto muchos métodos de destilación, no existe una teoría comúnmente aceptada sobre cómo se transfiere el conocimiento, lo que hace que esta entrada de blog sea un poco más difícil.
Analicemos algunos de ellos.
Destilación de modelos basada en respuestas
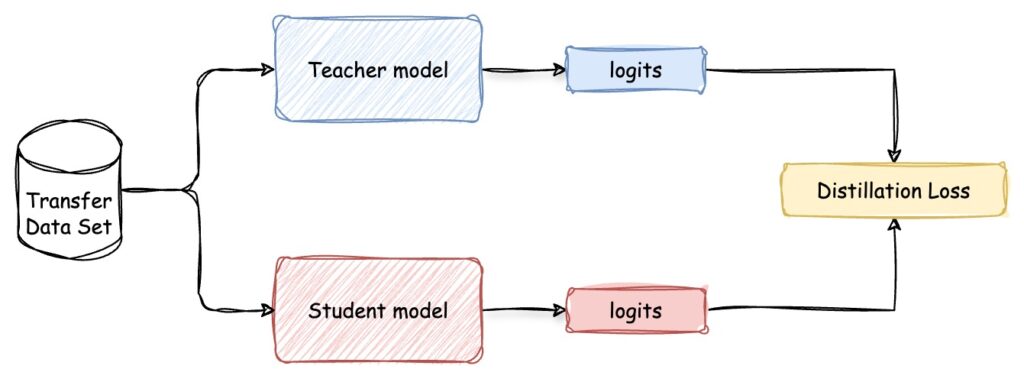
Este es el tipo de modelo de destilación más común y fácil de implementar que se basa en el resultados del modelo docente. En lugar de hacer predicciones primarias, el modelo del estudiante está entrenado para imitar la predicción del modelo del maestro. Implica un proceso de dos pasos, que se muestra en la figura 2:
- En primer lugar, la formación del modelo docente. O, como mencionamos, también puedes usar un modelo previamente entrenado para convertirlo en uno más pequeño.
- En segundo lugar, pídele que genere «objetivos fáciles». UN algoritmo de destilación luego se aplica para entrenar al modelo del estudiante a predecir las mismas etiquetas flexibles que el modelo del profesor y minimizar las diferencias en sus resultados (también conocidas como Pérdida por destilación, pero volveremos a ello más adelante). Esto implica aprender de los resultados del modelo docente y no directamente de los datos de formación. De este modo, el modelo estudiantil puede lograr niveles similares de precisión y, al mismo tiempo, ser más eficiente en términos de potencia computacional y uso de memoria.
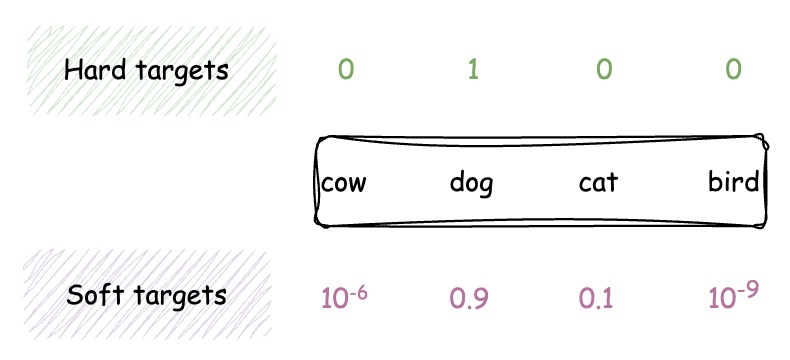
Este es un aspecto crucial de la destilación modelo: el uso de objetivos fáciles. A diferencia de los métodos de entrenamiento tradicionales que utilizan objetivos difíciles (etiquetas de clase codificadas de una sola vez), la destilación modelo emplea objetivos flexibles, que son distribuciones de probabilidad en todas las clases posibles.
Imagina que estás entrenando a un modelo para clasificar imágenes de animales en cuatro categorías: vaca, perro, gato y pájaro. En el entrenamiento tradicional con objetivos difíciles, las etiquetas de cada imagen se codifican de una sola vez. Para una imagen de un perro, la etiqueta sería ([0, 1, 0, 0]).
Sin embargo, cuando se entrena con objetivos flexibles, el modelo del profesor proporciona una distribución de probabilidad en todas las clases. En el caso de una imagen de un perro, los objetivos más fáciles podrían ser ([10]-6, 0.9, 0.1, 10-9]), lo que refleja la confianza del modelo docente en cada clase.
