.png)
Fusão de modelos: combinando diferentes LLMs ajustados




Fusão de modelos
1. Introdução
A composição do modelo é um problema bem conhecido na comunidade de aprendizado de máquina. Seu objetivo é ampliar as capacidades de um modelo, sem esquecer o que ele já sabe. Vamos considerar uma situação em que temos um modelo com bom desempenho em uma determinada tarefa (por exemplo, texto para SQL), mas ele foi ajustado para essa tarefa específica, perdendo parte de sua capacidade de realizar outras tarefas, como resumo ou tradução. Há muitas técnicas para adicionar novas habilidades a um modelo, como ajuste fino, aprendizado ativo, modelos de conjunto e sopas modelo. No entanto, isso se torna especialmente importante no contexto atual de IA devido ao impacto dessas técnicas aplicadas a modelos de linguagem grande (LLMs). É aí que a fusão de modelos entra em jogo. Algumas das abordagens mais relevantes quando se fala em LLMs são: mistura de especialistas (MoE), fusão de modelos e expansão de blocos. Analisaremos algumas noções básicas das três e nos aprofundaremos na fusão de modelos, mas em alto nível:
- Mistura de especialistas (MoE): consiste em usar vários modelos (chamados peritos) e treinando uma rede de portões (geralmente chamada roteador) que seleciona os especialistas mais adequados para responder a uma pergunta ou concluir uma instrução.
- Fusão de modelos: é um processo em que, geralmente, os pesos de diferentes modelos com a mesma arquitetura (que também podem ser chamados peritos) passam por uma operação de fusão (por exemplo, interpolação) para criar um novo modelo único. No entanto, algumas mesclagens podem envolver o empilhamento de camadas de modelos diferentes sem alterar seus pesos.
- Expansão de blocos: consiste em adicionar blocos de transformações ajustados em novos dados para ampliar as capacidades do modelo.
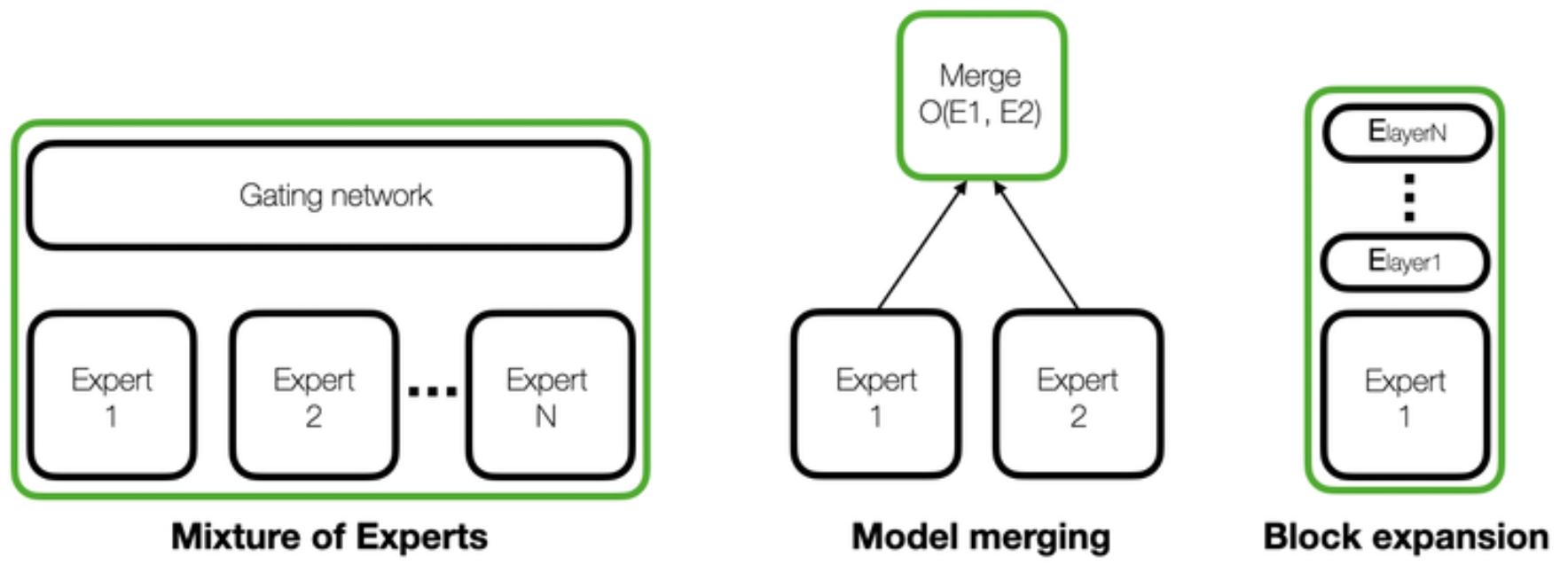
Esquema de três métodos populares para expandir as habilidades dos LLMs. O modelo resultante é mostrado dentro de uma caixa verde [1].
1.1 Mistura de especialistas
Essa arquitetura foi apresentada em Papel Switch Transformers [2]. No entanto, recentemente ganhou muita atenção devido a dois eventos principais. Em primeiro lugar, houve alguns comentários de pessoas confiáveis da comunidade de IA, como George Hotz, alegando que o GPT-4 era um modelo MoE de oito vias com cerca de 220B de parâmetros. Além disso, o lançamento do Mixtral [3] ganhou muita atenção, tornando-se um dos LLMs não proprietários mais populares da comunidade.
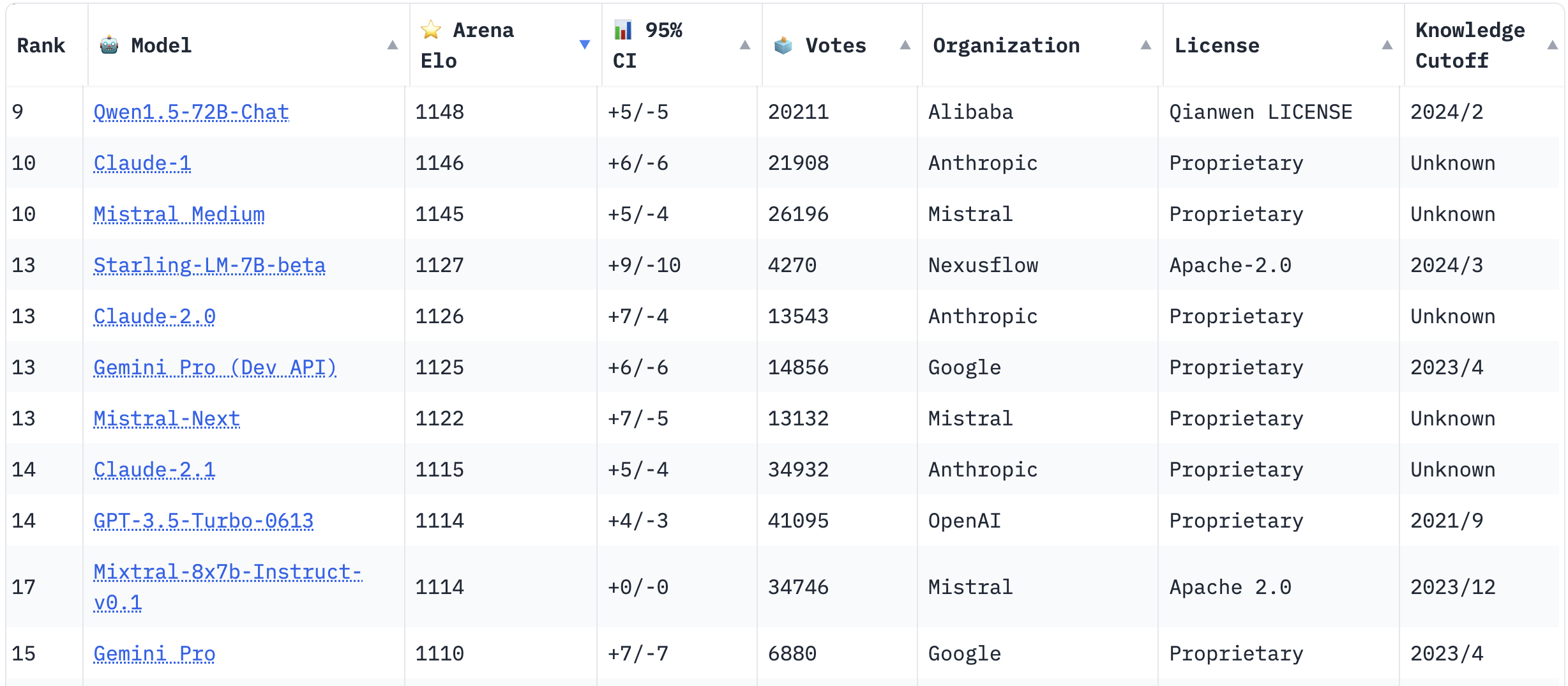
Os LLMs mais populares votados pela comunidade em março de 2024. Começando no índice 9 para mostrar o Mixtral na tabela [4].