Estos objetivos flexibles proporcionan información más sutil sobre las relaciones entre las diferentes clases, lo que permite que el modelo estudiantil aprenda de manera más efectiva.
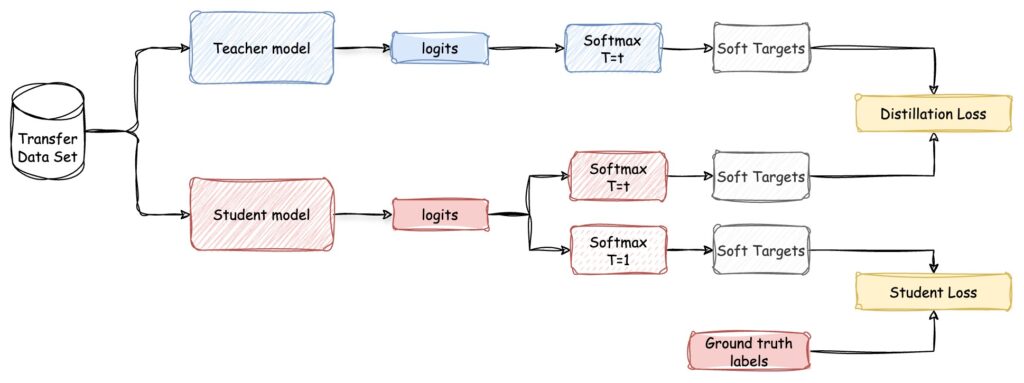
Cada probabilidad se puede estimar mediante función softmax eso depende de un factor de temperatura T para controlar el blandura de cada objetivo. La temperatura se aplica a los logits del modelo docente antes de convertirlos en probabilidades. Una temperatura más alta produce una distribución de probabilidad más suave, mientras que una temperatura más baja la hace más nítida.
Luego, el modelo estudiantil es entrenado para minimizar la diferencia entre sus predicciones y las del modelo docente. Es decir, minimizar la Función de pérdida, que normalmente combina dos componentes:
- El ya mencionado Pérdida por destilación: definido como la diferencia entre los objetivos flexibles producidos por el modelo docente y las predicciones del modelo estudiantil, ambos calculados con el mismo factor de temperatura. A menudo se calcula utilizando el Divergencia Kullback-Leibler o entropía cruzada.
En el ejemplo anterior, la pérdida de destilación entre «perro» y «gato» sería menor que la pérdida entre «perro» y «pájaro», ya que el modelo del profesor asigna una probabilidad más alta a «gato» (0,1) en comparación con «pájaro» (10)-9). - Pérdida de estudiantes: definida como la pérdida estándar de entropía cruzada entre la etiqueta de verdad básica y los registros flexibles del modelo estudiantil.
Vamos a completar el diagrama de arriba para tener una imagen completa:
Suena bien, ¿verdad?
Destilación de modelos basada en características
El método basado en respuestas es útil cuando se necesita un método de destilación sencillo y rápido. Solo se basa en la salida de la última capa. Pero cuando la tarea lo requiere capturar patrones y relaciones complejos, como la detección o segmentación de objetos, Destilación de modelos basada en características es tu opción.
En la destilación del modelo basado en características, tanto la salida de la última capa como la salida de las capas intermedias se puede usar como pistas para mejorar la formación del modelo de estudiante, haciendo coincidir directamente las activaciones de funciones del profesor y del alumno. Decimos pistas pero en realidad queremos decir que el resultado de la capa oculta de un profesor supervisa el aprendizaje del alumno.
Este método está diseñado para transferir conocimientos incluso cuando los modelos de profesor y alumno tienen arquitecturas, profundidades o recuentos de capas diferentes. La idea central es alinear las representaciones internas (características) aprendidas por el profesor con las del alumno, siempre y cuando ciertas estrategias aborden las diferencias arquitectónicas.
En resumen, el conjunto de datos de transferencia se utiliza para extraer representaciones de características tanto del modelo del profesor como del del alumno. El Pérdida por destilación ahora se calculará en función de la diferencia entre estas representaciones de características para entrenar el modelo del estudiante.
Nuestro nuevo diagrama tendrá el siguiente aspecto:

Destilación de modelos basada en relaciones
Por último, pero no por ello menos importante, Destilación basada en modelos relacionales se centra en explorar el relaciones entre diferentes capas, tanto en el modelo docente como en el modelo estudiantil. Resulta útil en tareas en las que es crucial comprender las relaciones entre los puntos de datos, como los sistemas de recomendación o los modelos basados en gráficos.