Vamos exemplificar como os MOEs funcionam, falando especificamente sobre o Mixtral. Mixtral é um modelo de transformador somente para decodificador que agrupa um roteador (ou rede de portões) e 8 conjuntos de parâmetros diferentes (peritos). Para cada solicitação de entrada, o roteador da Mixtral seleciona dois especialistas em cada camada e token e combina suas saídas de forma aditiva. O treinamento acontece simultaneamente para a rede de roteadores e para os especialistas. Essa abordagem superou LLMs maiores, como LLama 70B (v1) e GPT 3.5 na maioria dos benchmarks. Além disso, a quantidade total de parâmetros é de 46,7 bilhões (8 especialistas) e usa apenas 12,9 bilhões (2 especialistas) por token durante a inferência. Isso significa um aumento de inferência x6 mais rápido em comparação com modelos individuais do mesmo tamanho.

Esquema representando a arquitetura MoE esparsa da Mixtral [5]
1.2 Expansão de blocos
Esse conceito é relativamente novo, embora existam várias abordagens semelhantes, como Adaptação de Baixo Nível (LoRa) e HyperNetworks para modelos LLMs e Diffusion. Alguns exemplos disso podem ser encontrados em nosso blog em Ensino de conceitos específicos de modelos de difusão. Para adicionar novos recursos a um modelo existente sem comprometer seu desempenho em tarefas já conhecidas, adicionamos iterativamente novos blocos de transformadores treinados nessas novas tarefas enquanto congelamos os blocos anteriores. A principal desvantagem dessa técnica é o aumento no consumo de memória do modelo e a maior latência durante a inferência.
2. Por que mesclar modelos?
Resposta curta: a fusão de modelos é fácil. Não há necessidade de ajustar ou adicionar novas camadas treináveis aos modelos selecionados. Além disso, há esforços da comunidade de código aberto para desenvolver ferramentas para facilitar essas tarefas, como a fusão de modelos. Isso facilita ainda mais a adoção dessas técnicas. Provavelmente, a biblioteca mais popular no momento para mesclagem de modelos é kit de fusão [6]. A fusão exige muitas tentativas e erros, mas não exige clusters ou laboratórios sofisticados para aproveitar um grande poder computacional. Até recentemente, não era possível mesclar modelos com arquiteturas ou tamanhos diferentes (por exemplo, Mistral e LLama v2). No entanto, essa abordagem está se tornando mais comum, especialmente com o lançamento de algumas fusões de francos, como SOLAR 10,7B e Golias 120B.
2.1 Tabelas de classificação do LLM
Além disso, vamos dar uma olhada no Tabela de classificação do Open-LLM, eliminando conjuntos de dados e modelos de bate-papo específicos.

Modelos com melhor desempenho no Tabela de classificação do Open-LLM.
Pode ser surpreendente ver que os modelos com melhor desempenho não parecem familiares. No entanto, esse fenômeno não acontece quando se olha para outras tabelas de classificação, como a Tabela de classificação do LMSYS Chatbot Arena. Isso se deve a dois motivos principais. Primeiro, a fusão de modelos e outros tipos de mesclagem, como FrankenMoes (mesclar modelos por meio da criação de MOEs), estão se tornando cada vez mais populares. Isso aumenta significativamente o número de modelos na tabela de classificação do Open LLM. Como podemos ver na última coluna da tabela, os modelos com melhor desempenho são todos mesclados até março de 2024. Além disso, como essas mesclagens podem melhorar o desempenho dos modelos em determinadas tarefas, elas podem ser ainda melhores do que os modelos usados como entrada para a fusão, daí as altas pontuações nos conjuntos de dados de avaliação. Em segundo lugar, algumas dessas mesclagens estão usando modelos que usaram dados do conjunto de testes de benchmarks de avaliação. Indiretamente, isso está fazendo com que eles tenham um desempenho incrivelmente alto nesses benchmarks, pois têm vazamento de informações. Isso não acontece na tabela de classificação do Chatbot Arena, pois os mantenedores selecionam quais modelos avaliar.
3. Métodos de mesclagem
Embora existam vários métodos para mesclar modelos, nos concentraremos em três das alternativas mais populares. Além disso, essa seleção escolhida a dedo foi feita para mostrar abordagens diferentes e não semelhantes, pois elas variam ligeiramente entre si (como interpolação linear e interpolação linear esférica). Os três métodos que descreveremos nesta seção são:
- Interpolação linear esférica (SLERP)
- Algoritmos vectoriais
- Fusão de Frankenstein (também conhecida como fusão ou passagem de Frankenstein)
Por outro lado, também existe a opção de fusão por meio da criação de um modelo MoE (também conhecido como FrankenMoes), combinando expertise para um melhor desempenho. No entanto, isso está fora do escopo deste blog.
3.1 DORMIR
Essa técnica consiste em combinar suavemente dois modelos navegando pelo caminho da costa em uma esfera de alta dimensão. Por uma questão de simplicidade, vamos considerar que estamos mesclando quatro vetores de peso com apenas duas posições, que mostraremos em um plano 2D para uma melhor visualização.
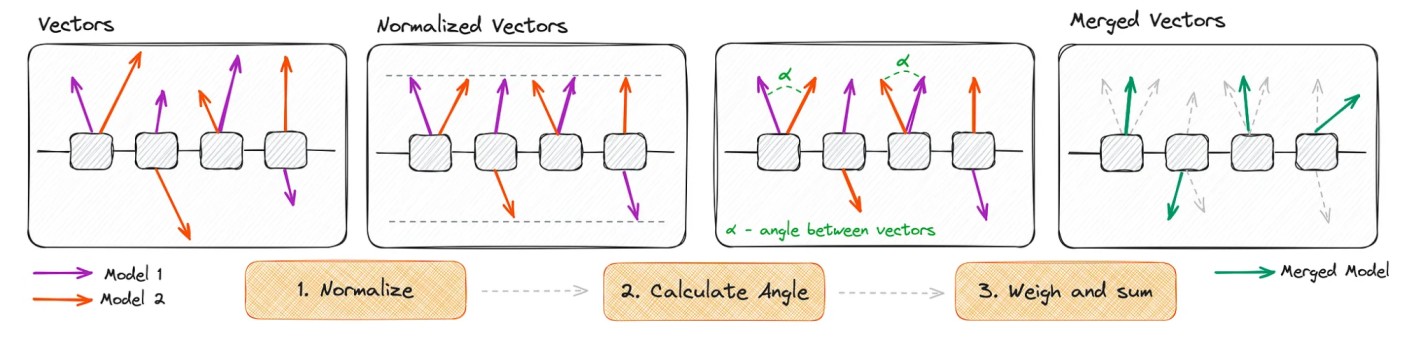
Ilustração esquemática do algoritmo SLERP [7]
As etapas envolvidas no SLERP são as seguintes:
- Normalização: normalizando os vetores para terem o mesmo comprimento.
- Cálculo do ângulo: calcule o ângulo (teta ou alfa) em radianos entre esses vetores.
- Novo cálculo vetorial: calcule o a, o novo vetor (v)1+2) seguindo a fórmula mostrada abaixo.
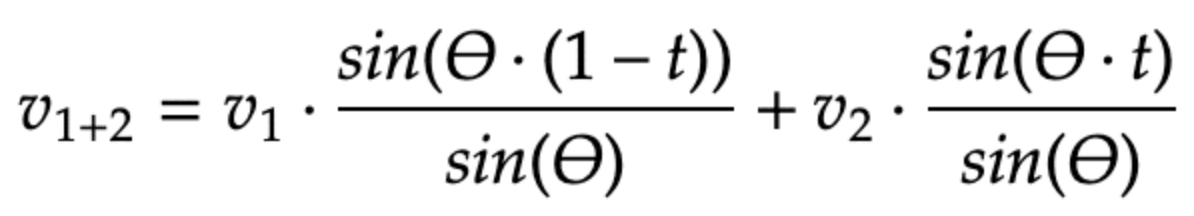
Fórmula para novo cálculo vetorial com o algoritmo SLERP [11]
Nesta fórmula, o parâmetro t ‣ [0, 1] refere-se a um peso aplicado para ambos os modelos. Quando t = 0, somente o Modelo 1 é usado e quando t = 1, somente o Modelo 2 é usado. O SLERP melhora a média de peso padrão mantendo as características e a curvatura exclusivas de cada modelo, mesmo em espaços complexos e de alta dimensão.
3.2 Algoritmos vetoriais de tarefas
Este método introduz um novo paradigma para modificar o comportamento das redes neurais usando vetores de tarefas. Esses vetores representam direções no espaço de peso de um modelo pré-treinado, apontando para um melhor desempenho em uma tarefa específica. Usando operações aritméticas como negação e adição, podemos manipular vetores, fazendo mudanças comportamentais no modelo. Essa ideia foi introduzida no artigo “Editando modelos com aritmética de tarefas” [8]. Os vetores de tarefas são calculados subtraindo os pesos de um modelo base dos pesos de um modelo específico de tarefa que foi ajustado com base no mesmo modelo base. Ao contrário do SLERP, podemos mesclar vários modelos ao mesmo tempo.
3.2.1 Operações vetoriais de tarefas
As operações mais comuns são as seguintes:
- Esquecendo por meio da negação: negar um vetor de tarefa diminui o desempenho do modelo na tarefa alvo, mantendo seu comportamento nas tarefas de controle. Isso pode ser especialmente útil para mitigar preconceitos ou nos casos em que queremos manter a privacidade dos dados (por exemplo, esquecer informações privadas memorizadas).
- Aprendizagem por adição: adicionar vetores de tarefas pode melhorar o desempenho do modelo em várias tarefas simultaneamente.