El Relaciones de instancia se calculan utilizando los productos internos entre las características de dos capas. Estos capturan las similitudes o interacciones por pares entre los puntos de datos, lo que proporciona una representación más rica de la estructura subyacente de los datos. De esta manera, el modelo del estudiante puede imitar mejor el desempeño del modelo del maestro.
Por último, el Pérdida por destilación se calculará en función de la diferencia entre estas representaciones relacionales para entrenar el modelo del estudiante.

Figura 5: Proceso de destilación basado en relaciones, en el que se utiliza un conjunto de datos de transferencia para capturar información relacional entre instancias tanto del modelo de profesor como del modelo de estudiante. La pérdida por destilación se calcula en función de la diferencia entre estas representaciones relacionales para entrenar el modelo estudiantil.
Aplicaciones de la destilación modelo
Así que ahí está la base teórica del modelo de destilación. Para ilustrar su impacto práctico, destaquemos algunas aplicaciones existentes.
PNL
Como mencionamos anteriormente, la aplicación de modelos de destilación para aplicaciones de PNL es especialmente importante dada la amplia adopción de modelos de gran capacidad como los LLM. Esto significa que podríamos crear un LLM ligero, que conserva gran parte de la precisión y la capacidad del LLM original, pero es más adecuado para su implementación en entornos con recursos limitados.
⚠️ Permíteme añadir un descargo de responsabilidad aquí:
Podríamos crear un modelo más pequeño de uso general que encapsula por completo todo el conocimiento de un LLM, pero normalmente hay una compensación entre el tamaño del modelo destilado y su rendimiento. Los LLM logran su rendimiento gracias a su capacidad para capturar una enorme cantidad de conocimientos, representaciones y patrones lingüísticos a partir de datos de entrenamiento exhaustivos. Comprimir todo este conocimiento en un modelo significativamente más pequeño a menudo conduce a un rendimiento inferior.
Por lo tanto, parece más adecuado usar la destilación de modelos para modelos de tareas específicas, donde el objetivo es optimizar el modelo del estudiante para una tarea específica o un conjunto de tareas. Al centrarse en determinados resultados o comportamientos del modelo docente relacionados con la tarea, el alumno puede lograr un rendimiento similar o incluso superior al del profesor en esa tarea.
Computación perimetral
La destilación de modelos desempeña un papel vital a la hora de permitir que los modelos de IA se ejecuten en dispositivos periféricos, como teléfonos inteligentes, dispositivos de IoT y sistemas integrados. Al reducir el tamaño del modelo y los requisitos computacionales, es posible implementar capacidades sofisticadas de inteligencia artificial directamente en estos dispositivos, mejorar la privacidad, reducir la latencia y habilitar la funcionalidad sin conexión. Si tiene curiosidad y quiere obtener más información, consulte este increíble blog.
Por ejemplo, la mayoría de los métodos de destilación modelo se desarrollaron para clasificación de imágenes, y luego se extendió a otras aplicaciones de reconocimiento visual como:
- reconocimiento facial,
- segmentación de imagen/vídeo,
- detección de objetos,
- detección de carril,
- estimación de postura,
- respuesta visual a las preguntas, y
- detección de anomalías.
Compresión de conjuntos
Por último, la destilación de modelos se puede utilizar para comprimir un conjunto de modelos en un modelo único y más eficiente que se aproxime al rendimiento del conjunto. Esta técnica, a veces denominada «destilación conjunta» permite el despliegue de un rendimiento a nivel de conjunto con el coste computacional de un solo modelo.
Figura 6: Proceso de destilación para la compresión de conjuntos de modelos.
¿Qué es lo siguiente?
Si ha leído hasta este punto, es de esperar que haya aprendido qué es la destilación modelo, cómo se hace y tal vez incluso haya imaginado diferentes escenarios en los que podría ser beneficiosa.
En definitiva, la destilación modelo no solo abre la posibilidad de implementar LLM de forma rentable, pero también aborda un desafío crítico en entornos con recursos limitados. Al crear modelos más pequeños y específicos para cada tarea, es posible la implementación en dispositivos periféricos. Este enfoque minimiza las demandas computacionales y, al mismo tiempo, mantiene el rendimiento, lo que lo hace ideal para una amplia variedad de escenarios.
Si está interesado en adquirir experiencia práctica con la destilación de modelos, hay varias herramientas y plataformas disponibles para ayudarlo a comenzar:
- API de OpenAI proporciona una interfaz flexible para experimentar con diversas técnicas de destilación,
- Azure y AWS también ofrecen servicios integrales de aprendizaje automático que pueden facilitar la implementación de la destilación de modelos en aplicaciones del mundo real.



.png)