- Analogias de tarefas: combinar vetores de tarefas de tarefas relacionadas (com base em uma relação de analogia) pode melhorar o desempenho em uma quarta tarefa, mesmo sem usar dados dessa tarefa. Isso é conseguido usando analogias como: “A está para B, como C está para D”, onde A, B e C já são tarefas aprendidas e D é uma tarefa que não foi vista (ou quase não vista) durante o treinamento.

Esquema representando as operações aritméticas mais comuns em vetores de tarefas [7]
3.2.2 Algoritmos mais comuns
Existem quatro algoritmos principais de vetores de tarefas em kit de fusão [6]
- Aritmética de tarefas: que se concentra no cálculo de vetores de tarefas e na adição dos resultados aos pesos do modelo base. [9]
- GRAVATAS: foi projetado para mesclar com eficiência vários modelos específicos de tarefas em um único modelo multitarefa. Ele aborda a redundância nos parâmetros do modelo (ignorando pequenas mudanças de peso) e a discordância entre os sinais dos parâmetros. [10]
- OUSAR: é semelhante ao TIES, mas com duas diferenças principais: podar redefinindo aleatoriamente pesos ajustados para o modelo básico e redimensionar pesos. [10]
- OUSE MAIS DE 3 VEZES: combina a abordagem de redundância do TIES com o redimensionamento do DARE.
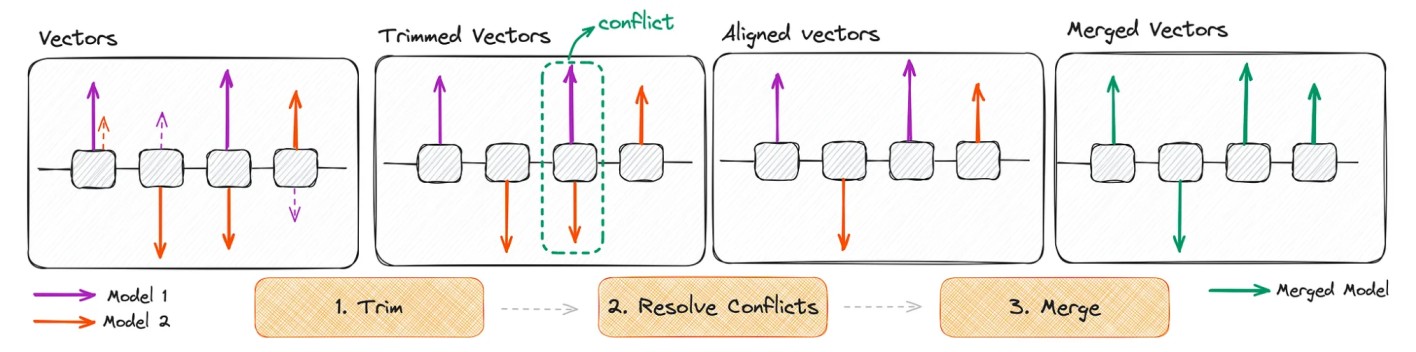
Ilustração esquemática do algoritmo TIES [7]
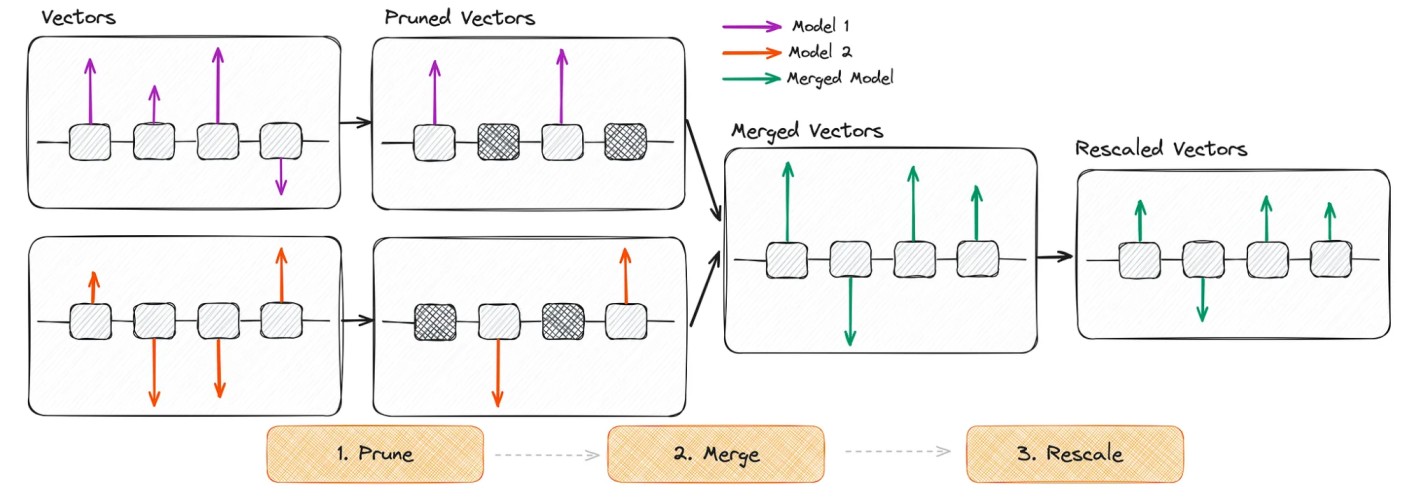
Ilustração esquemática do algoritmo DARE [7]
3.2.3 Comparação de algoritmos
Uma comparação rápida para orientar qual algoritmo de vetor de tarefas é mais adequado ao seu caso de uso é mostrada na tabela abaixo:
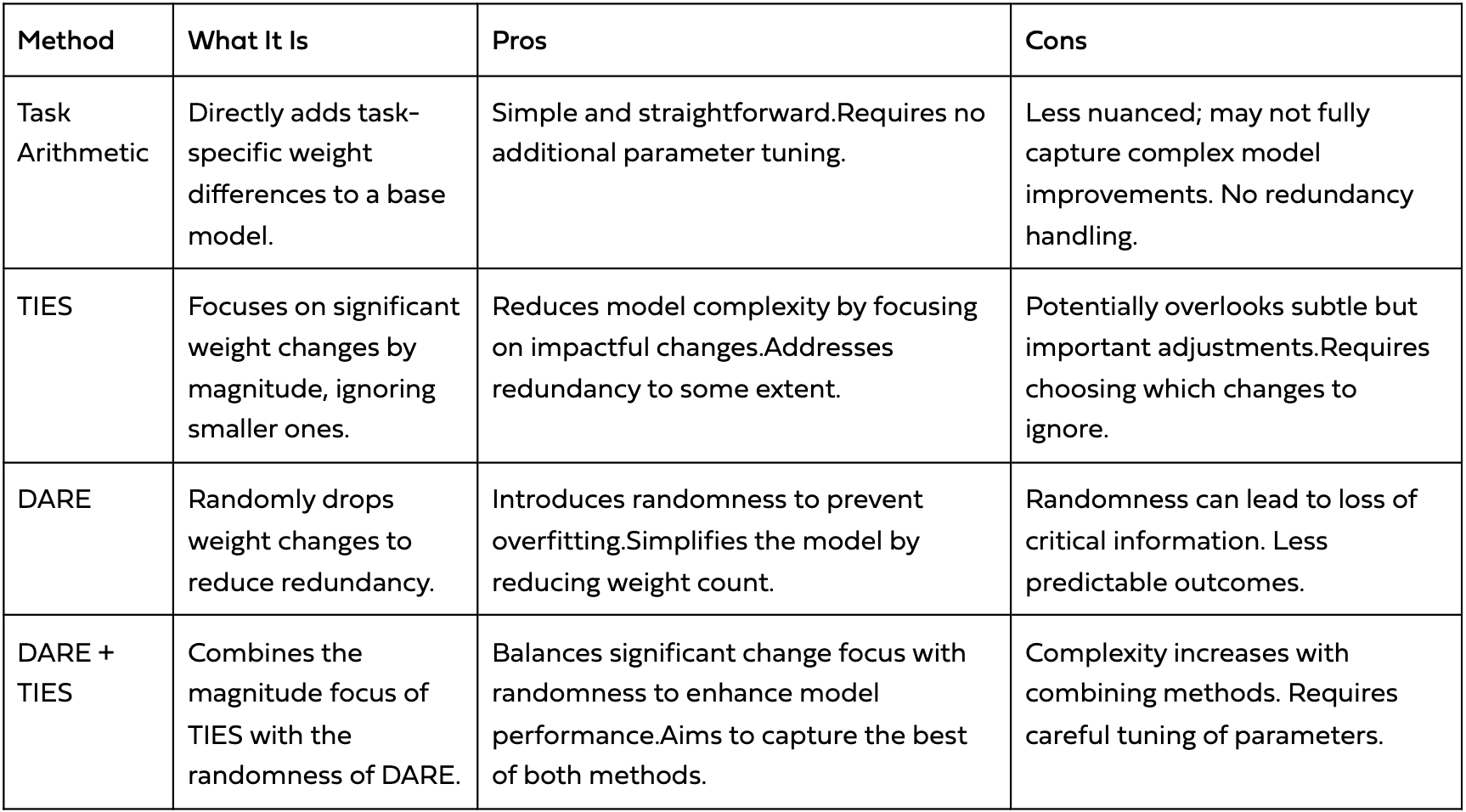
Comparação de prós e contras de diferentes algoritmos de vetores de tarefas [11]
3.3 Fusão de francos
Essa técnica envolve o processo de mesclar modelos diferentes misturando partes deles. Mais especificamente, empilhar diferentes camadas sequencialmente em vez de fundir camadas diferentes. Atualmente, esse é um dos dois métodos do mergekit que funciona para diferentes arquiteturas de modelo. Este método também pode ser encontrado como Pbunda ou Modelos Frankenstein. O outro método comum na comunidade é o FrankenMoes, que aplica essa ideia francamente emergente, mas usando a arquitetura MoE. Para obter mais informações sobre eles, consulte o Mlabonne/Beyonder-4x7B-v2 modelo que é um exemplo claro disso. O Frankenmerging pode produzir modelos com um número exótico de parâmetros (por exemplo, modelo 9B mesclado baseado em dois modelos 7B). Embora ainda seja uma técnica bastante experimental, a comunidade está obtendo resultados impressionantes com ela. Isso exige muitas tentativas e erros, pois não existe uma fórmula para obter a mesclagem ideal.
4. Mesclando seus próprios modelos
Nesta seção, forneceremos uma visão geral de como aproveitar o mergekit para criar seus próprios modelos mesclados. Esse processo consiste essencialmente em carregar um arquivo de configuração de mesclagem e executá-lo. Tão simples quanto parece. Neste blog, mostraremos como usar a fusão DARE-TIES usando diferentes modelos com foco em matemática da mesma família (Mistral 7B). Posteriormente, avaliaremos nosso modelo final no conjunto de dados GSM8K, que consiste em 8,5 mil problemas de palavras matemáticas de alta qualidade, linguisticamente diversos, criados por redatores de problemas humanos. A ideia é comparar os modelos individuais com nossa fusão.
4.1 Instalação
Para instalar o mergekit, basta instalar a biblioteca por meio de pip install ou instalar a partir da fonte git clone https://github.com/cg123/mergekit.git cd mergekit && pip install -q -e. Em seguida, devemos criar os arquivos de configuração para definir a mesclagem que queremos fazer.
4.2 DARE-TIES com mergekit
Para identificar quais modelos vêm da mesma árvore genealógica, Maxime Labonne criou essa ferramenta incrível: Árvore genealógica modelo. Porém, ao examinar os modelos de cartões no hub Hugging Face, geralmente é possível rastrear sua precedência. Nesta demonstração, estamos usando Mistralai/Mistral-7B-v0.1 como modelo básico e fundiremos dois modelos matemáticos da mesma família: Metamática/Metamath-Mistral-7b e WizardLM/WizardMath-7B-v1.1. Estamos definindo os seguintes modelos: - modelo: Mistralai/Mistral-7b-v0.1 # Nenhum parâmetro necessário para o modelo básico - modelo: wizardlm/wizardmath-7b-v1.1 parâmetros: densidade: 0,65 peso: 0,4 - modelo: meta-math/metamath-mistral-7b parâmetros: densidade: 0,6 peso: 0,3 merge_method: dare_ties base_model: Mistralai-7b /Mistral-7b-v0.1 parâmetros: int8_mask: true dtype: float16 Em seguida, para executar a mesclagem, execute o seguinte comando: mergekit-yaml config.yaml merge --copy-tokenizer --allow-crimes --out-shard-size 1B --lazy-unpickle A mesclagem levou cerca de 30 minutos para ser concluída em a instância de CPU no Google Colab. Isso depende da quantidade e do tamanho dos modelos a serem mesclados, entre outros fatores, como a diversidade de famílias de modelos. Nota: essas operações de mesclagem não requerem GPU (embora possam acelerar algumas operações). No entanto, pode ser necessário um alto teor de RAM. Então, para avaliação, precisaremos da GPU. Então, como uma etapa intermediária para trocar entre uma instância de alta RAM e uma de GPU do nível gratuito no Google Colab, você pode enviar seu modelo para o hub Hugging Face. O resultado dessa fusão pode ser encontrado no link a seguir: Nachoaristimuno/Mistralmath-7b-v0.1.
4.3 Avaliação
Agora é hora de avaliar nosso modelo no conjunto de dados GSM8K para comparar os resultados. Se estivéssemos usando uma instância de CPU para a mesclagem, seria necessário mudar para uma instância de GPU devido ao tamanho desses modelos. Primeiro, precisamos instalar o Arnês de avaliação LM biblioteca para facilitar o processo de avaliação. git clone https://github.com/EleutherAI/lm-evaluation-harness cd lm-evaluation-harness pip install -e. Em seguida, podemos executar o seguinte comando para avaliar nosso novo modelo: lm_eval --model hf --model_args pretrained=nachoaristimuno/mistralmath-7b-v0.1, load_in_8bit=True --tasks gsm8k --device cuda:0 --batch_size 2 Isso executará o benchmark de avaliação GSM8K usando GPU (cuda:0 --batch_size 2) :0) e um tamanho de lote de 2. Se o modelo não estiver disponível localmente, o comando o baixará diretamente do hub do Hugging Face se não for encontrado localmente. Além disso, o load_in_8bit=Verdadeiro foi definido porque o vRAM usado para esta avaliação não era suficiente para carregar o modelo no FP16. No entanto, se você tiver vRAM suficiente, poderá remover essa configuração.
4.4 Resultados
Os resultados dos três modelos são mostrados abaixo: Filtro de versão da tarefa - valores métricos curtos Tderr gsm8k 3 correspondência estrita 5 correspondência exata 0,7015 ± 0,0146 gsm8k 3 extrato flexível 5 correspondência exata 0,7028 ± 0,0126
Tabela de resultados para a mesclagem de modelos (Nachoaristimuno/Mistralmath-7b-v0.1)
Filtro de versão da tarefa - valores métricos curtos Tderr gsm8k 3 correspondência estrita 5 correspondência exata 0,7369 ± 0,0121 gsm8k 3 extrato flexível 5 correspondência exata 0,4996 ± 0,0075
Tabela de resultados para o WizardLM/WizardMath-7B-v1.1 modelo
Filtro de versão da tarefa - valores métricos curtos Tderr gsm8k 3 correspondência estrita 5 correspondência exata 0,5912 ± 0,0106 gsm8k 3 extrato flexível 5 correspondência exata 0,5768 ± 0,0097
Tabela de resultados para o Metamática/Metamath-Mistral-7b modelo
Em geral, na avaliação de correspondência estrita, os modelos WizardMath ainda têm um desempenho melhor do que a mesclagem, e a mesclagem tem um desempenho melhor do que o modelo MetaMath. No entanto, no caso da extração flexível, a mesclagem de modelos supera os dois modelos. Nesse caso, o WizardMath ainda é um dos modelos com melhor desempenho no benchmark GSM8K, daí a dificuldade de superar seu desempenho. No entanto, nossa fusão de modelos é capaz de funcionar de forma mais consistente em métricas rígidas e flexíveis.
5. Conclusões
A fusão de modelos está ganhando muita atenção, pois se torna uma maneira barata e relativamente fácil de criar um modelo capaz de realizar diferentes tarefas, aproveitando modelos já treinados. Geralmente, essas técnicas envolvem cálculos sem a necessidade de GPU. Ao aproveitar algumas ferramentas de código aberto, como Kit de mesclagem, o processo de experimentar diferentes combinações de modelos se torna mais fácil. Apenas procurando modelos que possam ser úteis para nossa tarefa e definir um arquivo de configuração de mesclagem, pode levar menos de uma hora para testar novos modelos. Em nosso caso de exemplo, conseguimos criar uma nova mesclagem de modelos usando dois modelos ajustados em conjuntos de dados matemáticos. Ao fazer isso, nosso novo modelo supera um dos modelos em métricas exatas e flexíveis e o outro na métrica de extração flexível, mas ainda está um pouco atrasado na métrica de correspondência estrita. Uma intuição que obtivemos ao testar diferentes mesclagens de modelos é que essas técnicas se tornam especificamente úteis quando queremos permitir que um modelo aprenda duas tarefas diferentes a partir de dois modelos ajustados. No entanto, ainda pode ser útil ao mesclar modelos ajustados na mesma tarefa. Essas formas de criar novos modelos a partir de modelos que já funcionam definitivamente se tornarão mais comuns em 2024. Alinhado com isso, o FrankenMoes provavelmente se tornará uma tendência devido à popularidade dos MOEs na comunidade e ao lançamento de diferentes modelos que se destacam em tarefas específicas. Por último, mas não menos importante, exploramos a aplicação da fusão de modelos no contexto dos LLMs. No entanto, esses mesmos conceitos também podem ser aplicados a outros grupos de modelos, como modelos de difusão na geração de imagens.
6. Referências
- Fusão de modelos: expandindo as habilidades dos LLMs em qualquer lugar
- Transformadores de switch: escalando para trilhões de modelos de parâmetros com dispersão simples e eficiente
- Blog de uma mistura de especialistas
- Arena de bate-papo da LMSys
- Mistura de artigos de especialistas
- Repositório Mergekit
- Editando modelos com aritmética de tarefas
- Mesclar modelos de linguagem grandes
- Papel TIES
- Papel DARE
- Fusão de modelos: MoE, Frankenmerging, SLERP e algoritmos vetoriais de tarefas
- Combine modelos de linguagem grandes com o mergekit



.png)